






错误日志
错误日志(Error log)是MySQL中最常用的一种日志,主要记录MySQL服务启动和停止过程中的信息、服务在运行过程中发生的故障和情况等。在实际工作中,我们通过错误日志分析得到导致业务崩溃和其它故障的根本原因。
1、查看错误日志的位置
db01 [(none)]>select @@log_error;
+---------------------+
| @@log_error |
+---------------------+
| /tmp/mysqld3306.err |
+---------------------+
1 row in set (0.00 sec)
错误日志默认是开启的状态,其对应的文件名称默认就是MySQL数据目录的下的 [hostname.err]
当然也可以自己指定错误日志的存放路径:
在配置文件/etc/my.cnf中mysqld模块配置一下信息
[mysqld]
log_error=/tmp/mysql3306.err
配置完成后重启MySQL服务就会在指定的路径下,自动创建错误日志文件
tip:使用错误日志进行错误排查时,主要注意 error log 中显示[ERROR]所对应的上下文信息。
2、错误日志轮询
为了方便错误日志的管理和使用,所以可以使用日志轮询的方式来对错误日志进行切割。
[root@db01 ~] # cd /tmp #切换到错误日志所在的目录下
[root@db01 tmp] #mv mysqld3306.err mysqld3306.err_$(date +%F) #将错误日志按天切割
[root@db01 tmp] #mysqladmin -uroot -p123123 flush-logs #刷新日志文件命令(原来的错误日志文件已被移走,需要再创建一个错误日志文件)
[root@db01 tmp] # ll
-rw-r----- 1 mysql mysql 0 Mar 25 11:45 mysqld3306.err
二进制日志(binlog)
二进制日志是MySQL服务中重要的数据信息,在数据库数据恢复、多实例之间构建主从都需要使用到二进制日志。
1、参数配置
二进制日志默认是没有开启的,可以通过配置 log_bin 参数来启用二进制日志:
[mysqld]
log_bin=/data/binlog/mysql-bin
##log_bin参数:可设置为1,则binlog功能就会开启,MySQL服务中产生的二进制日志数据就会存储到MySQL默认的文件中;
## 也可以在此参数后指定文件,表示开启binlog功能,并把MySQL服务产生的二进制日志数据存储到自己指定的文件中去。
#############################################################################################
tip:
自己指定二进制日志的存储路径时,需要先创建好路径。例如上面的案例中"log_bin=/data/binlog/mysql-bin":
[root@db01 ~] # mkdir /data/binlog //需要提前创建好路径信息
[root@db01 ~] # chown -R mysql:mysql /data/binlog //给路径修改属主、数组
其中mysql-bin是二进制文件名的前缀,二进制日志文件的名称由前缀和序号组合而成,例如:mysql-bin.000001、mysql-bin.000002 ...
可通过"max_binlog_size"参数来控制一个binary log文件的大小。
####################################################################################################
2、binlog文件滚动(即mysql-bin.xxxxxx文件新增一个,编号+1)
- 在MySQL中执行"flush logs"指令,就会滚动一个新的日志,即"flush logs"的作用就是关闭当前使用的binary log,然后打开一个
- 一个binary log写满了,MySQL会自动新开一个binary log,文件序号+1
- MySQL数据库重启时,也会滚动日志
3、二进制日志记录了什么
二进制日志文件中记录了数据库所有变更类的操作日志。对于DDL和DCL语句,会以语句的方式,原模原样的记录下来;对于DML语句,只记录已提交的事务,并且有三种记录格式:
- statement:又称SBR模式,语句模式记录日志,执行什么命令,就记录什么命令。(如:使用 update 更新100行数据,SBR模式就只会记录此 update 语句)
- row:又称RBR模式,记录数据行的变化。(如:使用 update 更新100行数据,RBR模式会记录这100行数据的变化)
- mixed:又称MBR模式,是以上两种模式的混合使用
TIP:SBR和RBR模式的区别
SBR:可读性较强,对于范围操作,日志量少,因为只记录SQL语句。但是可能会出现记录不准确的情况。如:
