









今天给大家分享的案例是小红书的文案抓取与评论内容抓取,小红书在我们日常生活中时常出现,其中有许多博主在上面分享自己的日常、烹饪教学、游戏日常、旅游日记等。同时,我们还可以抓取某个文案中的评论数据,可以通过这些数据对这个文案进行数据分析。事不宜迟,让我们开始今天的RPA案例的分享。
1.登录操作
为确保数据采集顺利进行,登录操作是首要步骤。若未登录,系统会频繁弹出登录提示,干扰数据抓取流程。
在实施登录前,需先检查当前登录状态。可通过检测页面中的登录按钮元素来判断:若该元素存在,表明账号尚未登录,此时才需执行登录操作;反之则无需重复登录。
这种预检机制能有效避免不必要的登录操作,提升爬取效率。
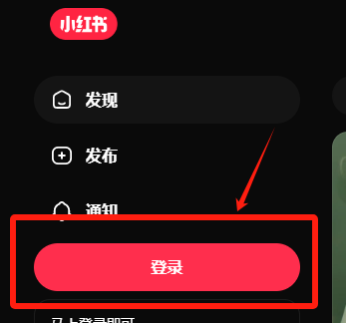
点击登录按钮后,系统将弹出登录对话框。只需抓取以下元素即可实现自动化构建:账号输入框、验证码发送按钮、验证码输入框以及登录按钮。

为简化登录流程,采用对话框形式进行验证码交互。用户需在对话框中输入验证码,验证通过后方可继续后续操作。
2.文案抓取
这次抓取的文案是有关游戏的,因此需要点到游戏模块再进行数据的抓取,可以通过点击主页中的游戏模块的元素就能切换到有关游戏文案的页面了
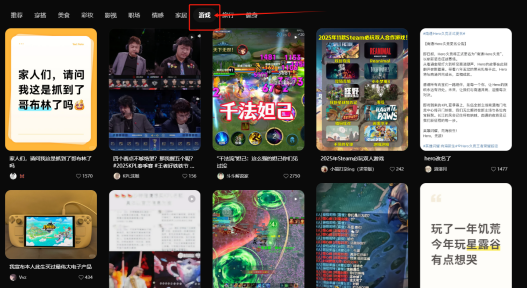
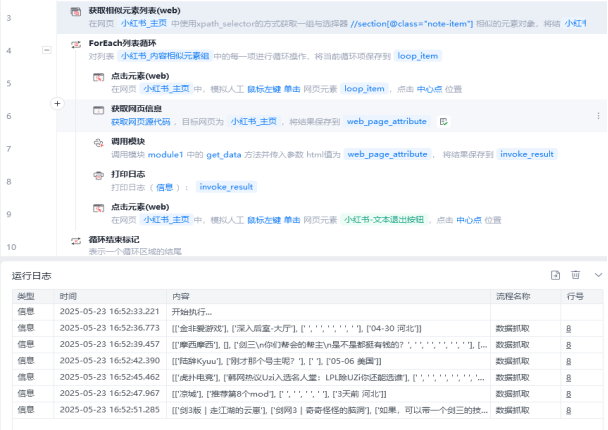
然后通过xpath语法定位相似元素组,获取所有文案的元素对象
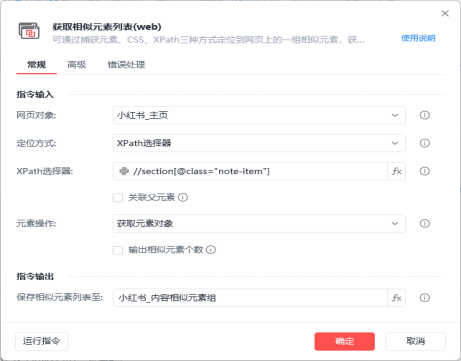
点击相似元素组循环选项,选择对应文案进入详情页后,即可获取相关元素信息,包括用户名、文案内容和发布时间等数据。
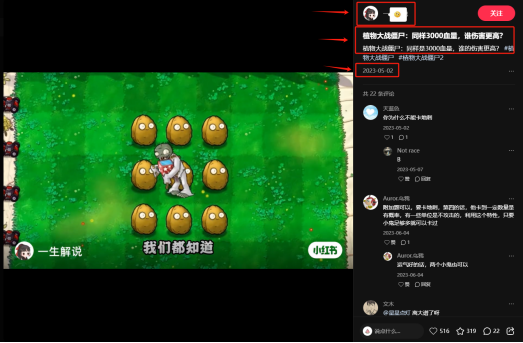
抓取到的数据可以保存到数据表格中,后续可以用于数据分析或者导出数据
3.评论内容爬取
评论内容需要在文案详细页面里面才能获取到,所以第一步就是先打开一个需要抓取评论的文案
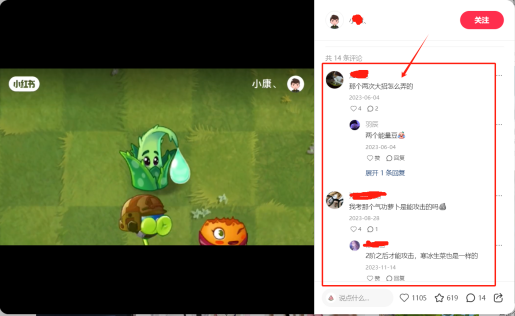
评论数据采用动态加载方式,需要持续滚动评论区以获取新内容。当滚动至末尾出现"The End"元素时,即可判定数据加载完毕,此时可中止滚动操作并执行后续的数据抓取步骤。

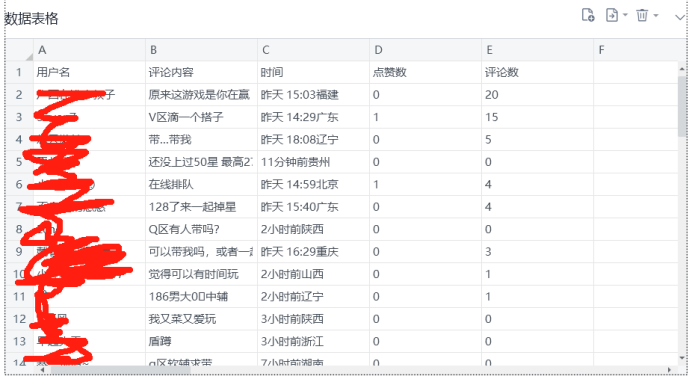
评论数据都加载完成后,就可以通过获取相似元素指令来获取所有的评论数据,可以获取到评论用户的用户名、评论内容、评论时间、点赞数、评论数等信息

最后,将爬取到的评论数据保存到数据表格中,方便后续数据分析或者导出数据。
4.总结:
本次实战案例重点分享了爬取小红书数据的具体流程。我们运用了爬虫必备的xpath语法进行数据抓取,同时结合RPA的相似元素组捕获功能。在页面滚动处理方面,采用了无限循环配合元素判断终止循环的技术方案。希望这个案例能为你的RPA学习之路带来启发。
最后,如果您喜欢这篇文章,欢迎点赞关注。我会持续分享各种RPA自动化案例,助力大家在学习的道路上不断精进。

















 84
84

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









