






目录
2.5.6.通配符与正则表达式查询(wildcard/regexp)
2.5.11.multi_match query 多字段匹配查询
QueryBuilders、NativeSearchQuery
1.初识elasticsearch
1.1.了解ES
1.1.1.elasticsearch的作用
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
例如:
在GitHub搜索代码
 在电商网站搜索商品
在电商网站搜索商品

在百度搜索答案

1.1.2.ELK技术栈
ELK技术栈简介
ELK其实并不是一款软件,而是一整套解决方案,是三个软件产品的首字母缩写,Elasticsearch,Logstash 和 Kibana。这三款软件都是开源软件,通常是配合使用,而且又先后归于 Elastic.co 公司名下,故被简称为ELK技术栈。
-
Elasticsearch:Elasticsearch是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎,使用Java语言编写。
-
Kibana(发音为/kiːˈbɑːnə/):Kibana是一个免费且开放的用户界面,能够让您对Elasticsearch数据进行可视化。Kibana是一款基于Apache开源协议的可视化Web管理平台。它可以在Elasticsearch的索引中查找,交互数据,并生成各种维度的表图。
-
Logstash:Logstash 是具有实时流水线能力的开源的数据收集引擎,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。使用JRuby语言编写。其作者是世界著名的运维工程师乔丹西塞 (JordanSissel)

Elasticsearch能实现什么
-
分布式的搜索引擎 分布式:Elasticsearch自动将海量数据分散到多台服务器上去存储和检索 搜索:百度、谷歌,站内搜索
-
全文检索 提供模糊搜索等自动度很高的查询方式,并进行相关性排名,高亮等功能
-
数据分析引擎(分组聚合) 电商网站,最近一周笔记本电脑这种商品销量排名top10的商家有哪些?新闻网站,最近1个月访 问量排名top3的新闻板块是哪些
-
对海量数据进行近实时的处理 海量数据的处理:因为是分布式架构,Elasticsearch可以采用大量的服务器去存储和检索数据,自 然而然就可以实现海量数据的处理 近实时:Elasticsearch可以实现秒级别的数据搜索和分析
Elasticsearch特点
-
安装方便:
-
没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群
JSON:输入/输出格式为 JSON,快捷方便
-
RESTful:基本所有操作 ( 索引、查询、甚至是配置 ) 都可以通过 HTTP 接口进行
-
分布式:节点对外表现对等(每个节点都可以用来做入口) 加入节点自动负载均衡
-
多租户:
可根据不同的用途分索引,可以同时操作多个索引,支持超大数据: 可以扩展到 PB 级(数据量超出万亿级别的信息)的结构化和非结构化数据 海量数据的近实时处理
1.1.3.elasticsearch和lucene
elasticsearch底层是基于lucene来实现的。
Lucene是一个Java语言的搜索引擎类库,是Apache公司的顶级项目,由DougCutting于1999年研发。官网地址:Apache Lucene - Welcome to Apache Lucene 。

elasticsearch的发展历史:
-
2004年Shay Banon基于Lucene开发了Compass
-
2010年Shay Banon 重写了Compass,取名为Elasticsearch。

1.1.5.总结
什么是elasticsearch?
-
一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
-
是以elasticsearch为核心的技术栈,包括Logstash、kibana、elasticsearch
什么是Lucene?
-
是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
1.2.倒排索引
倒排索引的概念是基于MySQL这样的正向索引而言的。
1.2.1.正向索引
那么什么是正向索引呢?例如给下表(tb_goods)中的id创建索引:

如果是根据id查询,那么直接走索引,查询速度非常快。
但如果是基于title做模糊查询,只能是逐行扫描数据,流程如下:
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
逐行扫描,也就是全表扫描,随着数据量增加,其查询效率也会越来越低。当数据量达到数百万时,就是一场灾难。
1.2.2.倒排索引
倒排索引中有两个非常重要的概念:
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
-
将每一个文档的数据利用算法分词,得到一个个词条
-
创建表,每行数据包括词条、词条所在文档id、位置等信息
-
因为词条唯一性,可以给词条创建索引,例如hash表结构索引
如图:

倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
如图: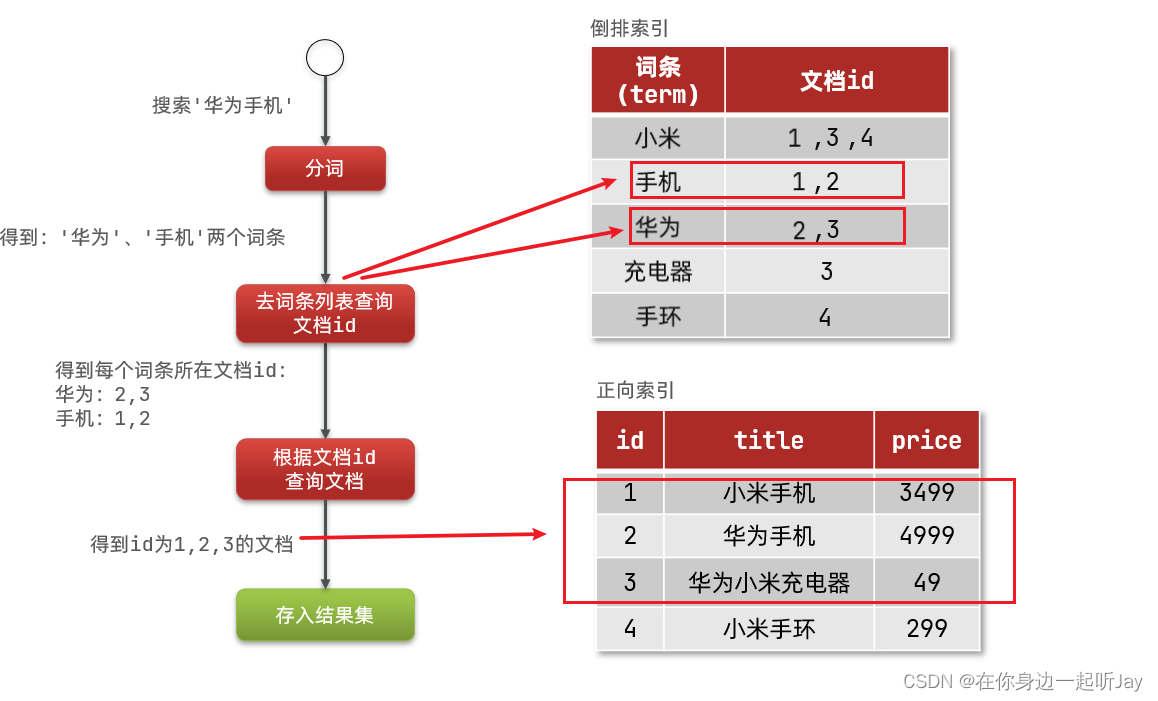
虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
1.2.3.正向和倒排
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
-
正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
-
而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
-
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
-
-
缺点:
-
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
-
倒排索引:
-
优点:
-
根据词条搜索、模糊搜索时,速度非常快
-
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
-
1.3.es的一些概念
elasticsearch中有很多独有的概念,与mysql中略有差别,但也有相似之处。
1.3.1.文档和字段
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
1.3.2.索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
-
所有用户文档,就可以组织在一起,称为用户的索引;
-
所有商品的文档,可以组织在一起,称为商品的索引;
-
所有订单的文档,可以组织在一起,称为订单的索引;

因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
1.3.3.mysql与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长支出:
-
Mysql:擅长事务类型操作,可以确保数据的安全和一致性
-
Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
-
对安全性要求较高的写操作,使用mysql实现
-
对查询性能要求较高的搜索需求,使用elasticsearch实现
-
两者再基于某种方式,实现数据的同步,保证一致性
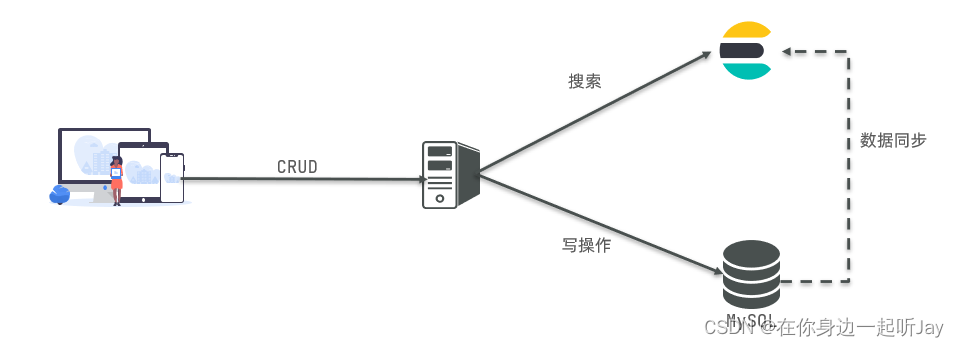
1.4.1.安装
请参考:ES的安装以及使用-CSDN博客
1.4.2.分词器
请参考:ES的安装以及使用-CSDN博客
1.4.3.总结
以"我爱你中国"为例, 默认的分词器会直接分为 "我" "爱" "你" "中" "国" 。
IK分词器 ik_smart算法
ik_smart算法会将"我爱你中国"分为 "我爱你" "中国"。
IK分词器ik_max_word算法
ik_max_word算法会将"我爱你中国"分为 "我爱你" "爱你" "中国"。
// 查看分词器 默认方式 直接复制到控制台执行查看结果
POST /_analyze
{
"text": "我爱你中国"
}
// 查看分词器 智能切分 直接复制到控制台执行查看结果
POST /_analyze
{
"tokenizer": "ik_smart",
"text": "我爱你中国"
}
// 查看分词器 最细切分 直接复制到控制台执行查看结果
POST /_analyze
{
"tokenizer": "ik_max_word",
"text": "我爱你中国"
}
分词器的作用是什么?
