







 RepVGG是一种基于VGG架构的卷积神经网络,通过结构重参数化技术在训练时使用多分支结构,而在推理时转换为单一路径,实现了性能和速度的良好平衡。论文指出,RepVGG模型在ImageNet上达到了超过80%的top-1精度,同时在GPU上的运行速度比ResNet-50快83%。这种技术通过解耦训练和推理时间的架构,简化推理阶段的模型,提高了推理效率。此外,RepVGG模型的构建不需要自动或手动的架构搜索,而是通过简单的结构实例化,展现出易用性和灵活性。
RepVGG是一种基于VGG架构的卷积神经网络,通过结构重参数化技术在训练时使用多分支结构,而在推理时转换为单一路径,实现了性能和速度的良好平衡。论文指出,RepVGG模型在ImageNet上达到了超过80%的top-1精度,同时在GPU上的运行速度比ResNet-50快83%。这种技术通过解耦训练和推理时间的架构,简化推理阶段的模型,提高了推理效率。此外,RepVGG模型的构建不需要自动或手动的架构搜索,而是通过简单的结构实例化,展现出易用性和灵活性。
RepVGG: Making VGG-style ConvNets Great Again论文翻译-CVPR2021
论文地址:https://arxiv.org/abs/2101.03697
代码地址:https://github.com/DingXiaoH/RepVGG

摘要
我们提出了一个简单但功能强大的卷积神经网络体系结构,它有一个推理阶段的VGG-like型主体,只有一个由3*3卷积和ReLU组成的堆栈,而训练时间模型具有多分支拓扑。这种训练时间和推理时间体系结构的解耦是通过一种结构重参数化技术实现的,因此该模型被命名为RepVGG。在ImageNet上,据我们所知,RepVGG作为普通模型第一次达到了80%以上的top-1精度。在NVIDIA 1080Ti GPU上,RepVGG模型的运行速度比ResNet-50快83%,比ResNet-101快101%,且具有更高的精度,与最先进的模型如EfficientNet和RegNet相比,显示出良好的精度-速度平衡。代码和训练模型在https://github.com/megvii-model/RepVGG。
Introduction
卷积神经网络(ConvNets)已经成为许多任务的主流解决方案。VGG[30]通过由conv、ReLU、pooling组成的简单架构,在图像识别方面取得了巨大的成功。随着Inception [32,33,31,17], ResNet[10]和DenseNet[15]的出现,大量的研究兴趣转向了良好设计的架构,使得模型越来越复杂。最近一些强大的架构是通过自动[43,28,22]或手动[27]架构搜索,或在基本架构[34]上搜索复合缩放策略获得的。
尽管许多复杂的卷积神经网络比简单的卷积神经网络具有更高的精度,但缺点也很明显。1)复杂的多分支设计(如ResNet中的剩余添加和Inception中的分支连接)使模型难以实现和自定义,降低了推理速度,降低了内存利用率。2)一些组件(例如,Xception[2]和MobileNets[14, 29]中的深度卷积和ShuffleNets中的信道搅乱[23, 40])增加内存访问成本,缺乏各种设备的支持。由于影响推断速度的因素有很多,浮点操作(FLOPs)的数量并不能准确地反映实际速度。虽然一些新的模型比之前的诸如VGG和resnet -18/34/ 50[10]有更低的FLOPs,但它们运行起来可能不会更快(表4)。因此,VGG和ResNets的原始版本仍然在学术界和工业界的现实应用中大量使用。
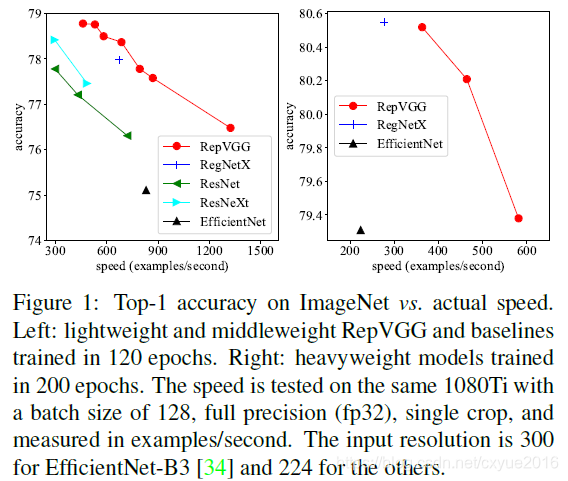
图1:ImageNet上的最高精度与实际速度。左图:轻量级和中量级RepVGG和120个时代训练的基线。右图:重量级模型训练了200个时代。该速度在相同的1080Ti上进行测试,批量尺寸为128,全精度(fp32),单批,以示例/秒进行测量。effentnet - b3[34]的输入分辨率为300,其余[34]的输入分辨率为224。