若是对一个表中插入数据insert into t1 values(1,'zs',now());此时now()函数代表此时的时间。又因为二进制日志主要用于恢复数据,若是
后用insert into t1 values(1,'zs',now())恢复数据时,now()函数的值就会发生改变了。当然还有其它情况导致记录不准确的情况
RBR:可读性较弱,对于范围操作,日志量大,但是不会出现记录错误。(高可用环境中的主要使用RBR模式)
4、二进制日志记录单元
二进制日志记录的最小单元是"事件"(event),即二进制日志是一个事件一个事件进行记录的。对于 DDL和DCL 语句每一个语句就是一个事件,如:create database xxx;对于DML语句,一个事务中包含了多个语句,每一个语句也是一个事件。如:
mysql>begin; //事件1
mysql>a; //事件2
mysql>b; //事件3
mysql>commit; //事件4
二进制日志中每一个事件都有开始和结束号码,主要方便我们从日志中截取我们想要的日志事件
5、二进制日志的管理
查看二进制日志文件所在位置
db01 [(none)]>show variables like '%log_bin%';
+---------------------------------+------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------+
| log_bin | ON |
| log_bin_basename | /data/mysql/binlog/mysql-bin |
| log_bin_index | /data/mysql/binlog/mysql-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+------------------------------------+
6 rows in set (1.32 sec)
"log_bin"参数查看二进制日志是否开启
"log_bin_basename"参数查看二进制日志文件的路径
6、查看所有已存在的二进制日志
mysql>show binary logs; //查看本实例中已经存在多个少个二进制日志
mysql>flush logs; //滚动一个新的日志
mysql>show master status; //查看正在使用的二进制日志文件的相关信息
7、查看二进制日志事件
mysql> create database logbin charset utf8mb4;
mysql> use logbin
mysql> create table t1(id int);
mysql> insert into t1 values(1);
mysql> show master status ; /查看正在使用的二进制日志
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000004 | 501 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
mysql> show binlog events in 'mysql-bin.000004'; 查看mysql-bin.000004二进制文件中的事件
mysql> show binlog events in 'mysql-bin.000004' limit 5;
8、查看二进制日志内容
[root@db01 binlog]# mysqlbinlog mysql-bin.000004 //**当无法进入MySQL系统时,可以在Linux命令行模式下使用mysqlbinlog查看mysql二进制日志文件**
[root@db01 binlog]# mysqlbinlog --base64-output=decode-rows -vvv mysql-bin.000004 //因为对于DML语句,二进制日志记录的格式:binlog_format参数默认是rows模式,可读性很差,所以需要使用mysqlbinlog命令的--base64-output=decode-rows参数来进行翻译。
[root@db01 binlog]# mysqlbinlog -d haoge mysql-bin.000004 //“-d”参数:用于显示指定数据库名的相关事件;binlog无法以表为单位进行显示相关事件。
9、通过binlog恢复数据
(1)模拟数据
mysql> create database haoge charset utf8mb4;
mysql> use haoge;
mysql> create table t1(id int);
mysql> insert into t1 values(1);
mysql> commit; //只有提交,事务才算结束,数据才算是插入成功。
(2)模拟故障
mysql> drop database haoge;
(3)分析和截取binlog