-
创建倒排索引时对文档分词
-
用户搜索时,对输入的内容分词
IK分词器有几种模式?
-
ik_smart:智能切分,粗粒度
-
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
-
利用config目录的IkAnalyzer.cfg.xml文件添加拓展词典和停用词典
-
在词典中添加拓展词条或者停用词条
常用Elasticsearch管理操作
1. 查看健康状态
命令:其中v代表参数,表示返回的结果包含标题头。
GET /_cat/health?v结果含义如下:
| 含义 | 表头 | 数据 |
|---|---|---|
| 编号 | epoch | 1640140938 |
| 时间戳 | timestamp | 02:42:18 |
| 集群名称 | cluster | docker-cluster |
| 健康状态 | status | green |
| 节点总数 | node.total | 1 |
| 数据节点数 | node.data | 1 |
| 总分片数 | shards | 5 |
| 主分片数量 | pri | 5 |
| 备份分片数量 | relo | 0 |
| 正在初始化的分片 | init | 0 |
| 未分配的分片 | unassign | 0 |
| 正在等待执行的任务 | pending_tasks | 0 |
| 挂起任务的等待时间 | max_task_wait_time | - |
| 活动的分片的占有百分比 | active_shards_percent | 100.0% |
1.1 健康状态含义说明
status值包括:green、yellow、red
-
green:每个索引的primary shard和replica shard都是active的。
-
yellow:每个索引的primary shard都是active的,但部分的replica shard不是active的。
-
red:不是所有的索引的primary shard都是active状态的。
2. 查看节点信息
命令:其中v代表参数,表示返回的结果包含标题头。
GET /_cat/nodes?v结果含义如下:
| 含义 | 表头 | 数据 |
|---|---|---|
| ES主机地址 | ip | 172.17.0.5 |
| 堆占用率 | heap.percent | 13 |
| 内存占用率 | ram.percent | 96 |
| CPU占用率 | cpu | 2 |
| 每分钟平均运行命令 | load_1m | 0.46 |
| 每5分钟平均运行命令 | load_5m | 0.21 |
| 每15分钟平均运行命令 | load_15m | 0.20 |
| ES节点权限 | node.role | dilm |
| 是否是主节点 | master | * |
| ES节点名称 | name | dd99a098c1f0 |
3. 查看Elasticsearch中的全部索引
命令:
GET /_cat/indices?v结果含义如下:
| 含义 | 表头 | 数据 |
|---|---|---|
| 健康状态 | health | green |
| 索引是否可用 | status | open |
| 索引名称 | index | .kibana_1 |
| 索引唯一键 | uuid | 3opvkLJPQdaDCYuEBGZFRA |
| 主分片数量 | pri | 1 |
| 副本分片数量 | rep | 0 |
| 索引中文档总数 | docs.count | 16 |
| 索引中已删除文档数 | docs.deleted | 0 |
| 索引总计占用空间 | store.size | 23kb |
| 索引主分片占用空间 | pri.store.size | 23kb |
2.索引库操作
索引库就类似数据库表,mapping映射就类似表的结构。
我们要向es中存储数据,必须先创建“库”和“表”。
2.1.DSL操作ES-RESTful风格
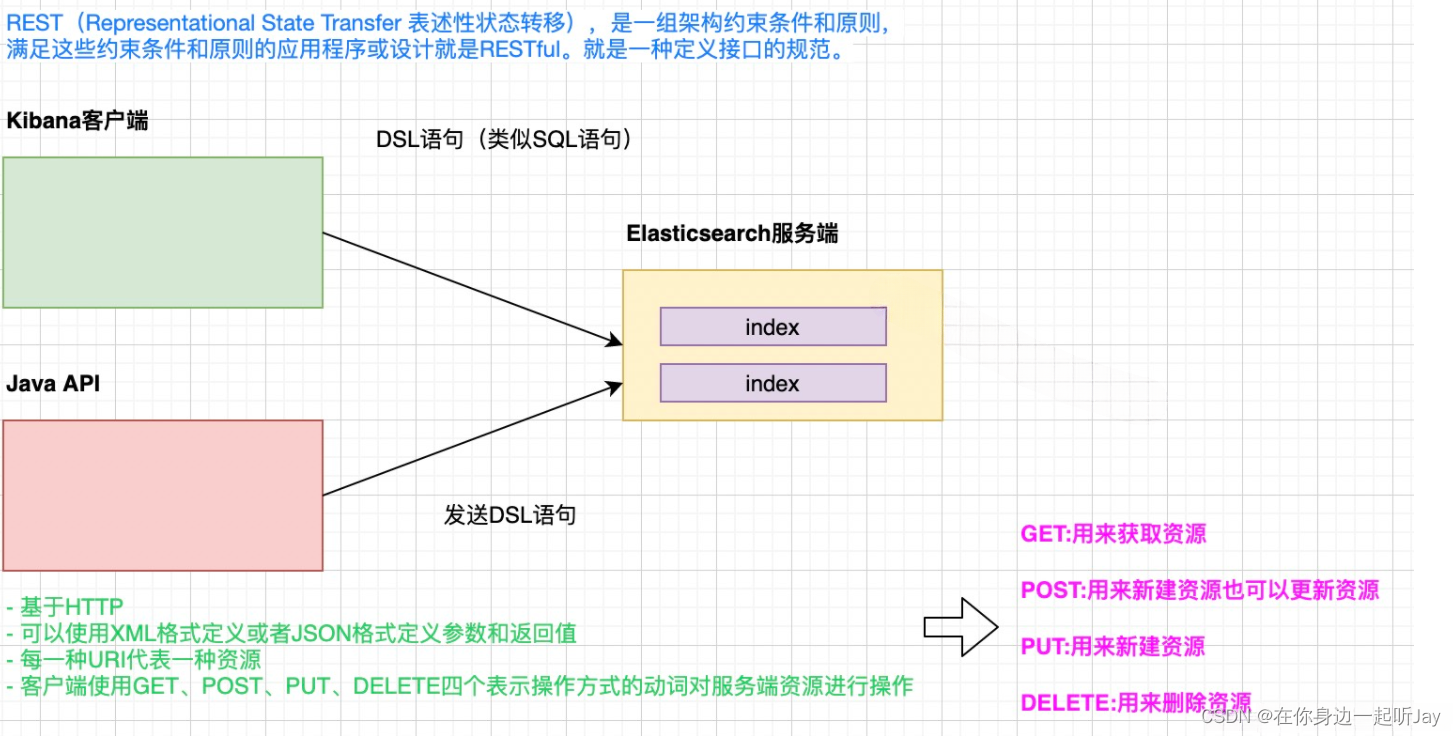
2.2.DSL操作索引库
# 新增索引库语法
PUT 索引库名
# 查询索引库
GET 索引库名
# 删除索引库
DELETE 索引库名
# 关闭索引库(注意:关闭索引库不能更改数据)
POST 索引库名/_close
# 开放索引库
POST 索引库名/_open
# settings 参数
1.number_of_shards:分片数量,类似于数据库里面分库分表,一经定义不可更改。主要响应写操作
2.number_of_replicas:副本数,用于备份分片的,和分片里面的数据保持一致,主要响应读操作,副本越多读取就越快。
3.分布式索引一定要注意分片数量不能更改,所以在创建的时候一定要预先估算好数据大小,一般在8CPU16G的机器上一个分片不要超过300g。索引会根据分片的配置来均匀的响应用户请求
4.如果调整了分片数那就要重建索引。
如下:
PUT /test
{
"settings" : {
"number_of_shards" : 1, //分片
