







 本文介绍了HiEve,一个大规模数据集,用于复杂事件中的人体运动、姿态和动作理解。HiEve包含创纪录的姿势、动作实例和长轨迹,旨在促进复杂场景下的人工智能技术发展。数据集提供了多人跟踪、姿态估计、姿态跟踪和动作识别等任务,以及一种利用动作信息改进姿态估计的方法。实验表明,HiEve数据集对于现有方法提出了挑战,有助于推动以人为中心的视频分析技术的进步。
本文介绍了HiEve,一个大规模数据集,用于复杂事件中的人体运动、姿态和动作理解。HiEve包含创纪录的姿势、动作实例和长轨迹,旨在促进复杂场景下的人工智能技术发展。数据集提供了多人跟踪、姿态估计、姿态跟踪和动作识别等任务,以及一种利用动作信息改进姿态估计的方法。实验表明,HiEve数据集对于现有方法提出了挑战,有助于推动以人为中心的视频分析技术的进步。
论文翻译 - Human in Events: A Large-Scale Benchmark for Human-centric Video Analysis in Complex Events
论文地址:https://arxiv.org/abs/2005.04490
数据集地址:http://humaninevents.org

ABSTRACT(摘要)
随着现代智慧城市的发展,以人为本的视频分析面临着分析真实场景中各种复杂事件的挑战。复杂事件与密集的人群、反常或集体行为有关。然而,受限于现有视频数据集的规模,很少有人工分析方法报告它们在此类复杂事件上的表现。为此,我们提出了一个新的大规模数据集,名为human -in-Events或HiEve (human -centric video analysis in complex Events),用于理解各种现实事件中的人体运动、姿态和动作,特别是人群和复杂事件。它包含了创纪录的姿势数量( > > > 1M),在复杂事件下最多的动作实例数量( > > > 56k),以及最长时间的轨迹数量之一(平均轨迹长度为 > > > 480帧)。基于此数据集,我们提出了一个增强的姿态估计baseline,利用动作信息的潜力来指导更强大的2D姿态特征的学习。我们证明,该方法能够提高现有的姿态估计pipline在我们的HiEve数据集上的性能。此外,我们进行了大量的实验,将最近的视频分析方法与我们的基线方法结合起来进行基准测试,表明HiEve是一个具有挑战性的数据集,用于以人为中心的视频分析。我们期望该数据集将推动以人为中心的分析和复杂事件理解的尖端技术的发展。该数据集可在http://humaninevents.org上获得。
关键词: 复杂事件,以人为中心的分析,数据集
1 INTRODUCTION(介绍)
智慧城市的发展高度依赖于对多媒体的快速、准确的视觉理解。为了实现这一目标,人们提出了许多以人为中心和事件驱动的视觉理解问题,如人体姿态估计[9],行人跟踪[6],动作识别[10],[11]。
最近,一些公共数据集(如MSCOCO [1], PoseTrack [4], UCF-Crime[8])被提出对上述任务进行基准测试。然而,当它们被应用到诸如吃饭、地震逃生、地铁下车和碰撞等复杂事件的真实场景时,就有一些局限性。首先,大多数基准测试集中在正常或相对简单的场景。这些场景要么有很少的遮挡,要么包含许多容易预测的动作和姿势。第二,现有基准的覆盖范围和规模仍然有限。例如,尽管UCFCrime数据集[8]包含具有挑战性的场景,但它只有粗糙的视频级动作标签,这可能不足以进行细粒度动作识别。同样,尽管MSCOCO[1]和PoseTrack[4]中的姿态标签数量对于遮挡有限的简单场景足够大,但这些数据集缺乏包含拥挤场景和复杂事件的真实场景。
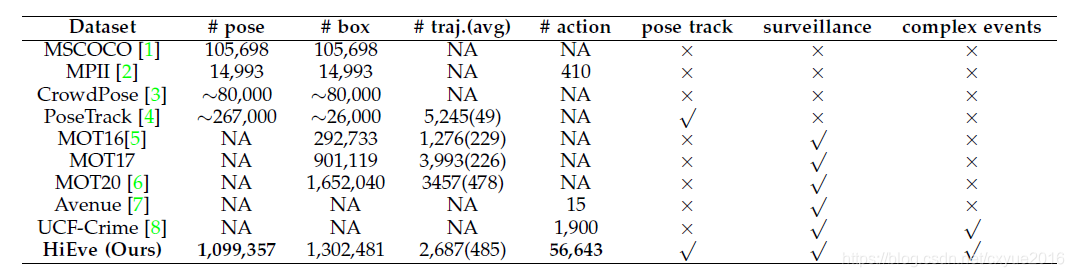