mysql> show master status ; --->确认使用的是哪一个日志
mysql> show binlog events in 'mysql-bin.000004' ; --->查看事件,找到要恢复的数据的起点和终点
说明: 找到起点和终点,进行截取
[root@db01 ~]#mysqlbinlog --start-position=823 --stop-position=1420 /data/binlog/mysql-bin.000004 >/tmp/bin.sql
(4)恢复数据
mysql> set sql_log_bin=0; --->临时关闭二进制日志功能,避免恢复数据时产生的新日志,因为使用binlog来恢复数据就是将以前的语句拿来重新执行一遍,若是依旧让binglog把这些事件记录下来,就会造成日志冗余,也不方便以后的查阅。
mysql> source /tmp/bin.sql
mysql> set sql_log_bin=1; set sql_log_bin=1; --->改回来
10、二进制日志清理
(1)自动清理
在配置文件"/etc/my.cnf"中配置 expire_logs_days 参数
例如:
[mysqld]
expire_logs_days=15 //配置成功后,MySQL就会自动清理超过15天的binlog。 设置依据:至少1轮公司全备周期长度的过期时间
(2)手动清理
mysql>purge binary logs to 'mysql-bin.000035'; //表示删除mysql-bin.000035之前所有的二进制日志文件
mysql>purge binary logs before '2021-03-03 10:10:10'; //表示删除2021-03-03 10:10:10时间点之前的所有二进制日志文件
mysql>purge binary logs before date_sub(now(),interval 3 day); //清理3天前binlog日志文件
mysql>reset master; //重置所有的binlog日志文件
TIP:"reset master"和"purge binary logs"的不同点
1、reset master会移除index文件中列出的所有的二进制日志文件,并创建一个新的空的日志文件,从".000001"重新开始。purge binary logs 也会移除index文件中的指定的二进制日志文件,但是并不会从".000001"开始,而是跟着之前的顺序继续增加。
2、reset master 不要再slave还在运行的时候执行。purge binary logs命令可以在slave还在运行的时候执行。
reset master命令会锁住所有对象,并且阻塞数据库连接。如果binlog文件较多,reset master操作可能会占用很多时间。
binlog的gtid记录模式管理
对于binlog中的每一个事务,都会生成一个GTID号。注意要区别事件号,事件号是二进制日志中针对最小存储单元事件的,二进制日志中每一个事件都有自己的起始事件号和结束事件号。
对于DDL、DCL,一个SQL语句就是一个事务,就会有一个GTID号
对于DML语句来讲,begin到commit,才是一个完整的事务,整个事务拥有一个GTID号。
1、GTID的组成
GTID又两部分组成:server_uuid:TID
其中server_uuid是指设备唯一编号;TID是指事务的编号,是一个自增长的数据,从1开始。
例如:
d60b549f-9e10-11e9-ab04-000c294a1b3b:1-15
2、GTID的开启和配置
vim /etc/my.cnf
gtid-mode=on GTID的开启
enforce-gtid-consistency=true 强制GTID一致性
tip:gtid开启后只会影响之后的binlog。
3、基于GTID、binlog恢复数据
查看事务的GTID的方式和查看二进制日志事件的方式是一样的,在此不再赘述。
(1)截取日志
[root@db01 ~]# cd /data/binlog/
[root@db01 binlog]# mysqlbinlog --include-gtids='d60b549f-9e10-11e9-ab04-000c294a1b3b:1-3' mysql-bin.000005 >/tmp/gtid.sql
(2)数据恢复
mysql> set sql_log_bin=0;
mysql> source /tmp/gtid.sql
mysql> set sql_log_bin=1;
(3)恢复过程报错
ERROR 1049 (42000): Unknown database 'gtid'
Query OK, 0 rows affected (0.00 sec)
ERROR 1046 (3D000): No database selected
为什么报错?
因为幂等性的检查,binlog中已经存在1-3gtid的时间了,所以系统认为就不需要再做一遍了,所以就报错.