"number_of_replicas" : 1 //分片副本
}
}2.2.1 PUT 添加索引
添加索引
PUT index
2.2.2 GET 查询索引
查询索引
GET index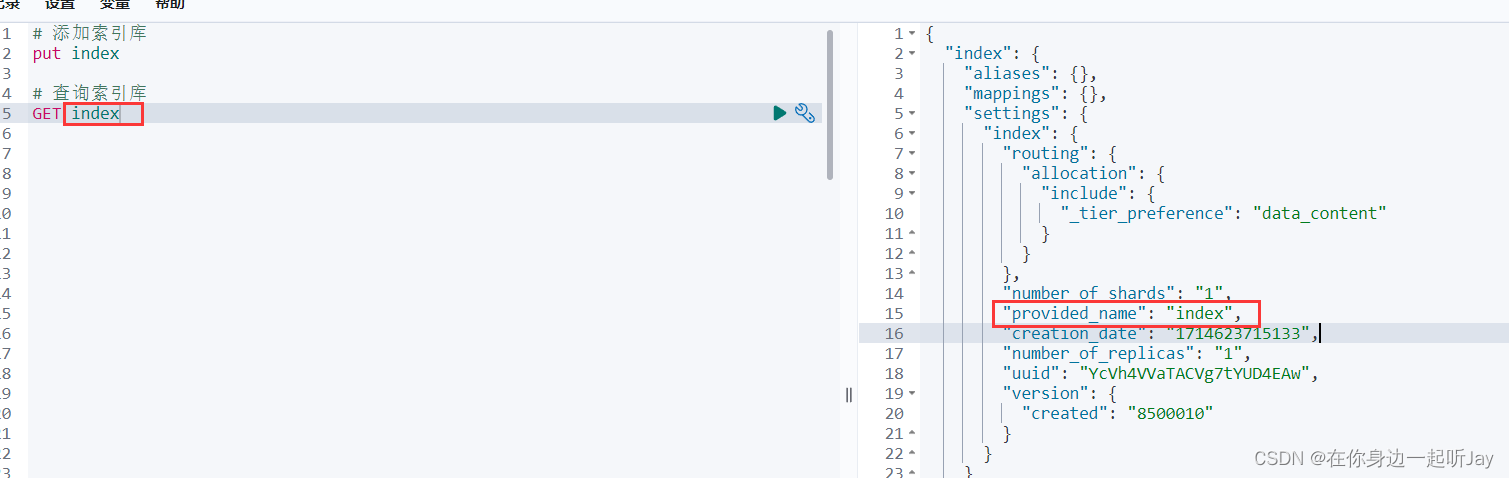
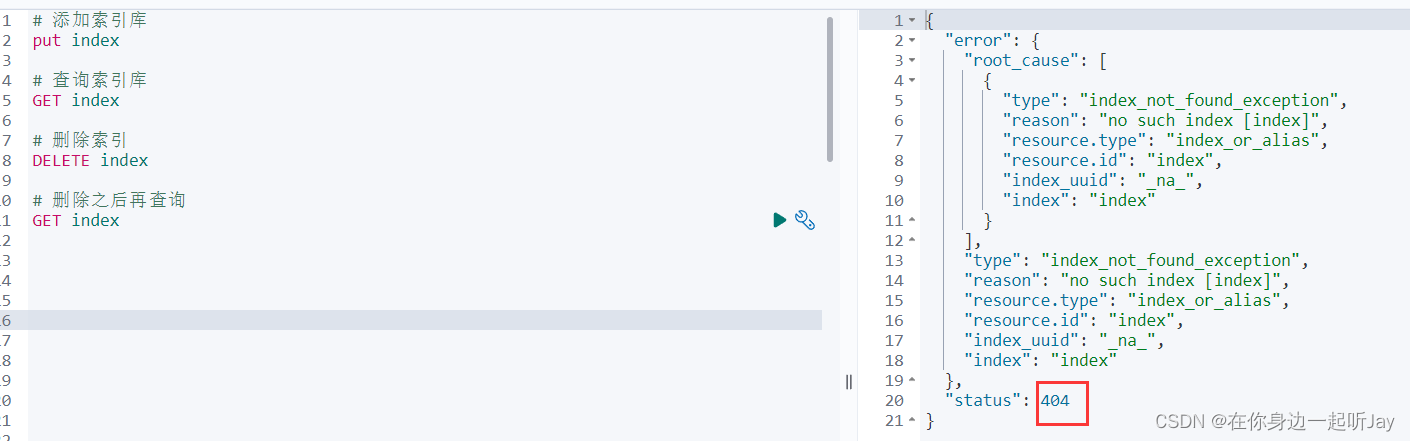
2.2.3 DELETE 删除索引
删除索引
DELETE index
删除之后再看的话就是404
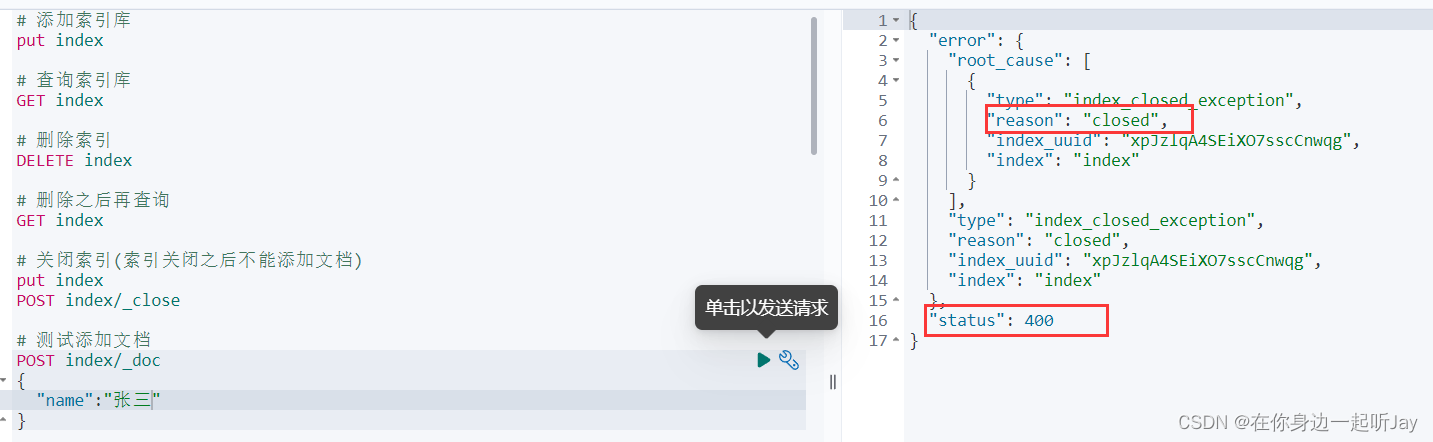
2.2.4 POST 打开/关闭索引库
关闭索引库
POST index/_close
注:当索引进入关闭状态,是不能添加文档的
打开索引库
POST index/_open
2.3.DSL操作映射
ES 中的 Mapping 相当于传统数据库中的表定义,它有以下作用:
-
定义索引中的字段的名字。
-
定义索引中的字段的类型,比如字符串,数字等。
-
定义索引中的字段是否建立倒排索引。
一个 Mapping 是针对一个索引中的 Type 定义的:
-
ES 中的文档都存储在索引的 Type 中
-
在 ES 7.0 之前,一个索引可以有多个 Type,所以一个索引可拥有多个 Mapping
-
在 ES 7.0 之后,一个索引只能有一个 Type,所以一个索引只对应一个 Mapping
通过下面语法可以获取一个索引的 Mapping 信息:
GET index/_mapping2.3.1.mapping映射属性
Mapping在Elasticsearch中是非常重要的一个概念。决定了一个index中的field使用什么数据格式存储,使用什么分词器解析,是否有子字段等。
一旦映射已确定,不可修改。field数据格式不可变,选择的分词器不可变,是否创建索引不可变。可以新增新的field映射。
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
-
数值:long、integer、short、byte、double、float、
-
布尔:boolean
-
日期:date
-
对象:object
-
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
Elasticsearch中的数据类型
Elasticsearch中的数据类型有很多,在这里只介绍常用的数据类型。只有text类型才能被分词。其他类型不能分词。
字符串-text:可以分词,不支持聚合(统计)
分词的数据,内容较为复杂,统计没有意义
字符串-keyword:不会分词,将全部内容作为一个词条,支持聚合(统计)
例如:有个文档(相当于数据库一条数据),其中一个字段的值是华为手机
text: 华为、手机
keyword: 华为手机
| 类型 | 类型名称 |
|---|---|
| 文本(字符串) | text |
| 整数 | byte、short、integer、long |
| 浮点型 | float、double |
| 布尔类型 | boolean |
| 日期类型 | date |
| 数组类型 | array {a:[]} |
| 对象类型 | object {a:{}} |
| 不分词的字符串(关键字) | keyword |
| 地理位置坐标值 | geo_point |

例如下面的json文档
{
"age": 19,
"weight": 52.1,
"isMarried": false,
"info": "Java讲师",
"email": "1234567@qq.com",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "弈",
"lastName": "星"
}
}
对应的每个字段映射(mapping):
-
age:类型为 integer;参与搜索,因此需要index为true;无需分词器
-
weight:类型为float;参与搜索,因此需要index为true;无需分词器
-
isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
-
info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
-
email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
-
score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
-
name:类型为object,需要定义多个子属性
-
name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
-
name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
-
2.3.2创建索引库并设置映射
语法格式
# 创建索引库并设置映射语法
PUT person
{
"mappings": {
"properties": {
"属性名":{
"type": "数据类型"
},
...
