






计算机毕设
第一篇 基于数据挖掘的学生成绩分析系统
前言
今天介绍的是:基于数据挖掘的学生成绩分析系统
一、数据上传
在上传数据的时候就进行简单的数据清洗
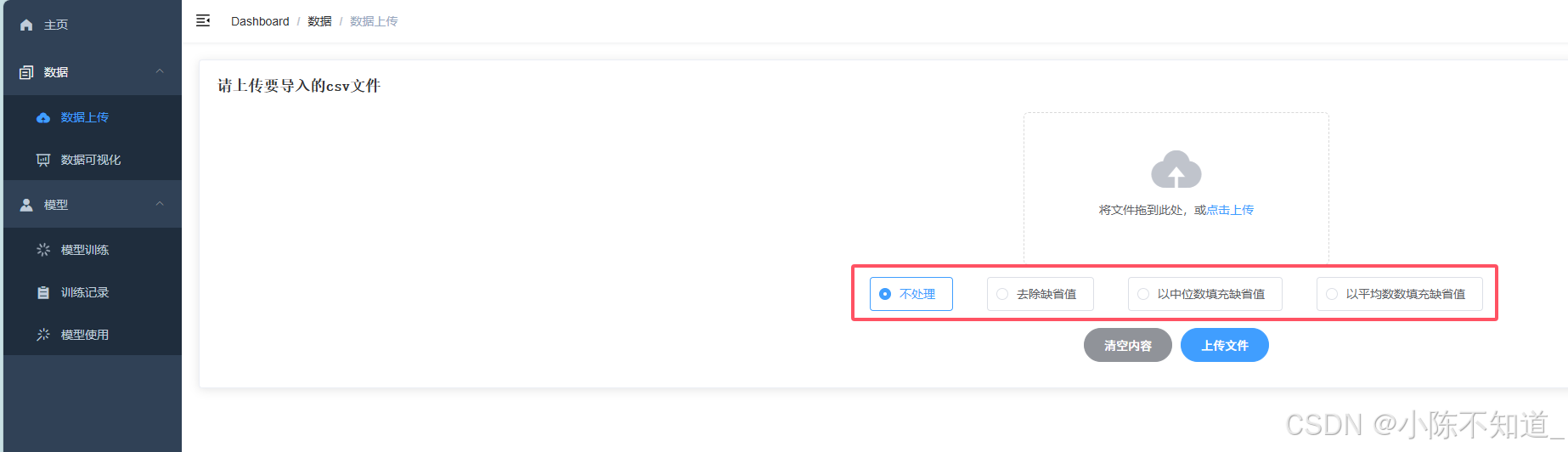
通过前端传来的值 选择性的进行数据清洗
def clean_data(df,integer_value):
# 检查是否有缺失值
has_nan = df.isnull().any().any()
if integer_value == 1:
# 不处理
pass
