







 超级会员免费看
超级会员免费看
🍉 博主微信
cvxiayixiao
🍓 【Segment Anything Model】计算机视觉检测分割任务专栏。 链接
🍑 【公开数据集预处理】特别是医疗公开数据集的接受和预处理,提供代码讲解。链接
🍈 【opencv+图像处理】opencv代码库讲解,结合图像处理知识,不仅仅是调库。链接
1️⃣预备知识
🌸分类基础知识
先介绍sigmoid 和 softmax两个激活函数,是实现分类的基础。
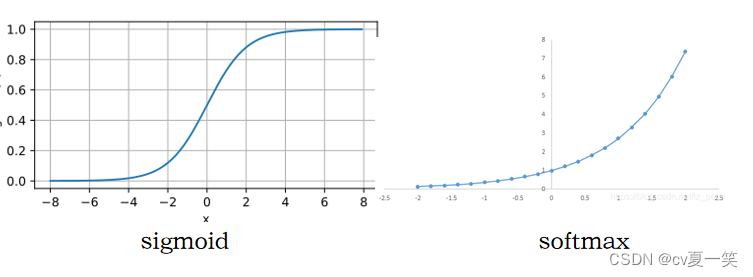
sigmoid用于二分类,预测的是当前像素点得分,如果大于0.5的,就可以认为有统计学意义就可以认为是True。
softmax用于多分类,预测的是当前像素属于几个类别各自的概率。
softmax 案例:
假如模型对一个三分类问题的预测结果为-
 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