}
}
}
举例
#创建索引库并且设置映射(创建person索引库,映射两个字段name、age)
PUT person
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}2.3.3查询索引库映射
语法格式
# 查询索引库映射语法
GET 索引库名/_mapping举例
# 查询索引库映射
GET person/_mapping2.3.4增加映射字段
语法格式
# 增加映射字段语法
PUT 索引库名/_mapping
{
"properties": {
"新增属性名":{
"type": "数据类型"
}
}
}举例
#增加映射字段
PUT person/_mapping
{
"properties":{
"sex":{
"type":"keyword"
}
}
}注意:ES不能单独修改映射字段名称或类型,不能单独删除某个字段,如果需要修改,直接删除整个索引库再重建
2.4.DSL操作文档
2.4.1 添加文档
2.4.1.1指定id
语法格式
# 添加文档,指定id
POST 索引库名/_doc/指定id
{
"属性名":属性值,
...
}举例
POST person/_doc/1
{
"name":"张三",
"age":18,
"sex":"男"
}
2.4.1.2 不指定id
语法格式
# 添加文档,不指定id
POST 索引库名/_doc
{
"属性名":属性值,
...
}举例
POST person/_doc
{
"name":"翠花",
"age":20,
"sex":"女"
}
2.4.2 查询文档
2.4.2.1 查询单个
# 查询单个
GET person/_doc/1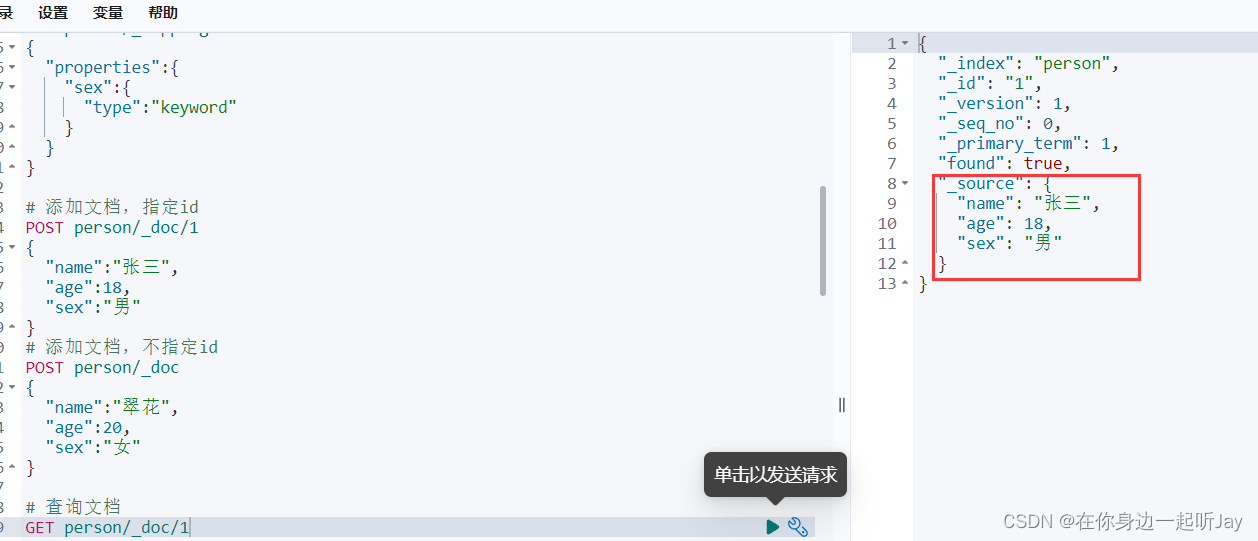
2.4.2.2 查询全部
# 查询全部
GET person/_search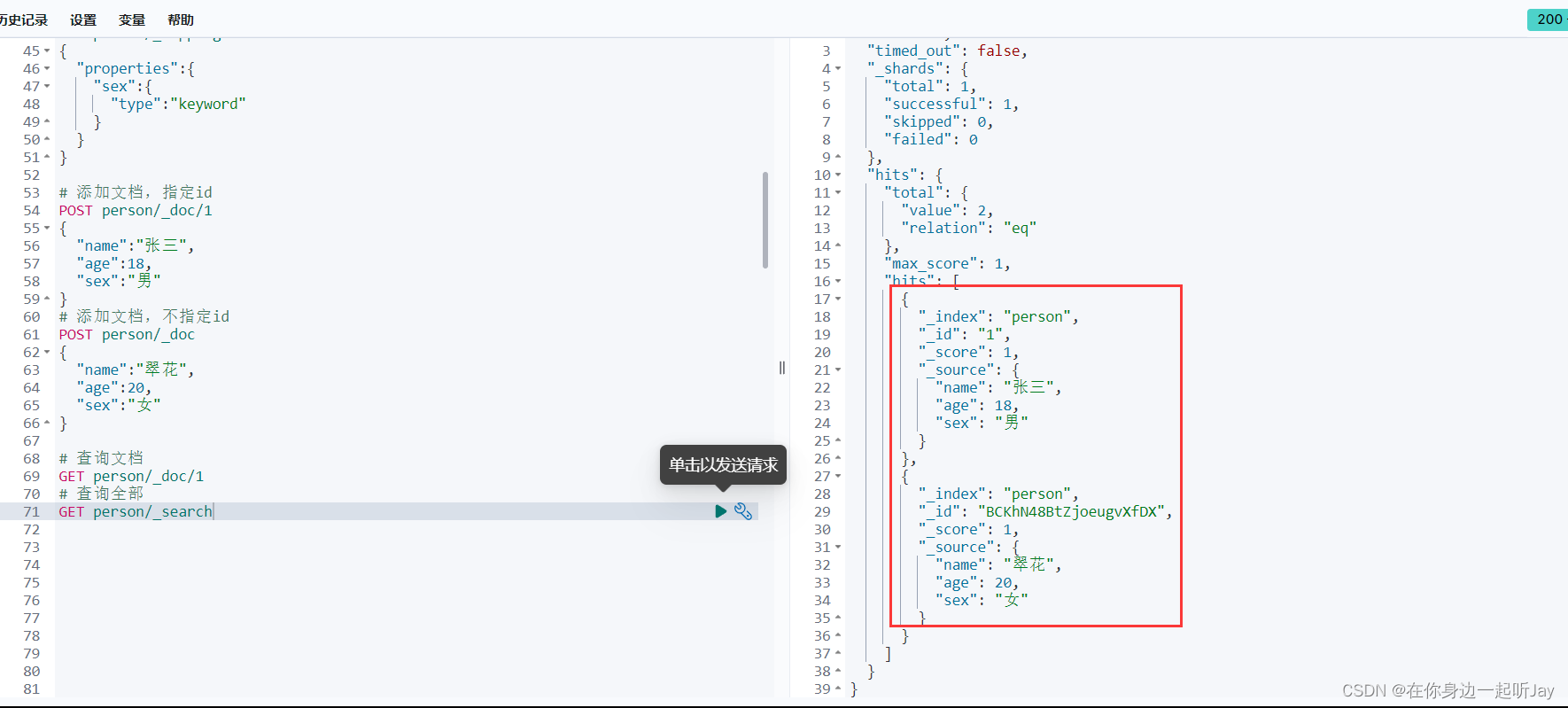
2.4.3 修改文档
语法格式
# 修改一条文档数据
PUT 索引库名/_doc/指定id
{
"属性名":属性值,
...