elif integer_value == 2:
if has_nan:
# 去除缺省值
df = df.dropna()
elif integer_value == 3:
if has_nan:
# 中位数替代缺省值
for col in df.columns:
median_value = df[col].median(skipna=True)
df[col].fillna(median_value, inplace=True)
elif integer_value == 4:
if has_nan:
# 平均数替代缺省值
for col in df.columns:
mean_value = df[col].mean(skipna=True)
df[col].fillna(mean_value, inplace=True)
return df
二、数据可视化
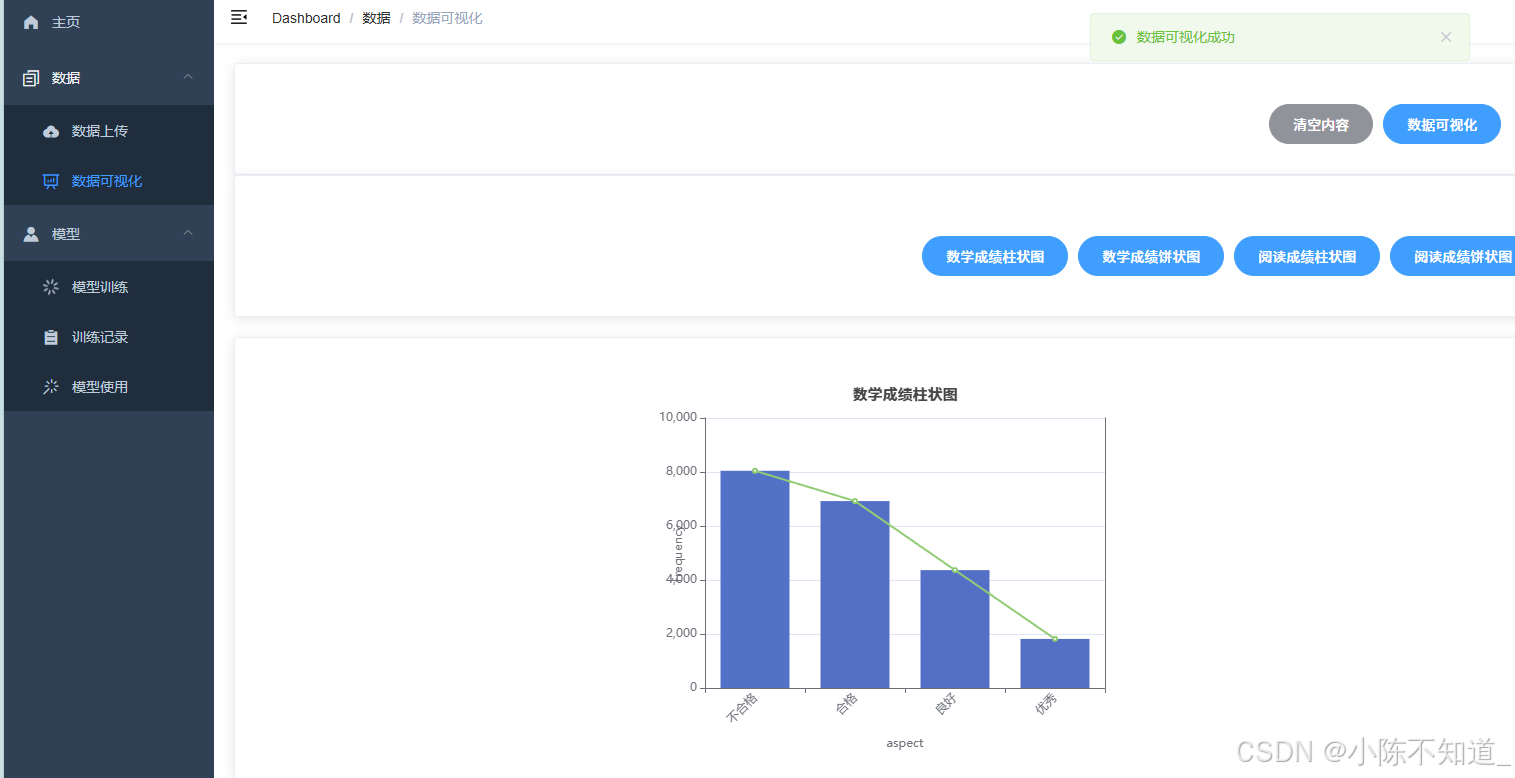
1.用柱状图进行可视化
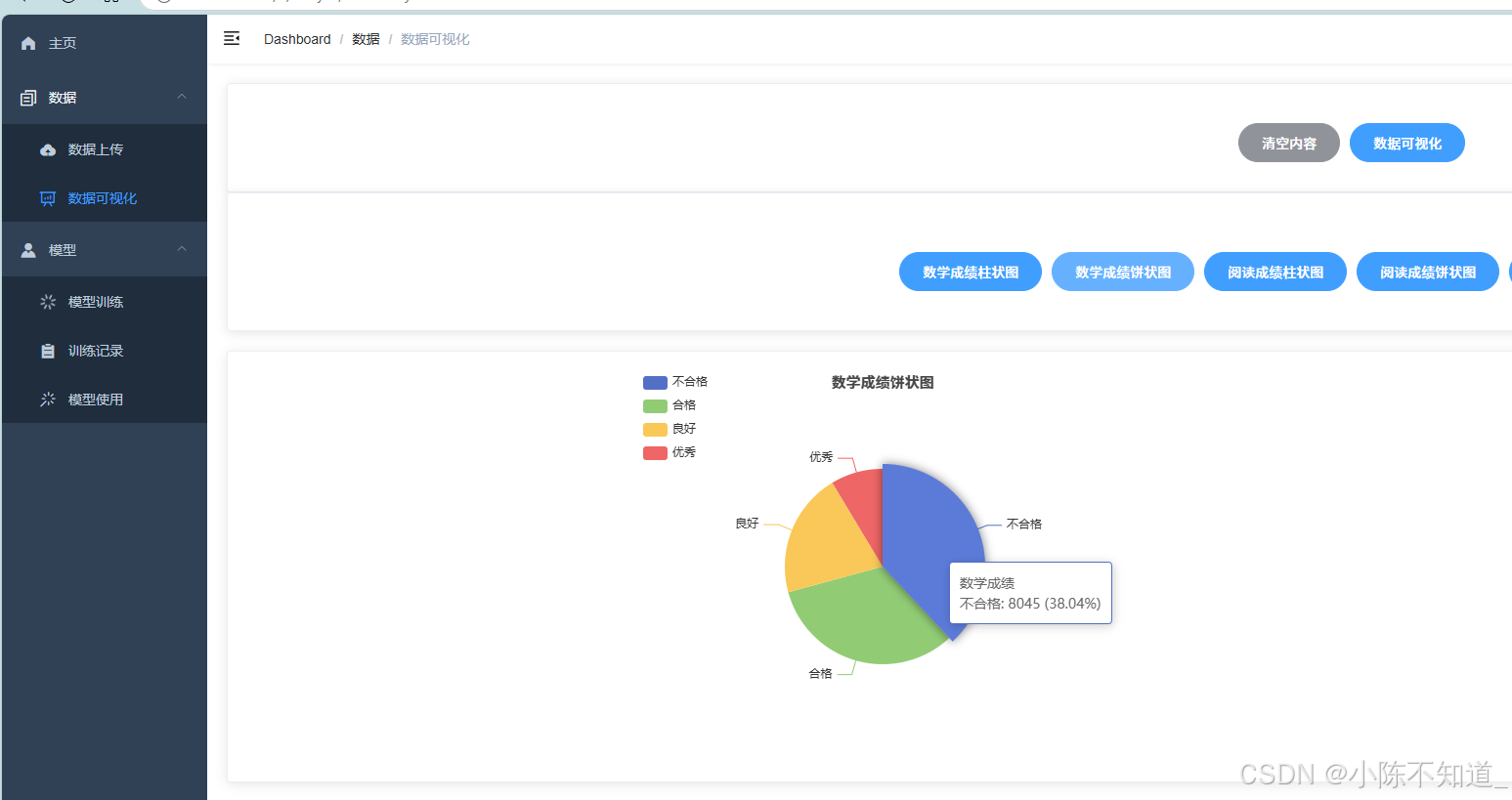
2.用饼状图进行可视化
后端代码示例
def dataAnalyst():