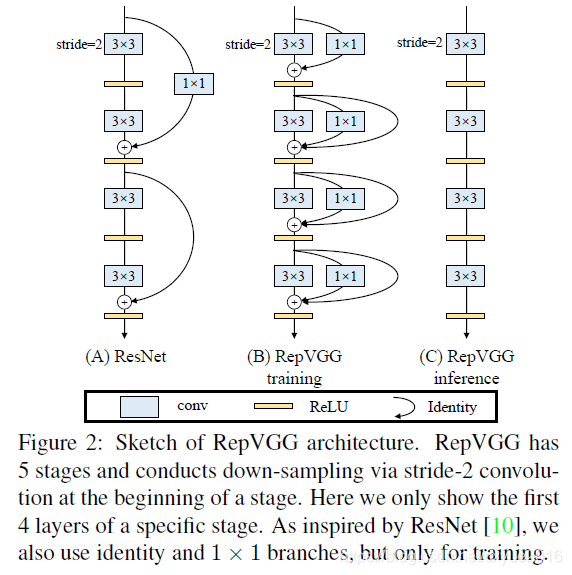
图2:RepVGG基础框架。RepVGG有5个阶段,在阶段开始时通过stride-2卷积进行下行采样。这里我们只展示第一个特定阶段的4个层次。受ResNet[10]的启发,我们也使用identity和1*1分支,但只用于训练。
在本文中,我们提出了RepVGG,一个vgg风格的架构,它优于许多复杂的模型(图1).。RepVGG具有以下优势:
- 该模型具有VGG-like的平面(也称为前馈)拓扑结构没有任何分支。也就是说,每一层都将其上一层的输出作为输入,并将输出输入到下一层。
- 模型的主体只使用3*3 卷积和ReLU激励函数。
- 具体的架构(包括特定的深度和层宽)实例化时不需要自动搜索[43]、手动细化[27]、复合缩放[34],或者其他繁重的设计。
普通模型要达到与多分支架构相当的性能水平是很有挑战性的。一种解释是多分支拓扑结构,例如ResNet,使模型成为众多浅模型[35]的隐式集合,因此训练一个多分支模型可以避免梯度消失的问题。
由于多分支体系结构的优点都是用于训练,而缺点则不是用于推理,因此我们提出通过结构重参数化将训练时间的多分支体系结构和推理时间的普通体系结构解耦,这意味着通过转换其参数将体系结构从一个转换为另一个。具体来说,一个网络结构是与一组参数耦合的,例如,一个卷积层用一个四阶核张量来表示。如果将某一结构的参数转换成另一结构耦合的另一组参数,我们就可以将前者等效为后者,从而改变整个网络结构。
具体来说,我们使用identity和1*1的分支构建训练时的RepVGG,这是受到ResNet的启发,但以不同的方式,可以通过结构重参数化删除分支(图2、4)。训练后,我们用简单代数来执行转换,一个identity分支可以被视为一个退化的1*1 卷积,而后者可以进一步被视为退化的3*3卷积,这样我们可以构造一个简单的3*3内核与原有的训练参数3*3内核、identity、1*1分支和批处理规范化(BN)[17]层。因此,转换后的模型有一堆3*3的卷积层,这些层被保存起来用于测试和部署。
值得注意的是,推理时间的RepVGG只涉及一种类型的操作:33的卷积和ReLU,这使得RepVGG在gpu等通用计算设备上运行速度很快。更好的是,RepVGG允许专用硬件实现更高的速度,因为考虑到芯片大小和功耗,我们需要的操作类型越少,我们可以集成到芯片上的计算单元就越多。也就是说,专门用于RepVGG的推理芯片可以拥有大量的33-ReLU单元和更少的内存单元(因为简单拓扑是内存经济的,如图3所示)。我们的贡献总结如下。
- 我们提出了RepVGG,一种简单的架构,与最先进的技术相比,具有良好的速度-精度平衡。
- 我们提出使用结构重参数化来解耦训练时间多分支拓扑和推理时间简单结构。
- 我们已经证明了RepVGG在图像分类和语义分割方面的有效性,以及实现的效率和易用性。
2. Related Work
2.1. From Single-path to Multi-branch(从单路径到多分支)
在VGG[30]将ImageNet分类的top-1准确率提高到70%以上之后,在使ConvNets变得复杂以达到高性能方面有很多创新,如当代的google[32]及以后的版本Inception模型[33,31,17]采用了精心设计的多分支架构,ResNet[10]提出了简化的双分支架构,DenseNet[15]通过将低层和大量的高层连接起来,使得拓扑结构更加复杂。神经结构搜索(Neural architecture search, NAS)[43,28,22,34]和人工设计空间设计[27]可以生成性能更高的卷积网络,但代价是大量的计算资源或人力。nas生成模型的一些大型
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