}举例
# 修改一条文档数据
PUT person/_doc/1
{
"name":"如花",
"age":20,
"sex":"女"
}
# 再次查看
GET person/_doc/1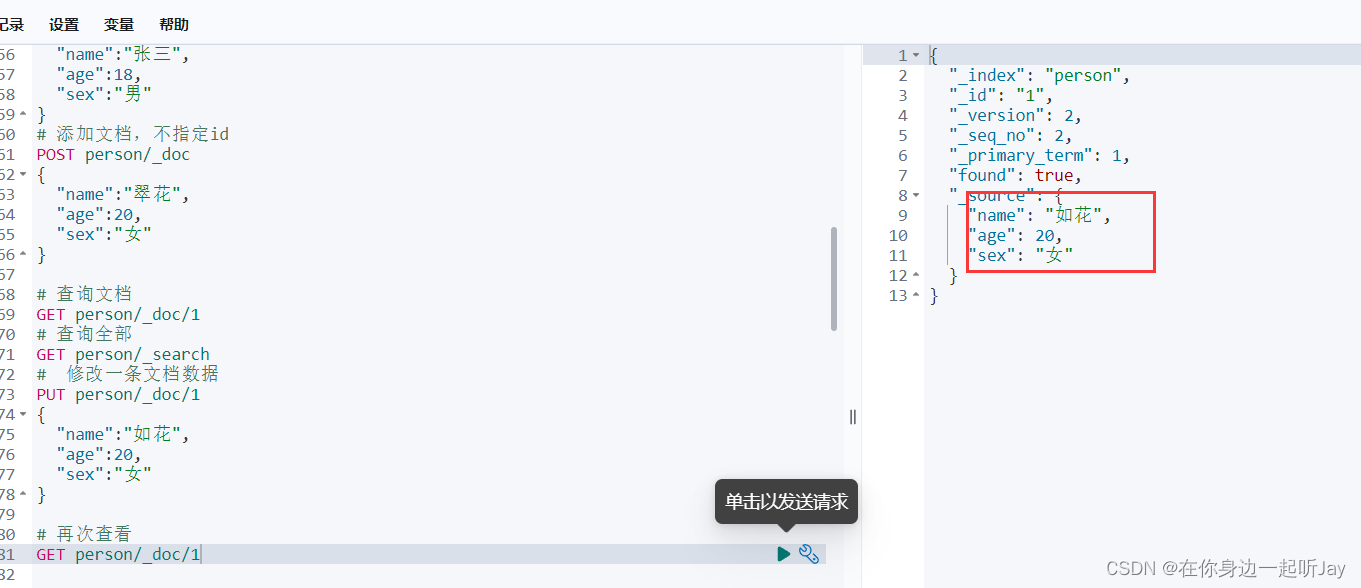
2.4.4 删除文档
语法格式
# 删除一条文档数据
DELETE 索引库名/_doc/指定id举例
#删除一条文档数据
DELETE person/_doc/1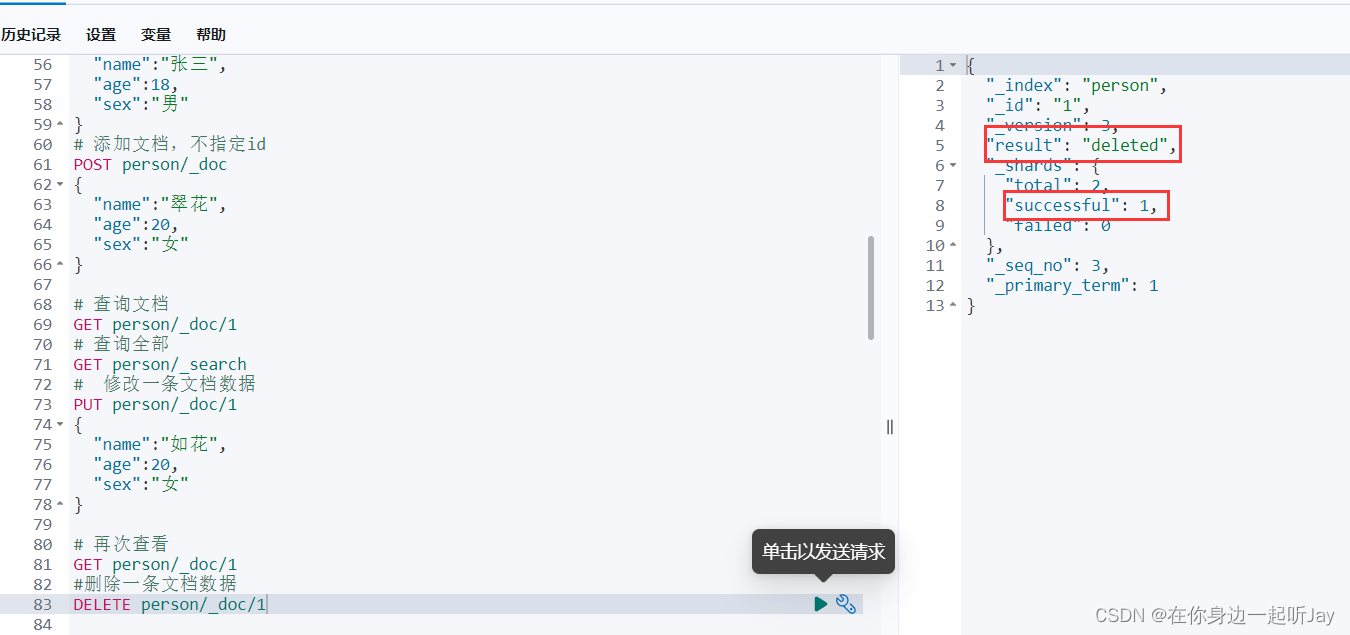
# 删除之后再查看
GET person/_doc/1
2.5.ES高级查询 DSL
*①keyword一般用于关键字/词;text存储一段文本。本质区别是text会分词,keyword不会分词;*
*②所有类型中只有text类型会分词,其余都不分词;*
*③默认情况ES使用标准分词器。其分词逻辑为:中文单字分词、英文单词分词。*
DSL由叶子查询子句和复合查询子句两种子句组成。

测试数据
// 为了便于后续测试创建如下索引
PUT products
{
"settings":{
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings":{
"properties": {
"id":{
"type":"integer"
},
"title":{
"type":"keyword"
},
"price":{
"type":"double"
},
"createtime":{
"type":"date"
},
"description":{
"type":"text"
}
}
}
}
// 注:discription字段以下形式即为指定分词器
"description":{
"type":"text",
"analyzer": "ik_max_word"
}
// 并插入如下数据
POST /products/_doc/1
{
"id":1,
"title":"小浣熊",
"price":0.5,
"createtime":"2022-11-11",
"description":"小浣熊很好吃!!"
}
POST /products/_doc/2
{
"id":2,
"title":"唐僧肉",
"price":1.0,
"createtime":"2022-11-11",
"description":"唐僧肉真不错!!很好吃!!"
}
POST /products/_doc/8
{
"id":8,
"title":"大辣片",
"price":1.0,
"createtime":"2022-11-11",
"description":"大辣片好好吃!!很好吃!!"
}
POST /products/_doc/
{
"title":"大鸡腿",
"price":10,
"createtime":"2022-11-11",
"description":"good chicken"
}
POST /products/_doc/
{
"title":"豌豆",
"price":1.5,
"createtime":"2022-11-11",
"description":"豌豆很好吃!!"
}
POST /products/_doc/
{
"title":"鱼豆腐",
"price":3.5,
"createtime":"2022-11-11",
"description":"鱼豆腐nice!!很好吃!!"
}2.5.1.查询所有(match_all)
match_all关键字:返回索引中的全部文档。
GET /products/_search
{
"query":{
"match_all": {}
}
}
注:既然是match_all后面肯定不需要限定任何条件了;但是为了满足json格式所以这里要加个"{}"Boot中操作
QueryBuilders.matchAllQuery();2.5.2.关键词查询(term)
重复三遍:文本匹配不要用term!文本匹配不要用term!文本匹配不要用term!(要用match)
term关键词:用来使用关键词查询。
①term搜索映射中的keyword类型应当使用全部内容搜索(如“大辣片”);
②text类型默认ES使用标准分词器;其分词逻辑为 对英文单词分词、对中文单字分词。
#keyword搜索完整关键词是能够搜到的
GET /products/_search
{
"query":{
"term": {
"title": "鱼豆腐"
}
}
}
注:上述描述json格式的K-V都可以换成如下。
"title":{
"value":"鱼豆腐"
}
#默认分词器下text搜索完整内容也是搜不到的
GET /products/_search
{
"query":{
"term": {
"description": "豌豆很好吃!!"
