






1 什么是KNN算法
KNN(K-Nearest Neighbor)算法,意思是K个最近的邻居,从这个名字我们就能看 出一些KNN算法的蛛丝马迹了。K个最近邻居,毫无疑问,K的取值肯定是至关重要 的。那么最近的邻居又是怎么回事呢?其实啊,KNN的原理就是当预测一个新的 值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
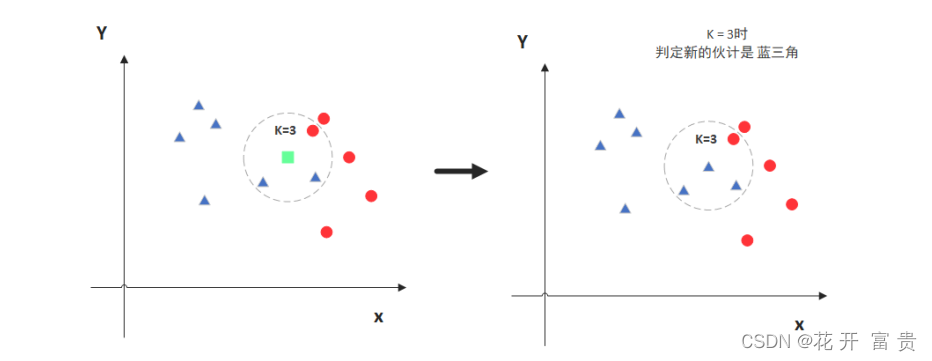
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离 最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中 是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
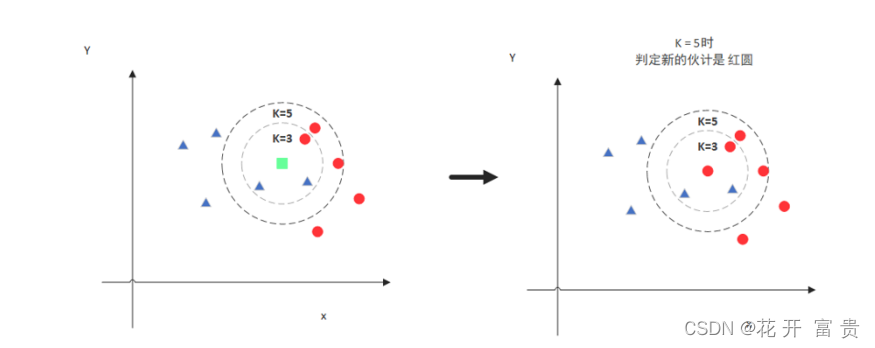
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿 点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
2 算法原理
基本步骤:
1.从训练集合中获取K个离待预测样本距离最近的样本数据;
2.根据获取得到的K个样本数据来预测当前待预测样本的目标属性值。
KNN三要素
1.K值的选择:
对于K值的选择,一般根据样本分布选择一个较小的值,然后通过交叉验证来选择一个比较合适的最终值;当选择比较小的K值的时候,表示使用较小领域中的样本进行预测,训练误差会减小,但是会导致模型变得复杂容易过拟合;当选择较大的K值的时候,表示使用较大领域中的样本进行预测,训练误差会增大,同时会使模型变得简单,容易导致欠拟合;
K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。

2.距离的度量:
一般使用欧氏距离(欧几里得距离或者马氏距离);
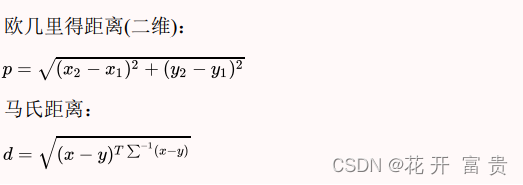
3.决策规则:
在分类模型中,主要使用多数表决法或者加权多数表决法;在回归模型中,主要使用平均值法或者加权平均值法。
3 应用实战
import csv
import random
# 读取数据
with open(".\Prostate_Cancer.csv","r") as f:
render = csv.DictReader(f)
datas = [row for row in render]
# 分组,打乱数据
random.shuffle(datas)
n = len(datas)//3
test_data = datas[0:n]
train_data = datas[n:]
# print (train_data[0])
# print (train_data[0]["id"])
# 计算对应的距离
def distance(x, y):
res = 0
for k in ("radius","texture","perimeter","area","smoothness","compactness","symmetry","fractal_dimension"):
res += (float(x[k]) - float(y[k]))**2
return res ** 0.5
# K=6
def knn(data,K):
# 1. 计算距离
res = [
{"result":train["diagnosis_result"],"distance":distance(data,train)}
for train in train_data
]
# 2. 排序
sorted(res,key=lambda x:x["distance"])
# print(res)
# 3. 取前K个
res2 = res[0:K]
# 4. 加权平均
result = {"B":0,"M":0}
# 4.1 总距离
sum = 0
for r in res2:
sum += r["distance"]
# 4.2 计算权重
for r in res2 :
result[r['result']] += 1-r["distance"]/sum
# 4.3 得出结果
if result['B'] > result['M']:
return "B"
else:
return "M"
# print(distance(train_data[0],train_data[1]))
# 预测结果和真实结果对比,计算准确率
for k in range(1,11):
correct = 0
for test in test_data:
result = test["diagnosis_result"]
result2 = knn(test,k)
if result == result2:
correct += 1
print("k="+str(k)+"时,准确率{:.2f}%".format(100*correct/len(test_data)))
















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