为此,我们提出了一个新的大规模的以人为中心的数据集,名为Human-in-Events (HiEve),用于理解各种现实的复杂事件,特别是拥挤和复杂事件中以人为中心的信息(运动、姿势和动作)层次结构。在所有用于现实人群场景的数据集中,HiEve具有相当大的规模和复杂性,并包含创纪录的姿态数量( > > > 1M)、动作标签( > > > 56k)和长轨迹(平均轨迹长度 > > > 480帧)。与现有的数据集相比,HiEve在更复杂的场景中包含了更全面、更大规模的注释,更适合开发新的以人为中心的分析技术并在现实场景中进行评估。表1根据HiEve数据集的性质和规模提供了与相关数据集的定量比较。
表 1:HiEve 和现有数据集之间的比较。 “NA”表示不可用。 “~”表示近似值。“traj.”表示轨迹,“avg”表示平均轨迹长度。
我们的HiEve数据集的一个主要特征是人类注释的分层和多样化信息。为了充分利用这一特性,我们提出了一种动作引导的姿态估计算法作为我们的baseline方法,该算法通过附加的动作感知信息指导姿态表示学习。实验证明,这种以行动为导向的设计能够提高HiEve数据集上现有最先进的pipline的性能。
此外,我们还建立了一个在线评估服务器,供整个社区使用,以便对保留的测试视频进行及时和可扩展的评估。我们还评估了现有的最先进的解决方案在HiEve上的性能基准,并分析了相应的oracle模型,证明了HiEve是具有挑战性的,并在推进以人为中心的视频分析方面具有巨大的价值。
2 RELATED WORKS AND COMPARISON(相关工作及比较)
2.1 Multi-object Tracking Datasets(多目标跟踪数据集)
与单目标跟踪不同,多目标跟踪并不仅仅依赖复杂的外观模型来跟踪帧内目标。近年来,出现了提供视频序列多对象边界框和轨迹标注的数据集语料库,促进了该领域的发展。PETS[12]是一个早期提出的多传感器视频数据集,它包括人群人数的注释和人群中个人的跟踪。它的序列都是在同一个场景中拍摄的,所以样本比较简单。KITTI[13]跟踪数据集具有车载摄像头的视频,聚焦于街道场景,它拥有2D &3D边界盒和轨迹标注。同时,它的视频角度种类有限。最受欢迎的跟踪评估数据基准是MOT-Challenge[6],它从各种不同的角度显示行人。然而,随着MOT算法的快速发展,以及MOT challenge数据集的规模和复杂性的限制,它不太适合作为各种方法在现实世界复杂场景下跟踪性能的全面、通用的基准。
2.2 Pose Estimation and Tracking Datasets(姿态估计和跟踪数据集)
在过去的几年里,图像中的人体姿态估计取得了很大的进展。对于单人姿态估计,LSP[14]和FLIC[15]是两个最具代表性的基准,前者关注的是体育场景,而后者收集的是好莱坞热门电影序列。与LSP相比,FLIC只标记了10个上体关节,数据规模较小。WAF[16]首次建立了简化关键点和身体定义的多人姿态估计基准。然后,提出了MPII[2]和MSCOCO[1]数据集,利用它们在人体姿态方面的多样性和难度,进一步推进了多人姿态估计任务。特别是MSCOCO被认为是使用最广泛的大规模数据集,在数百个日常活动中有105698个姿态标注。考虑到跟踪任务,PoseTrack[4]构建了一个新的视频数据集,提供多人姿态估计和关节跟踪标注。与PoseTrack类似,最近提出的大规模CG数据集JAT[17]模拟了真实的城市场景,用于人体姿态估计和跟踪。
2.3 Action Recognition Datasets(动作识别数据集)
