





原标题:Python爬取豆瓣电影的短评数据并进行词云分析处理

前言
对于爬虫很不陌生,而爬虫最为经典的案例就是爬取豆瓣上面的电影数据了,今天小编就介绍一下如果爬取豆瓣上面电影影评,以《我不是药神》为例。
基本环境配置
版本:Python3.6
系统:Windows
本人对于Python学习创建了一个小小的学习圈子,为各位提供了一个平台,大家一起来讨论学习Python。欢迎各位到来Python学习群:960410445一起讨论视频分享学习。Python是未来的发展方向,正在挑战我们的分析能力及对世界的认知方式,因此,我们与时俱进,迎接变化,并不断的成长,掌握Python核心技术,才是掌握真正的价值所在。
相关模块:
(1)requests:用来简单数据请求。
(2)lxml:比BeautiSoup更快更强的解析库。
(3)pandas:数据处理神器。
(4)time:设置爬虫访问间隔。
(5)random:生成随机数,配合time使用。
(6)tqdm:显示程序运行进度。
以上模块如果你没有安装可以在cmd命令提示符里进行pip install + 模块名 进行安装。
主要思路步骤
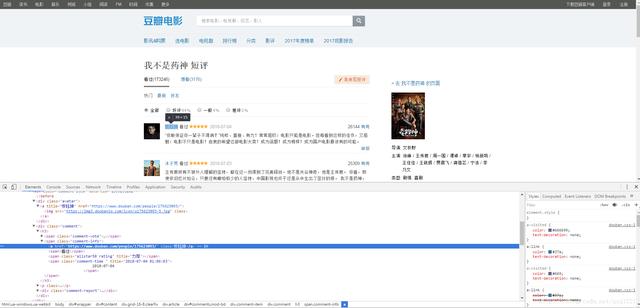
1、打开豆瓣电影《我不是药神》的短评网页,右键检查或者按F12,然后选择用户名和评论就会显示出对应的代码部分
 正在上传...
正在上传...
取消
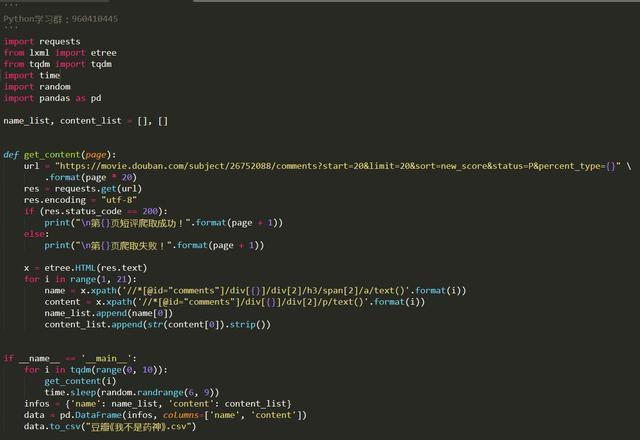
2、通过requests模块发送一个get请求,并以utf-8重新编码;
3、添加一个交互,判断是否成功获取到资源(状态码为200),输出获取状态。
对于爬取下来《我不是药神》的短评内容,我们用lxml来进行解析。在步骤1中找到对应部分的代码,然后右键选择Copy,再选择Copy XPath,就能获取其路径了。
注意:
爬取下来的短评首尾可能有多余的空格,我们就需要使用字符串中的strip()方法来去掉这些多余的空格。
4、获取到数据之后,我们通过list构造dictionary,然后通过dictionary构造dataframe,并通过pandas模块将数据输出为csv文件
实现代码
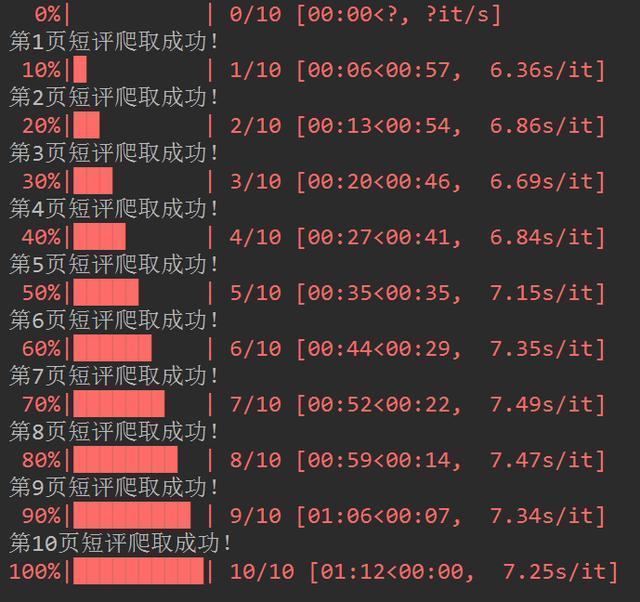
运行结果
 正在上传...
正在上传...
取消
当然了,如果你想要用这些数据做成词云图,进行数据展示也是可以的。
词云实现代码
责任编辑:















 1568
1568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