conn = sqlite3.connect('local.db')
query = 'SELECT MathScore, ReadingScore, WritingScore FROM students'
df = pd.read_sql_query(query, conn)
conn.close()
def grade_distribution(scores):
bins = [59, 70, 80, 90, 100]
labels = ['不合格', '合格', '良好', '优秀']
categories = pd.cut(scores, bins, labels=labels, right=False)
return categories.value_counts().sort_index().tolist()
result = {}
for column in ['MathScore', 'ReadingScore', 'WritingScore']:
result[column+'_hist_y_data'] = grade_distribution(df[column])
return result
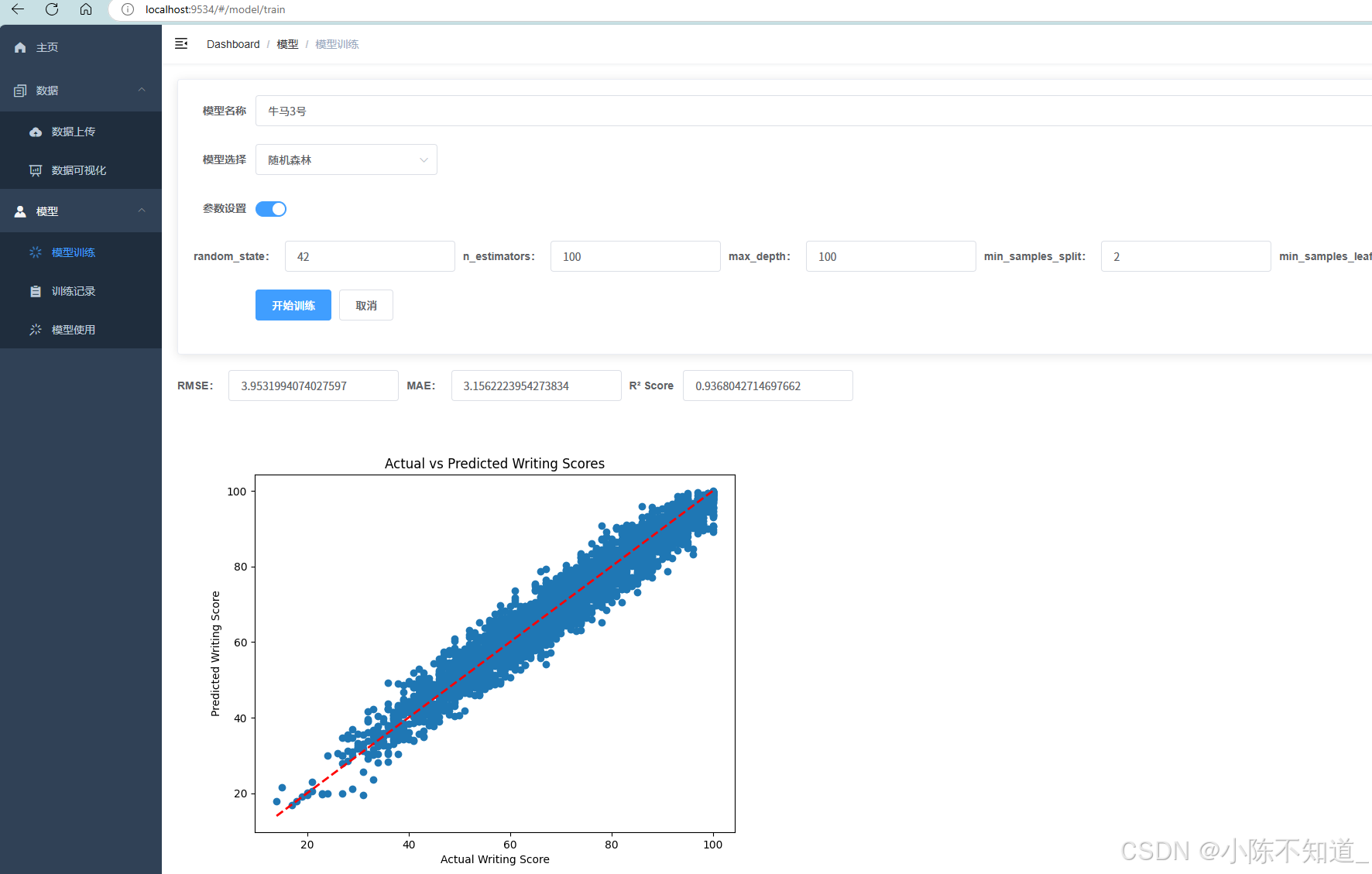
三、模型训练
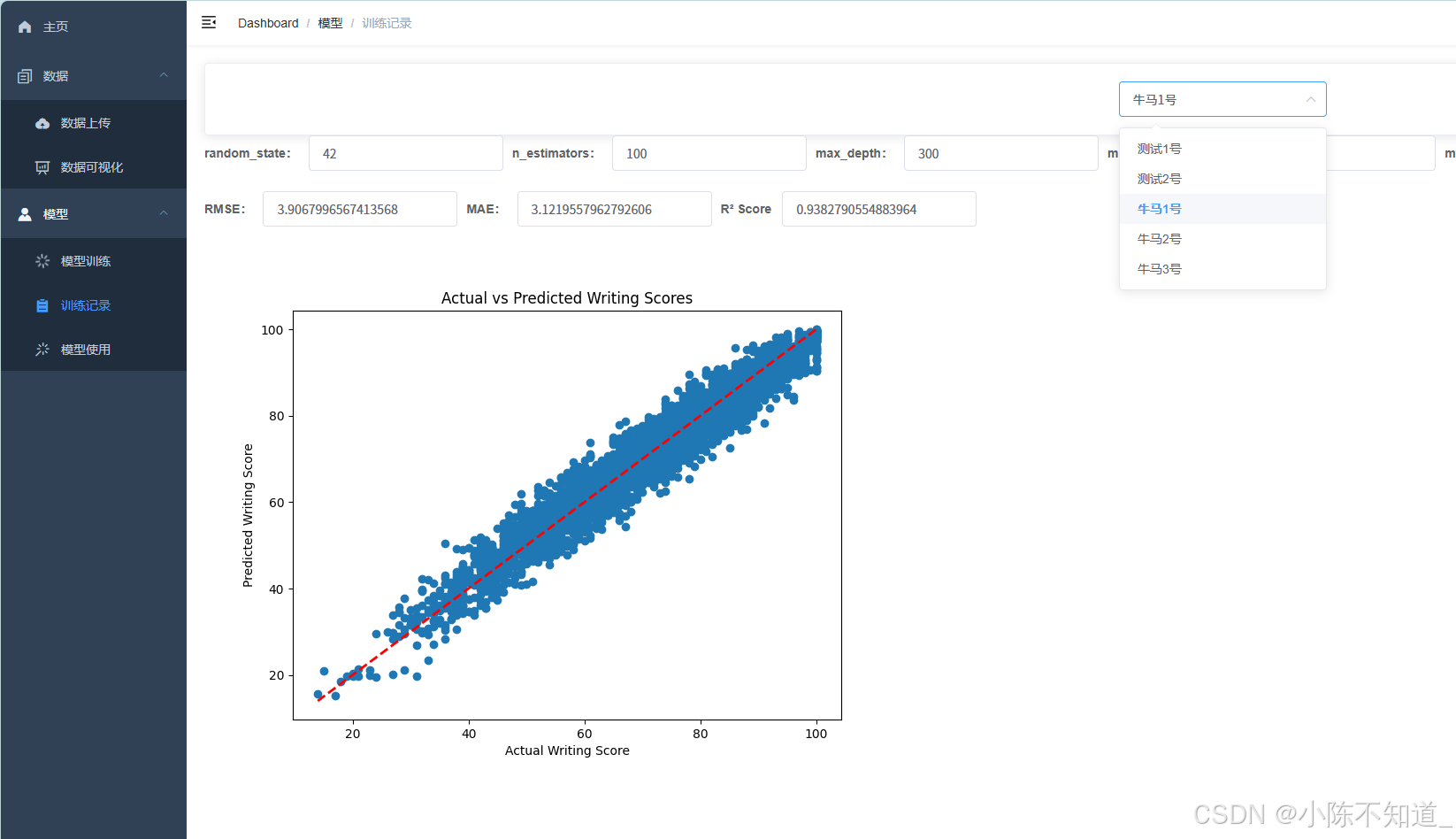
四、模型记录
训练的模型数据都会保存在模型记录里面,方便我们选择最好的模型
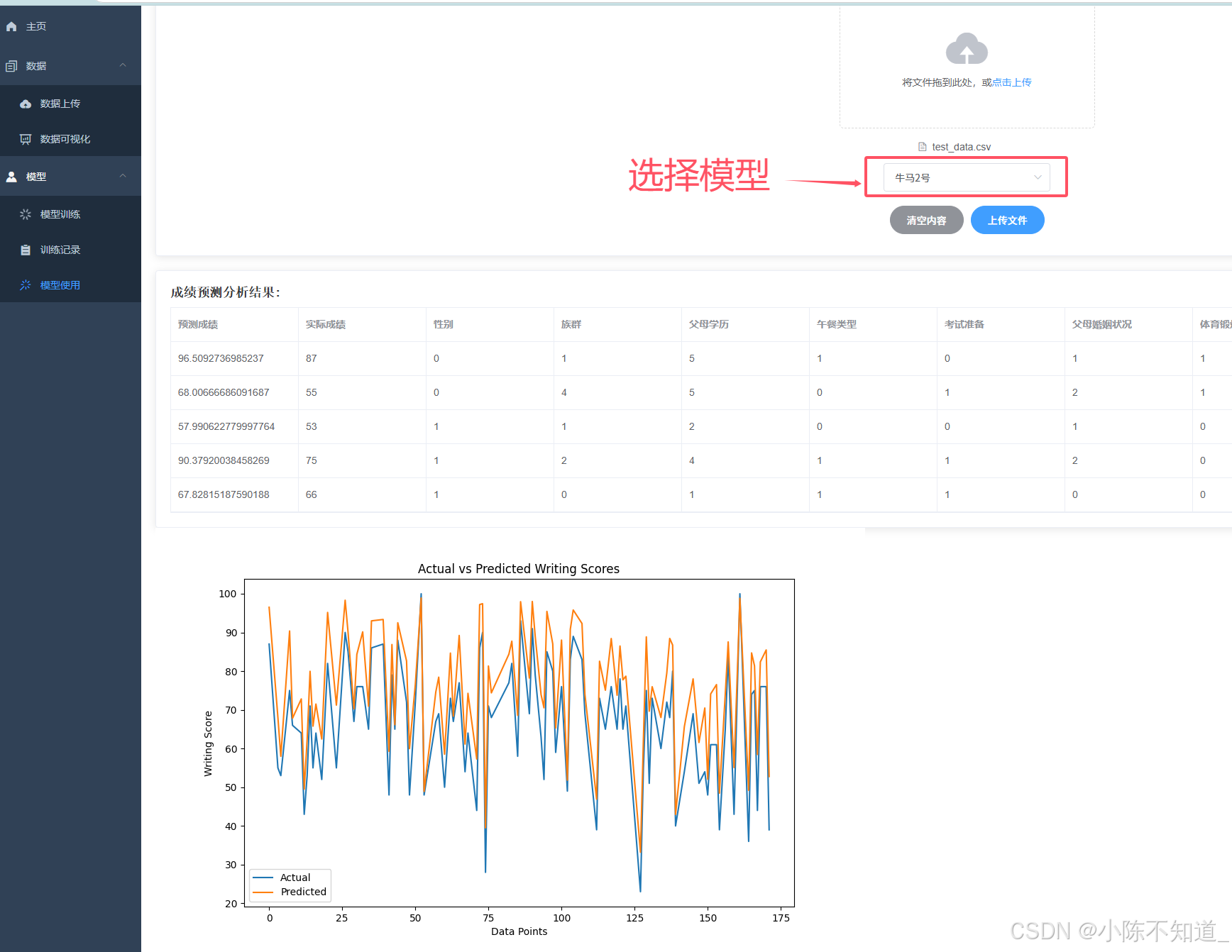
五、模型使用

















 6457
6457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