tip:
GTID的幂等性:即如果拿着有GTID的binlog去恢复数据时,会先检查当前系统中是否有相同的GTID号,存在相同的GTID号的话就会自动跳过。
(4)正确截取日志的做法
[root@db01 binlog]# mysqlbinlog --skip-gtids --include-gtids='d60b549f-9e10-11e9-ab04-000c294a1b3b:1-3' mysql-bin.000005 >/tmp/gtid.sql
--skip-gtids :作用:在导出时,忽略原有的gtid信息,恢复时生成最新的gtid信息
--include-gtids:截取指定范围的日志
例如:--include-gtids='d60b549f-9e10-11e9-ab04-000c294a1b3b:6','d60b549f-9e10-11e9-ab04-000c294a1b3b:8'
--exclude-gtids:截取指定范围之外的日志
例如:--exclude-gtids='d60b549f-9e10-11e9-ab04-000c294a1b3b:6','d60b549f-9e10-11e9-ab04-000c294a1b3b:8'
慢日志(slow-log)
一、生成实验数据
原理:SQL蠕虫复制(这种生数据方式同样使用于数据表中有主键的情况,但是主键不能蠕虫复制)
insert into goods(status,name) select status,name from goods;
当然也可以通过循环函数蠕虫复制更多的数据:
DELIMITER $$
CREATE PROCEDURE test()
BEGIN
DECLARE var INT DEFAULT 1;
WHILE(var<50) DO
INSERT INTO goods(STATUS,NAME) SELECT STATUS,NAME FROM goods;
SET var=var+1;
END WHILE;
END
$$
DELIMITER;
CALL test();
若是var值循环的次数太多,可能会导致数据库系统卡死,可通过"kill thread_id"命令杀死对应的会话
例如:
db01 [test]>show processlist;
+----+------+----------------+------+---------+-------+--------------+--------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+----------------+------+---------+-------+--------------+--------------------------------------------------------------+
| 3 | root | x.x.x.x:xxxxx | test | Sleep | 16352 | | NULL |
| 5 | root | localhost | test | Query | 0 | starting | show processlist |
| 6 | root | x.x.x.x:xxxxx | test | Query | 0 | Sending data | insert into goods(status,name) select status,name from goods |
+----+------+----------------+------+---------+-------+--------------+--------------------------------------------------------------+
db01 [test]>kill 6; //执行此命令后将可以将卡死的会话杀掉
二、慢查询日志设置
当语句执行时间较长时,通过日志的方式进行记录,这种方式就是慢查询的日志。
- 临时开启慢查询日志(如果需要永久开启,则需要更改配置文件)
mysql>set global slow_query_log = on;
tip:如果想关闭慢查询日志,只需要执行 "set global slow_query_log = off"
- 临时设置慢查询时间临界点 查询时间高于这个临界点的都会被记录到慢查询日志中
mysql>set long_query_time=1; //表示所有执行时间超过1秒的SQL语句都会被记录到慢查询日志中
- 设置慢查询存储的方式
db01 [test]> set global log_output = file;
db01 [test]>show variables like '%log_output%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output | FILE |
+---------------+-------+
tip:可以看到,我这里设置为了"file",就是说我的慢查询日志是通过file方式存储的,默认存储方式是none。我们可以将此参设置
为"table"或"file",如果设置为"table",则慢查询信息会保存到mysql库下的slow_log表中。
4 查询慢查询日志的开启状态和慢查询日志存储的位置
db01 [test]>show variables like '%quer%';
+----------------------------------------+--------------------------------+
| Variable_name | Value |