}
}
}
#默认分词器下text搜索单个汉字是能搜到的
GET /products/_search
{
"query":{
"term": {
"description": "好"
}
}
}
#默认分词器下text搜索单个英文单词也是能搜到的
GET /products/_search
{
"query":{
"term": {
"description": "nice"
}
}
}Boot中操作
QueryBuilders.termQuery("字段名", "值");2.5.3.多关键词查询(terms)
terms关键词:用于某个关键词匹配多个值的查询。和 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配。
GET /products/_search
{
"query":{
"terms": {
"title": [
"大鸡腿",
"大辣片"
]
}
}
}Boot中操作
QueryBuilders.termsQuery("字段名", "值1", "值2");2.5.4.范围查询(range)
range关键字:用来指定查询范围内的文档
#查询加个范围
GET /products/_search
{
"query":
{
"range": {
"price": {
"gte": 5,
"lte": 10
}
}
}
}Boot中操作
QueryBuilders.rangeQuery("范围搜索字段").gte("2020-01-09").lte("2020-01-09");2.5.5.前缀查询(prefix)
prefix关键字:用来检索含有指定前缀的关键词的相关文档。
#针对keyword类型是可以前缀查询到的
GET /products/_search
{
"query":{
"prefix": {
"title": {
"value": "小浣"
}
}
}
}
#针对text类型如果是英文的话也是可以前缀查到的
GET /products/_search
{
"query":{
"prefix": {
"description": {
"value": "goo"
}
}
}
}Boot中操作
QueryBuilders.prefixQuery("字段名","值")2.5.6.通配符与正则表达式查询(wildcard/regexp)
wildcard 和 regexp 查询的工作方式与 prefix 查询完全一样,它们也需要扫描倒排索引中的词列表才能找到所有匹配的词,然后依次获取每个词相关的文档 ID ,与 prefix 查询的唯一不同是:它们能支持更为复杂的匹配模式。
wildcard关键字:通配符查询。 ?用来匹配一个任意字符 *用来匹配多个任意字符。
#对于text类型。这样是能查到的
GET /products/_search
{
"query":{
"wildcard": {
"description": {
"value": "goo?"
}
}
}
}
#这样是查不到的
GET /products/_search
{
"query":{
"wildcard": {
"description": {
"value": "go?"
}
}
}
}
注:因为good是description字段的一个分词。Boot中操作
QueryBuilders.wildcardQuery("字段名", "值*");
QueryBuilders.regexpQuery("字段名", "值");2.5.7.多id查询(ids)
ids关键字:值为数组类型,用来根据一组id获取多个对应的文档。
注:这里相当于指定字段就是docid,感觉用的不是很多了吧
#注:这里就是限定死查询某些docid的数据,只能是docid。
GET /products/_search
{
"query": {
"ids": {
"values":["1","8"]
}
}
}Boot中操作
QueryBuilders.idsQuery().addIds("id1","id2",...)2.5.8.模糊查询(fuzzy)
fuzzy关键字:用来模糊查询含有指定关键字的文档。
注意:fuzzy模糊 最大模糊错误必须在0~2之间
①搜索关键词长度为2不允许存在模糊 ②搜索关键词长度为3~5允许一次模糊 ③搜索关键词长度大于5最大2次模糊
#这样是可以查询到title为“小浣熊”的数据的
GET /products/_search
{
"query": {
"fuzzy": {
"title":"小浣猫"
}
}
}Boot中操作
QueryBuilders.fuzzyQuery("字段名", "值"); 2.5.9.布尔查询(bool) 重要!!!!!
bool关键字:用来组合多个条件实现复杂查询,*相当于逻辑操作*。bool查询可以嵌套组合任意其他类型的查询,甚至继续嵌套bool查询也是可以的。
实际语法为:bool下面套filter/must/should/must_not实现逻辑效果(bool包含四种子句)。
①must:相当于&& 要求同时成立; ②should:1)相当于逻辑或的关系; 2)影响评分机制,会把匹配的更多的文档评分提高。 ③must_not:相当于! 取非(逻辑非); ④filter: 可以将上述term、range等诸多条件都放在filter里面
注:filter可以放到bool条件下面,同样bool条件也可以放在filter下面。
#must 同时满足条件
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"term":{"title":"小浣熊"}
},
{
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
#should 满足一个条件即可
GET /products/_search
{
"query": {
"bool": {
"should": [
{
"term":{"title":"小浣熊"}
},
{
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
}
]
}
}
}
#查询 msg_content 字段不为空的消息
GET es_qidian_msg_202401/_search
{
"size":100,
"query":{
"bool":{
"must_not":[
{
"term":{
"msg_content":""
}
}
]
}
}
}
#进一步组合也都是可以的
GET /products/_search
{
"bool": {
"filter":[
{"term":{"key1":value}}
{"range":{"key2":{"gt":value1,"lt":value2}}}
]
"must": { "term": { }},
"must_not": { "term": { }},
"should":
[
{ "term": { }},
{ "term": { }}
]
}
}
注:must可以是数组,即[];也可以不是数组,即{}.2.5.10.match匹配查询 重要!!!!
match:不仅会显示精确匹配的结果也会显示相似匹配的结果,非常强大。
原理:query可以输入关键词也可以输入一段文本。它会根据你实际查询的字段的类型决定是否对query内容进行分词。①如果你查询的字段是分词的,它就会对你query的内容进行分词然后再去搜。②如果该字段是不分词的就将查询条件作为整体进行查询。
match支持以下参数:
-
query : 指定匹配的值
-
operator : 匹配条件类型
-
and : 条件分词后都要匹配
-
or : 条件分词后有一个匹配即可(默认)
-
minmum_should_match : 最低匹配度,即条件在倒排索引中最低的匹配度,
可以使用百分比或固定数字。百分比代表query搜索条件中词条百分比,如果无法整除,向下匹配(如,query条件有3个单词,如果使用百分比提供精准度计算,那么是无法除尽的,如果需要至少匹配两个单词,则需要用67%来进行描述。如果使用66%描述,ES则认为匹配一个单词即可。)。固定数字代表query搜索条件中的词条,至少需要匹配多少个。
#其本质是拿‘浣’去搜,现在就能匹配到数据;然后再拿‘猫’去搜。
GET /products/_search
{
"query": {
"match": {
"description": "浣猫"
}
}
}
# 如果需要同时包含 “浣” 和 “猫”, 默认是or
GET /products/_search
{
"query": {
"match": {
"description": "浣 猫",
"operator": "and"
}
}
}
2.5.11.multi_match query 多字段匹配查询
多字段查询:可以根据字段类型,决定是否使用分词查询,得分最高的在前面 注意:字段类型分词,将查询条件分词之后进行查询,如果该字段不分词就会将查询条件作为整体进行查询。
# description 或 title 中包含‘浣熊’
POST /products/_search
{
"query":{
"multi_match":{
"query":"浣熊",
"fields":["description","title"]
}
}
}2.5.12.match_phrase query短语搜索
短语搜索(match phrase)会对搜索文本进行文本分析,然后到索引中寻找搜索的每个分词并要求分词相邻,你可以通过调整slop参数设置分词出现的最大间隔距离。match_phrase 会将检索关键词分词。
2.5.13.query_string query
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和 multi_match query 一样,支持多字段搜索。和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。 注意: 查询字段分词就将查询条件分词查询,查询字段不分词将查询条件不分词查询
2.5.14.simple_query_string
类似Query String,但是会忽略错误的语法,同时只支持部分查询语法,不支持AND OR NOT,会当作字符串处理。支持部分逻辑:
-
“+” 替代 “AND”
-
“|” 替代 “OR”
-
“-” 替代 “NOT”
2.5.15.查询是否包含某个字段(exists)
exists 过滤可以用于查找文档中是否包含指定字段或没有某个字段
#查询包含“id”字段的数据
GET /products/_search
{
"query": {
"exists": {"field":"id"}
}
}Boot中操作
ExistsQueryBuilder existsQueryBuilder = QueryBuilders.existsQuery("字段");2.5.16.高亮
什么是高亮显示呢?
我们在百度,京东搜索时,关键字会变成红色,比较醒目,这叫高亮显示
高亮显示的实现分为两步:
-
1)给文档中的所有关键字都添加一个标签,例如
<em>标签 -
2)页面给
<em>标签编写CSS样式
高亮的语法:
GET products/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}注意:
-
高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
-
默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
-
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
2.5.17.指定返回条数(size)
size关键字:指定查询结果中返回指定条数的数据。注:默认返回10条。
注:size的书写位置没有顺序,最前面、中间、后面都是可以的;符合json规范就成。
#满足条件的有三条,这里限定只返回2条
GET /products/_search
{
"query": {
"match": {
"description": "this is"
}
},
"size":2
}2.5.18.分页查询(from)
from关键字:用来指定起始返回位置,和size连用可以实现分页效果。
#第一把
GET /products/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size":5
}
#翻页第二把
GET /products/_search
{
"query": {
"match_all": {}
},
"from": 5,
"size":5
}2.5.19.指定字段排序(sort)
注意:sort和最外层的query平齐!!!!
