






之前第二三篇有更新过单点,多点,单框。本篇加上多框输入。
先确定一下目录
新建test_boxes.py文件,复制以下代码
import sys
import torch
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
from Net.segment_anything import SamPredictor,sam_model_registry
import cv2
image = cv2.imread('1.jpg') # 读取的图像以NumPy数组的形式存储在变量image中
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 将图像从BGR颜色空间转换为RGB颜色空间,还原图片色彩(图像处理库所认同的格式)
model_type = "vit_b" # 定义模型类型
device = "cuda" # "cpu" or "cuda"
sam = sam_model_registry[model_type](checkpoint='sam_vit_b_01ec64.pth')
sam.to(device=device) # 定义模型参数
predictor = SamPredictor(sam) # 调用预测模型
predictor.set_image(image)
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
# 多框
# input_boxes = torch.tensor([
# [75, 275, 1725, 850],
# [425, 600, 700, 875],
# [1375, 550, 1650, 800],
# [1240, 675, 1400, 750],
# ], device=predictor.device) # 假设为目标检测的预测结果
# 单框
input_boxes = torch.tensor([
[75, 275, 1725, 850]
], device=predictor.device) # 假设为目标检测的预测结果
input_boxes = input_boxes / 2
transformed_boxes = predictor.transform.apply_boxes_torch(input_boxes, image.shape[:2])
masks, _, _ = predictor.predict_torch(
point_coords=None,
point_labels=None,
boxes=transformed_boxes,
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
for mask in masks:
show_mask(mask.cpu().numpy(), plt.gca(), random_color=True)
for box in input_boxes:
show_box(box.cpu().numpy(), plt.gca())
plt.axis('off')
plt.show()
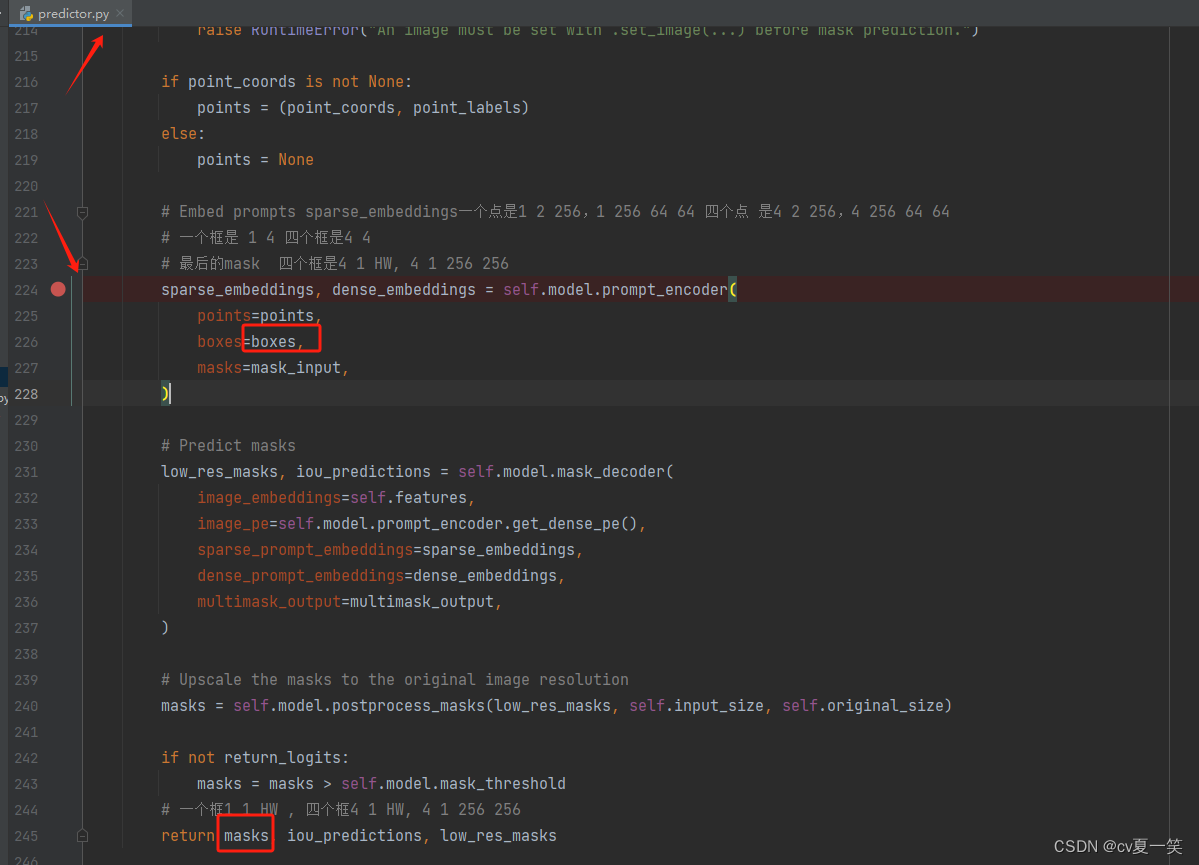
打断点
在如下位置打断点,debug运行,观察单框和多框传入有什么维度不同,自己训练的时候按照对应维度组装。















 6583
6583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