+----------------------------------------+--------------------------------+
| binlog_rows_query_log_events | OFF |
| ft_query_expansion_limit | 20 |
| have_query_cache | YES |
| log_queries_not_using_indexes | OFF |
| log_throttle_queries_not_using_indexes | 0 |
| long_query_time | 10.000000 |
| query_alloc_block_size | 8192 |
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 1048576 |
| query_cache_type | OFF |
| query_cache_wlock_invalidate | OFF |
| query_prealloc_size | 8192 |
| slow_query_log | OFF |
| slow_query_log_file | /data/mysql/data/db01-slow.log |
+----------------------------------------+--------------------------------+
参数说明:
slow_query_log:是否已经开启慢查询功能
slow_query_log_file:慢查询日志文件路径
long_query_time:超过多少秒的查询就写入日志
log_queries_not_using_indexes:如果设置为NO,则会记录所有没有利用索引的查询(性能优化时开启此项,平时不要开启)
三、对慢查询日志进行分析
我们通过查看慢查询日志可以发现,里面的记录方式很乱。数据量大的时候,可能一天会产生几个G的日志,根本没有办法去清晰明了的分析。所以这里我们采用工具进行分析。
- 使用mysqldumpslow进行分析【第一种方式】
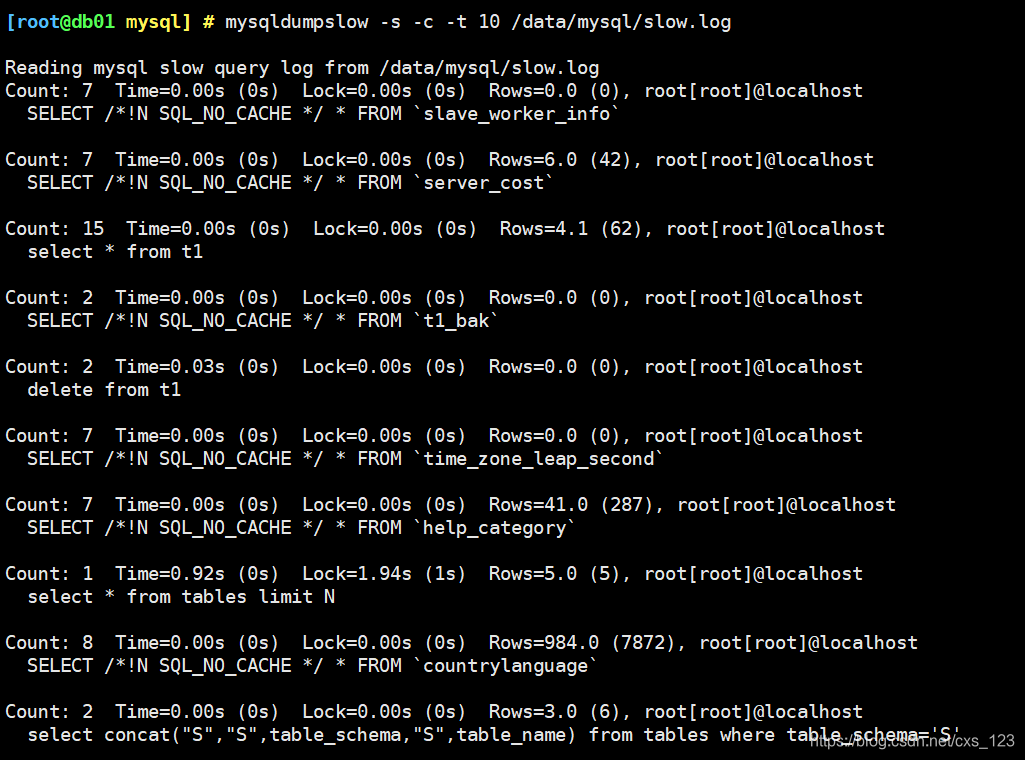
tip:
mysqldumpslow -s -c -t 10 /data/mysql/slow.log
"-s参数":指定排序
"-c参数":表示计数
所以"-s c"表示按照次数排序
"-t 10":表示top 10 取前10个
- 使用pt-query-digest工具进行分析
mysqldumpslow是MySQL安装后就自带的慢日志分析工具,但是pt-query-digest却不是MySQL自带的。如果想要使用pt-query-digest进行慢查询日志的分析,则需要自己安装pt-query-digest。pt-query-digest工具相较于mysqldumpslow功能多一点。
(1)安装
[root@db01 ~] # yum install perl-DBI perl-DBD-MySQL perl-Time-HiRes perl-IO-Socket-SSL perl-Digest-MD5 //先安装 percona-toolkit所需要的依赖包
从percona官网上获取自己需要的版本安装包:https://www.percona.com/downloads/percona-toolkit/LATEST/
将安装包下载到本地后,再上传到Linux系统中。
[root@db01 ~] # rpm -ivh percona-toolkit-3.2.1-1.el7.x86_64.rpm //安装percona-toolkit
percona-toolkit服务安装好之后,就可以使用 pt-query-digest 工具进行慢日志分析了
(2)pt-query-digest语法及重要选项
pt-query-digest [OPTIONS] [FILES] [DSN]
--create-review-table 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建。
--create-history-table 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建。
--filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
--limit 限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
--host mysql服务器地址
--user mysql用户名
--password mysql用户密码
--history 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
--review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中。
--output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
--since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
--until 截止时间,配合—since可以分析一段时间内的慢查询。
(3)分析pt-query-digest输出结果
第一部分:总体统计结果
Overall:总共有多少条查询
Time range:查询执行的时间范围
unique:唯一查询数量,即对查询条件进行参数化以后,总共有多少个不同的查询