#desc:降序
#asc:升序
GET /products/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}2.5.20.指定返回字段(_source)
_source关键字:是一个数组,在数组中指定展示哪些字段。
注意:这里的“_source”也是和最外层的“query”平齐的
GET /products/_search
{
"query": {
"match_all": {}
},
"_source": ["title","price"]
}更多的查询命令:
ES官网点击直达
2.6.聚合查询(Aggregation aggs)
简单来讲类似于sql中的group by。
注:text类型是不支持聚合的。
为了便于测试创建如下索引
PUT fruit
{
"mappings": {
"properties": {
"title":{
"type":"keyword"
},
"price":{
"type":"double"
},
"description":{
"type":"text",
"analyzer": "ik_max_word"
}
}
}
}
GET fruit
#并插入如下数据
POST fruit/_bulk
{"index":{}}
{"title":"面包","price":19.9,"description":"小面包很好吃"}
{"index":{}}
{"title":"大白兔","price":29.9,"description":"大白兔奶糖好吃"}
{"index":{}}
{"title":"豌豆","price":19.9,"description":"豌豆非常好吃"}
{"index":{}}
{"title":"旺仔小馒头","price":19.9,"description":"旺仔小曼斗很甜"}
{"index":{}}
{"title":"大辣片","price":9.9,"description":"大辣片很诱人"}
{"index":{}}
{"title":"脆司令","price":19.9,"description":"脆司令很管饿"}
{"index":{}}
{"title":"喜之郎果冻","price":19.9,"description":"小时候的味道"}2.6.1.根据某个字段分组
语法:其语法就是在query平齐的位置加上一个aggs。
#如下为一个实例。
#其中"shuozhuo_price_group"为此次聚合的结果随便取的一个名字;这个名字是我们自定义的。
#terms也是写死的。其含义是基于那个字段进行分组。
GET /fruit/_search
{
"query": {
"match_all": {}
},
"aggs": {
"shuozhuo_price_group": {
"terms": {
"field": "price"
}
}
}
}
#仅返回结果,不返回原始数据
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0, #
"aggs": {
"shuozhuo_price_group": {
"terms": {
"field": "price"
}
}
}
} 返回结果如下: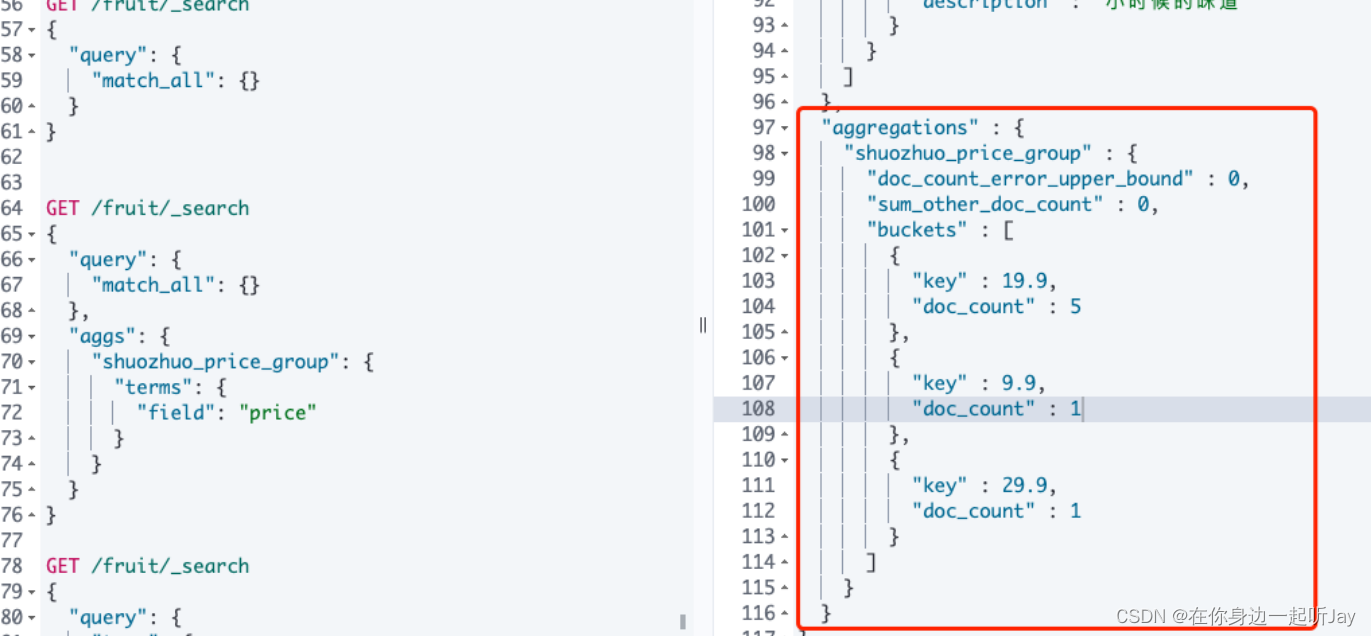
整个返回中的aggregations字段就是聚合结果;
buckets是一个数组表示的就是聚合后的数组;
注:如果只想返回聚合结果不想返回查询数据的话,利用size就好了。
2.6.2.求最大值/最小值/平均值
#最大值
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_max_price": {
"max": {
"field": "price"
}
}
}
}
#最小值
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_min_price": {
"min": {
"field": "price"
}
}
}
}
#平均值
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_avg_price": {
"avg": {
"field": "price"
}
}
}
}
#求和
GET /fruit/_search
{
"query": {
"match_all": {}
},
"size":0,
"aggs": {
"shuozhuo_sum_price": {
"sum": {
"field": "price"
}
}
}
}SpringBoot整合ES
整合boot依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.14</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.37</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>application.yml配置
spring:
elasticsearch:
username: elastic
password: 123456
# 集群就用逗号隔开
uris: http://127.0.0.1:9201
# username: xxx
# password: yyy
# connection-timeout: 1
# read-timeout: 30再自己写个启动类,单元测试类测试
一、基本概念
ElasticsearchTemplate
ElasticsearchTemplate是Spring对ES api的封装,提供大量的类完成各种操作。
QueryBuilders、NativeSearchQuery
springboot中使用QueryBuilders、NativeSearchQuery实现复杂查询
1) QueryBuilders
QueryBuilders是ES中的查询条件构造器
QueryBuilders.boolQuery #子方法must可多条件联查
QueryBuilders.termQuery #精确查询指定字段
QueryBuilders.matchQuery #按分词器进行模糊查询
QueryBuilders.rangeQuery #按指定字段进行区间范围查询
2) NativeSearchQuery 原生的查询条件类,用来和ES的一些原生查询方法进行搭配,实现一些比较复杂的查询,最终进行构建.build 可作为ElasticsearchTemplate. queryForPage的参数使用
//构建Search对象
NativeSearchQuery build = new NativeSearchQueryBuilder()
//条件
.withQuery(queryBuilder)
//排序
.withSort(SortBuilders.fieldSort("id").order(SortOrder.ASC))
//高亮
.withHighlightFields(name, ms)
//分页
.withPageable(PageRequest.of(pageNum - 1, pageSize))
//构建
.build();
AggregatedPage<Goods> aggregatedPage = elasticsearchTemplate.queryForPage(build, Goods.class,new Hig());
//queryForPage 参数一: NativeSearchQuery 封装的查询数据对象
参数二: es对应索引实体类
参数三: 调用高亮工具类
大于等于 .from .gte
小于等于 .to .lte @Document 和 @Field 注解
用来加上实体类上面,描述索引库信息和属性类型分词器等信息
@Persistent
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
public @interface Document {
String indexName(); //索引名称,好比MySQL的数据库名
@Deprecated
String type() default ""; //类型 ,当前版本已弃用
/**
* Use server-side settings when creating the index.
* 翻译过来就是:创建索引时使用服务器端设置。
* 这里默认为false,如果改为true,表示在Spring创建索引时,Spring不会在创建的索引中设置以下设
* 置:shards、replicas、refreshInterval和indexStoreType。这些设置将是 Elasticsearch 默认
* 值(服务器配置),也就是说,我们自定义的某些配置将不会生效。
*/
boolean useServerConfiguration() default false;
short shards() default 1; // 默认分区数
short replicas() default 1;// 默认每个分区的备份数
String refreshInterval() default "1s"; //索引默认的刷新时间间隔
String indexStoreType() default "fs"; //索引文件存储类型
/**
* Configuration whether to create an index on repository bootstrapping.
