








一、Dapper 简介
在分布式链路追踪方面,Google早在2010年针对其内部的分布式链路跟踪系统Dapper[1],发表了相关论文对分布式链路跟踪技术进行了介绍(强烈推荐阅读)。其中提出了两个基本要求。第一,拥有广泛的覆盖面。针对庞大的分布式系统,其中每个服务都需要被监控系统覆盖,即使是整个系统的一小部分没有被监控到,该链路追踪系统也可能是不可靠的。第二,提供持续的监控服务。对于链路监控系统,需要7*24小时持续保障业务系统的健康运行,保证任何时刻都可以及时发现系统出现的问题,并且通常情况下很多问题是难以复现的。根据这两个基本要求,分布式链路监控系统的有如下几个设计目标:
- 应用级透明
链路监控组件应该以基础通用组件的方式提供给用户,以提高稳定性,应用开发者不需要关心它们。对于Java语言来说,方法可以说是调用的最小单位,想要实现对调用链的监控埋点势必对方法进行增强。Java中对方法增强的方式有很多,比如直接硬编码、动态代理、字节码增强等等。应用级透明其实是一个比较相对的概念,透明度越高意味着难度越大,对于不同的场景可以采用不同的方式。 - 低开销
低开销是链路监控系统最重要的关注点,分布式系统对于资源和性能的要求本身就很苛刻,因此监控组件必须对原服务的影响足够小,将对业务主链路的影响降到最低。链路监控组件对于资源的消耗主除了体现在增强方法的消耗上,其次还有网络传输和数据存储的消耗,因为对于链路监控系统来说,想要监控一次请求势必会产生出请求本身外的额外数据,并且在请求过程中,这些额外的数据不仅会暂时保存在内存中,在分布式场景中还会伴随着该请求从上游服务传输至下游服务,这就要求产生的额外数据尽可能地少,并且在伴随请求进行网络传输的时候只保留少量必要的数据。 - 扩展性和开放性
无论是何种软件系统,可扩展性和开放性都是衡量其质量优劣的重要标准。对于链路监控系统这样的基础服务系统来说,上游业务系统对于链路监控系统来说是透明的,在一个规模较大的企业中,一个基础服务系统往往会承载成千上万个上游业务系统。每个业务系统由不同的团队和开发人员负责,虽然使用的框架和中间件在同一个企业中有大致的规范和要求,但是在各方面还是存在差异的。因此作为一个基础设施,链路监控系统需要具有非常好的可扩展性,除了对企业中常用中间件和框架的支撑外,还要能够方便开发人员针对特殊的业务场景进行定制化的开发。
二、数据模型
OpenTracing规范
Dapper将请求按照三个维度划分为Trace、Segment、Span三种模型,该模型已经形成了OpenTracing[2]规范。OpenTracing是为了描述分布式系统中事务的语义,而与特定下游跟踪或监控系统的具体实现细节无关,因此描述这些事务不应受到任何特定后端数据展示或者处理的影响。大的概念就不多介绍了,重点看一下Trace、Segment、Span这三种模型到底是什么。
-
Trace
表示一整条调用链,包括跨进程、跨线程的所有Segment的集合。 -
Segment
表示一个进程(JVM)或线程内的所有操作的集合,即包含若干个Span。 -
Span
表示一个具体的操作。Span在不同的实现里可能有不同的划分方式,这里介绍一个比较容易理解的定义方式:
- Entry Span:入栈Span。Segment的入口,一个Segment有且仅有一个Entry Span,比如HTTP或者RPC的入口,或者MQ消费端的入口等。
- Local Span:通常用于记录一个本地方法的调用。
- Exit Span:出栈Span。Segment的出口,一个Segment可以有若干个Exit Span,比如HTTP或者RPC的出口,MQ生产端,或者DB、Cache的调用等。
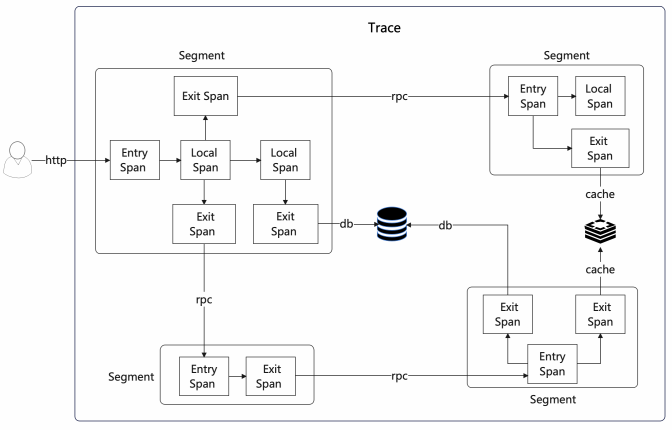
按照上面的模型定义,一次用户请求的调用链路图如下所示:
唯一id
每个请求有唯一的id还是很必要的,那么在海量的请求下如何保证id的唯一性并且能够包含请求的信息?阿里的 Eagleeye traceId 的逻辑:

根据这个id,我们可以知道这个请求在2022-10-18 10:10:40发出,被11.15.148.83机器上进程号为14031的Nginx(对应标识位e)接收到。其中的四位原子递增数从0-9999,目的是为了防止单机并发造成traceId碰撞。
关系描述
将请求划分为Trace、Segment、Span三个层次的模型后,如何描述他们之间的关系?