total:总计 min:最小 max:最大 avg:平均
95%:把所有值从小到大排列,位置位于95%的那个数,这个数一般最具有参考价值
median:中位数,把所有值从小到大排列,位置位于中间那个数
# 该工具执行日志分析的用户时间,系统时间,物理内存占用大小,虚拟内存占用大小
# 340ms user time, 140ms system time, 23.99M rss, 203.11M vsz
# 工具执行时间
# Current date: Fri Nov 25 02:37:18 2016
# 运行分析工具的主机名
# Hostname: localhost.localdomain
# 被分析的文件名
# Files: slow.log
# 语句总数量,唯一的语句数量,QPS,并发数
# Overall: 2 total, 2 unique, 0.01 QPS, 0.01x concurrency ________________
# 日志记录的时间范围
# Time range: 2016-11-22 06:06:18 to 06:11:40
# 属性 总计 最小 最大 平均 95% 标准 中等
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# 语句执行时间
# Exec time 3s 640ms 2s 1s 2s 999ms 1s
# 锁占用时间
# Lock time 1ms 0 1ms 723us 1ms 1ms 723us
# 发送到客户端的行数
# Rows sent 5 1 4 2.50 4 2.12 2.50
# select语句扫描行数
# Rows examine 186.17k 0 186.17k 93.09k 186.17k 131.64k 93.09k
# 查询的字符数
# Query size 455 15 440 227.50 440 300.52 227.50
第二部分:查询分组统计结果
Rank:所有语句的排名,默认按查询时间降序排列,通过–order-by指定
Query ID:语句的ID,(去掉多余空格和文本字符,计算hash值)
Response:总的响应时间
time:该查询在本次分析中总的时间占比
calls:执行次数,即本次分析总共有多少条这种类型的查询语句
R/Call:平均每次执行的响应时间
V/M:响应时间Variance-to-mean的比率
Item:查询对象
# Profile
# Rank Query ID Response time Calls R/Call V/M Item
# ==== ================== ============= ===== ====== ===== ===============
# 1 0xF9A57DD5A41825CA 2.0529 76.2% 1 2.0529 0.00 SELECT
# 2 0x4194D8F83F4F9365 0.6401 23.8% 1 0.6401 0.00 SELECT wx_member_base
第三部分:每一种查询的详细统计结果
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应
Databases:数据库名
Users:各个用户执行的次数(占比)
Query_time distribution :查询时间分布, 长短体现区间占比,本例中1s-10s之间查询数量是10s以上的两倍。
Tables:查询中涉及到的表
Explain:SQL语句
# Query 1: 0 QPS, 0x concurrency, ID 0xF9A57DD5A41825CA at byte 802 ______
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.00
# Time range: all events occurred at 2016-11-22 06:11:40
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 50 1
# Exec time 76 2s 2s 2s 2s 2s 0 2s
# Lock time 0 0 0 0 0 0 0 0
# Rows sent 20 1 1 1 1 1 0 1
# Rows examine 0 0 0 0 0 0 0 0
# Query size 3 15 15 15 15 15 0 15
# String:
# Databases test
# Hosts 192.168.8.1
# Users mysql
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms
# 1s ################################################################
# 10s+
# EXPLAIN /*!50100 PARTITIONS*/
select sleep(2)\G
四、对SQL进行优化
对慢日志分析后,需要对SQL语句进行优化从而缩短执行所需要的时间,建立索引常常是最好的办法。细节可参考此篇文章:传送门
参考文章:
https://blog.csdn.net/xiaoweite1/article/details/80299754
https://blog.csdn.net/m_nanle_xiaobudiu/article/details/79288257














 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