*/
boolean createIndex() default true; //当spring容器启动时,如果索引不存在,则自动创建索引
VersionType versionType() default VersionType.EXTERNAL;//默认的版本管理类型
}@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Documented
@Inherited
public @interface Field {
@AliasFor("name")
String value() default "";
@AliasFor("value")
String name() default "";
//上面两个注解,可互为别名使用。
//主要的作用就是指定我们创建索引时,当前字段在索引中的名称,如果不设置,它会默认使用实体类里
// 面使用了@Field这个注解的属性名作为索引字段名。例如:
// class User{
//
// @Field(name = "name" * 或者:value = "name"* )
// private String userName;
// }
// 如上,如果设置了name(或value)值,那么索引里面对应userName的字段名就是“name”,否则就是
// “userName”
FieldType type() default FieldType.Auto; //自动检测索引字段的数据类型,可以根据实际情况自己设置。
DateFormat format() default DateFormat.none;//日期时间格式化,默认不做任何处理
String searchAnalyzer() default "";//检索时的分词策略
String analyzer() default "";//创建索引时指定分词策略
}
@Field中提到的FieldType 枚举
public enum FieldType {
Auto, //根据内容自动判断
Text, //索引全文字段,如产品描述。这些字段会被分词器进行分词处理。
Keyword, //用于索引结构化内容(如电子邮件地址,主机名,状态码,邮政编码等)的字段。他们通常用于过滤、排序、聚合。关键字字段只能根据期确切的值进行搜索。标记为keyword的字段不会被分词器分词处理
Long, //
Integer, //
Short, //
Byte, //
Double, //
Float, //
Half_Float, //
Scaled_Float, //
Date, //
Date_Nanos, //
Boolean, //
Binary, //
Integer_Range, //
Float_Range, //
Long_Range, //
Double_Range, //
Date_Range, //
Ip_Range, //
Object, //
Nested, //
Ip, //可以索引和存储IPV4和IPv6地址
TokenCount, //
Percolator, //
Flattened, //
Search_As_You_Type //
}实体类
这里使用大家熟悉的Oracle中的Emp员工表做演示
/**
* @TableName emp
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
/**
* indexName:索引名称 唯一
* shards(默认为1):对应DSL中创建索引 settings中的 number_of_shards
* 是指索引要做多少个主分片,只能在创建索引时指定,后期无法修改。
* 主分片,每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,
* 然后会复制到不同的副本中。默认情况下,一个索引有1个主分片。
* 你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
* replicas(默认为1):对应DSL中创建索引 settings中的 number_of_replicas
* 是指每个分片有多少个副本,后期可以动态修改
* 副本分片,每一个分片有零个或多个副本。副本主要是主分片的复制,可以 增加高可用性,提高性能。
* 默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。
* 副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
*
* 在Elasticsearch中,使用Spring Data Elasticsearch的@Document注解会生成一个名为_class的字段。
* 这个字段用于标记被索引文档的完整类名,以确保在搜索时能够正确地反序列化文档到正确的Java类。
*
* createIndex:在使用mapper接口操作ES时 会自动帮你创建索引
* 如果你实体类有对应的mapper接口(继承了ElasticsearchRepository) 并注入使用,
* 而又需要使用ElasticsearchRestTemplate来创建索引 就必须设置为false 不然会创建两次索引 导致报错。
* 如果你仅使用ElasticsearchRestTemplate创建索引 但是没有用到mapper接口 则不需要设置这个属性。
* 如果直接操作mapper保存数据 不自己用代码创建索引 它会自动帮你创建 createIndex设置什么值都一样 都会帮你创建
*
* 简单省事:直接使用mapper接口操作就行 无需自己写代码创建索引了
*/
@Document(indexName = "idx_emp",shards = 1,replicas = 0,createIndex = false)
public class Emp implements Serializable {
/*
@Id如果需要使用Mapper来操作 就必须加这个注解 不然报错 找不到id
template添加数据时 不指定id 会自动随机一个id 指定后 员工id作为文档id
mapper添加数据时 会以员工id作为文档id
文档数据id 重复的id会覆盖之前的数据
*/
@Id
/*
@Field
如果你的索引创建使用的是ElasticsearchRestTemplate 则必须写该属性 且 必须加上type属性指定类型 不然无法生成映射
如果你使用的mapper接口 那么可以省略该注解 会自动识别
*/
@Field(type = FieldType.Integer)
private Integer empno;
/**
* type:指定数据类型
* analyzer分词器 可以不写
* ik_max_word:会做 最细 粒度的拆分,把能拆分的词都拆出来
* ik_smart:会做 最粗 粒度的拆分,贪心算法,尽可能把词分得长
*/
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String ename;
@Field(type = FieldType.Keyword)
private String job;
@Field(type = FieldType.Integer)
private Integer mgr;
@Field(type = FieldType.Date)
private String hiredate;
@Field(type = FieldType.Double)
private Double sal;
@Field(type = FieldType.Double)
private Double comm;
@Field(type = FieldType.Integer)
private Integer deptno;
private static final long serialVersionUID = 1L;
}Mapper接口
使用后会自动创建索引,需要就写 不需要不写
import com.zhibang.entity.Emp;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface EmpMapper extends ElasticsearchRepository<Emp,Integer> {
}索引库操作
以下均在测试类中操作,需注入ElasticsearchTemplate,使用Mapper则注入Mapper接口(无需注册组件)
创建索引及映射
@Test
public void 创建索引(){
IndexOperations index = restTemplate.indexOps(Emp.class);
// 如果索引存在则会报错 也可以先判断后创建
boolean b = index.create();
if(b){
System.out.println("创建索引库成功");
// 生成映射
Document mapping = index.createMapping();
// 创建映射
boolean b1 = index.putMapping();
System.out.println(b?"创建映射成功":"创建映射失败");
}
}
// 方式2 直接使用Mapper接口操作 会自动创建删除索引
@Test
public void 删除索引(){
IndexOperations index = restTemplate.indexOps(Emp.class);
boolean b = index.delete();
System.out.println(b?"删除成功":"删除失败");
}判断索引是否存在
@Test
public void 判断索引是否存在(){
IndexOperations index = restTemplate.indexOps(Emp.class);
boolean b = index.exists();
System.out.println(b?"存在":"不存在");
}文档操作
添加数据
@Test
public void 添加数据(){
Emp emp = Emp.builder().empno(1001).job("开发").mgr(8888).sal(5000d).
ename("李四").hiredate("2020-1-1").comm(100d).deptno(10).build();
try {
// 这里我用try 是因为springboot整合的ES版本为7.17.11 我的客户端是8.12.2 不匹配会报错 但并不影响使用
// 目前(2024年4月)最新版本依赖也才到7 如果不希望报错 需使用对应版本的ES客户端
// 这里保存数据 可以直接存储对象或集合
restTemplate.save(emp);
// 方式2
//empMapper.save(emp);
}catch (Exception e){}
}根据ID查询
@Test
public void 根据文档id查询数据(){
// 方式1
Emp emp = restTemplate.get("1001", Emp.class);
System.out.println(emp);
// 方式2
Emp emp2 = empMapper.findById("1001").get();
System.out.println(emp2);
}查询全部
@Test
public void 查询全部(){
// 方式1
Iterator<Emp> emps = empMapper.findAll().iterator();
// 自己转集合
List<Emp> list = new ArrayList<>();
while(emps.hasNext()){
list.add(emps.next());
}
list.forEach(System.out::println);
// 方式2
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery()).build();
SearchHits<Emp> search = restTemplate.search(build, Emp.class);
for (SearchHit<Emp> e : search) {
Emp emp = e.getContent();
System.out.println(emp);
}
}高亮查询
public SearchHits<Entity> search(String keyword) {
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("firstname", keyword);
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("firstname");
highlightBuilder.requireFieldMatch(false);//多个高亮关闭
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(matchQueryBuilder)
.build();
query.setHighlightQuery(new HighlightQuery(highlightBuilder));
SearchHits<Entity> search = restTemplate.search(query, Entity.class);
return search;
}分页查询
public SearchHits<Entity> selectByPage(int page, int size) {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withPageable(PageRequest.of(page - 1, size))
.build();
SearchHits<Entity> search = restTemplate.search(query, Entity.class);
return search;
}排序
public SearchHits<Entity> selectByAgeDesc() {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withSort(SortBuilders.fieldSort("age").order(SortOrder.DESC))
.build();
SearchHits<Entity> search = restTemplate.search(query, Entity.class);
return search;
}时间范围
public SearchHits<Entity> selectByRangeTime(String begin, String end) {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withSort(SortBuilders.fieldSort("createTime")
.order(SortOrder.DESC))
.withFilter(QueryBuilders.rangeQuery("createTime")
.timeZone("+08:00")
.format("yyyy-MM-dd HH:mm:ss")
.gt(begin)
.lt(end))
.build();
SearchHits<Entity> search = restTemplate.search(query, Entity.class);
return search;
}同字段多条件匹配查询(or)
public SearchHits<Entity> searchAll() {
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("age", "21", "31");
Query query = new NativeSearchQueryBuilder().withQuery(termsQueryBuilder).build();
SearchHits<Entity> search = restTemplate.search(query, Entity.class);
return search;
}boostingQuery
public SearchHits<Entity> boostingQuery() {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(
QueryBuilders.boostingQuery(
QueryBuilders.termQuery("age", "31"), //希望包含的
QueryBuilders.termQuery("account_number", "51") //包含降低得分
).negativeBoost(0.2f)//设置满足negativeQuery精度
).build();
SearchHits<Entity> search = restTemplate.search(query, Entity.class);
return search;
}constantScoreQuery
public SearchHits<Entity> constantScoreQuery() {
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(
QueryBuilders.constantScoreQuery(
QueryBuilders.termQuery("account_number", "51")
).boost(1.2f)
).build();
SearchHits<Entity> search = restTemplate.search(query, Entity.class);
return search;
}














 4303
4303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