从【OpenTracing规范】一节的调用链路图中可以看出,Trace、Segment可以作为整个调用链路中的逻辑结构,而Span才是真正串联起整个链路的单元,系统可以通过若干个Span串联起整个调用链路。
在Java中,方法是以入栈、出栈的形式进行调用,那么系统在记录Span的时候就可以通过模拟出栈、入栈的动作来记录Span的调用顺序,不难发现最终一个链路中的所有Span呈现树形关系,那么如何描述这棵Span树?阿里的Eagleeye中的设计很巧妙,EagleEye设计了RpcId来区别同一个调用链下多个网络调用的顺序和嵌套层次。如下图所示:
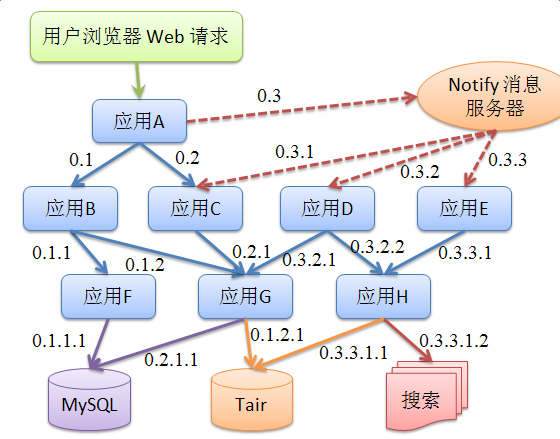
RpcId用0.X1.X2.X3…Xi来表示,根节点的RpcId固定从0开始,id的位数("."的数量)表示了Span在这棵树中的层级,Id最后一位表示了Span在这一层级中的顺序。那么给定同一个Trace中的所有RpcId,便可以很容易还原出一个完成的调用链:
- 0
- 0.1
- 0.1.1
- 0.1.2
- 0.1.2.1
- 0.2
- 0.2.1
- 0.3
- 0.3.1
- 0.3.1.1
- 0.3.2
跨进程传输
再进一步,在整个调用链的收集过程中,不可能将整个Trace信息随着请求携带到下个应用中,为了将跨进程传输的trace信息减少到最小,每个应用(Segment)中的数据一定是分段收集的,这样在实现下跨Segment的过程中需要携带traceId和rpcid两个简短的信息即可。在服务端收集数据时,数据自然也是分段到达服务端的,但由于种种原因分段数据可能存在乱序和丢失的情况:
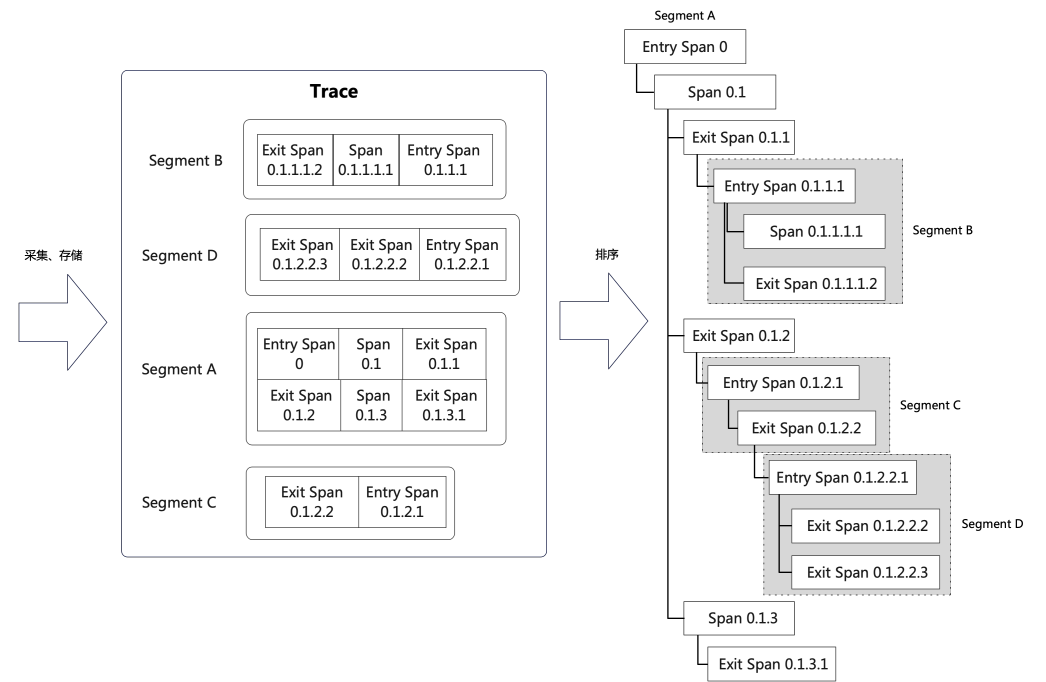
如上图所示,收集到一个Trace的数据后,通过rpcid即可还原出一棵调用树,当出现某个Segment数据缺失时,可以用第一个子节点替代。
三、数据埋点
如何进行方法增强(埋点)是分布式链路追系统的关键因素,在Dapper提出的要求中可以看出,方法增强同时要满足应用级透明和低开销这两个要求。之前我们提到应用级透明其实是一个比较相对的概念,透明度越高意味着难度越大,对于不同的场景可以采用不同的方式。
-
SDK手动编码插桩
这个需要团队有非常明确的开发使用规范,明确定义好监控的覆盖范围,同时也需要专门的维护团队来开发。对于不能实现字节码增强的开发语言,这也是最好的一种实现方式,在维护性,性能消耗上有一定的优势,缺点就是耗时耗力,对于老应用的改造很麻烦。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3495
3495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