目前有两种人类动作视频数据集已经成为动作识别任务的标准基准:HMDB-51[18]和UCF-101[19]。HMDB-51主要从电影序列中收集,包含51个动作类。UCF-101是动作类别(101类)和样本数量最多的数据集之一,显著促进了动作识别任务的发展。为了识别现实中的异常行为,提出了Avenue[7]和UCF-Crime[8]。UCFCrime在真实世界的监控视频中注释了13种异常情况,如打斗、事故和抢劫。近年来,为促进视频分析技术的发展和评价,构建了规模更大、对象信息更详细的Kinetics[20]和AVA[21]数据集。然而,这些视频中的大部分内容要么来自戏剧场景,要么来自不拥挤的场景。
2.4 Comparisons(比较)
上述的相关数据集在社区中服务的很好,但现在它们面临着几个局限性:(1)大多数数据集中在正常或简单的场景(如街道、体育场景、单人运动),遮挡较少,对于运动或姿势的预测相对简单。(2)它们的覆盖范围和尺度对最先进算法的评价作用不大。(3)多个以人为中心的视频分析任务需要在多个基准上学习和评估,而以往数据集的注释只包含人类信息的一个方面(姿态、轨迹或动作)。总的来说,与这些数据集相比,我们的数据集具有以下独特的特点:
- HiEve数据集涵盖了广泛的以人为中心的理解任务,包括运动、姿势和动作,而之前的数据集只关注我们任务的一个子集。
- HiEve数据集具有相当大的数据规模,包括目前最大的姿态数量( > > > 1M),最大数量的复杂事件动作标签( > > > 56k),以及最大数量的长期轨迹(平均轨迹长度 > > > 480)。
- HiEve数据集中于各种拥挤复杂事件下的具有挑战性的场景(如用餐、地震逃生、地铁下车、碰撞等),而之前的数据集中大多与正常或相对简单的场景相关。
简而言之,我们的HiEve在各种复杂事件场景中包含了更全面、更大规模的注释,使其更有能力评估现实场景中以人为中心的分析技术。

图1:来自我们的训练集和测试集的不同动作的样本。
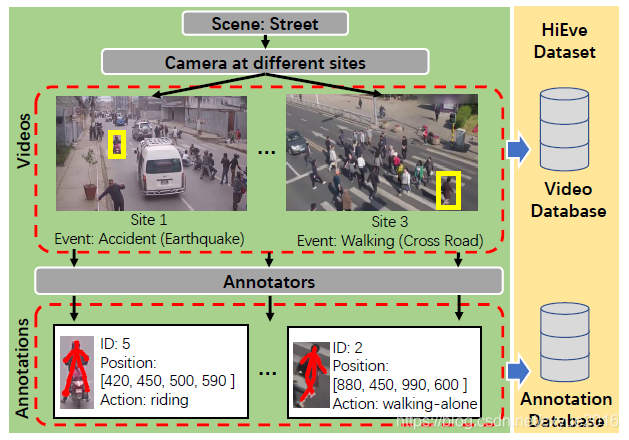
图2:街道场景的HiEve数据集的收集工作流示例;每个场景都包含了在不同地点拍摄的不同类型的事件。

图3:(a)关键点定义(b)来自数据集的示例姿态和边界框注释。
THE HIEVE DATASET(HiEve数据集)
3.1 Collection and Annotation(收集和注释)
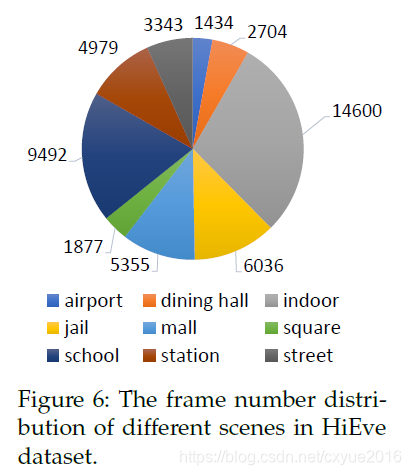
收集。 我们首先选择几个拥挤的地方,有复杂和多样化的活动来收集视频。总共,我们的视频序列收集了9个不同的场景:机场,餐厅,室内,监狱,商场,广场,学校,车站和街道。图6显示了不同场景在HiEve中的帧数。这些视频大多是从我们自己收集的序列中挑选出来的,包含了人与人之间复杂的互动。如图2中的工作流所示,对于每个场景,我们保留在不同地点和不同类型的事件发生的几个视频,以确保场景的多样性。另外,通过人工检查避免了数据冗余。最后,在不同的场景中收集了32个真实的视频序列,每个序列包含一个或多个复杂的事件。这些视频序列被分割为19个和13个视频的训练和测试集,以便两个集覆盖所有场景,但使用不同的摄像机角度或地点。
注释。 在我们的数据集中,边界框、基于关键点的姿势、人类身份和人类动作都是手工标注的。注释过程如下:
首先,我们为整个视频中的每个人标注姿势。与PoseTrack和COCO不同,我们为每个身体标注的姿势包含14个关键点(图3a):鼻子、胸部、肩膀、肘部、手腕、臀部、膝盖、脚踝。特别地,我们跳过了属于以下任何情况的姿态标注:(1)严重遮挡(2)边界框面积小于500像素。图3b给出了一些姿态和边界框注释示例。
其次,我们在一个视频中每20帧注释所有人的动作。对于组操作,我们将操作标签分配给参与该组活动的每个组成员。我们总共定义了14个动作类别:独自行走、一起行走、独自奔跑、一起奔跑、骑马、坐着交谈、独自坐着、排队、独自站立、聚集、打斗、摔倒、上下楼梯行走、蹲伏鞠躬。图1显示了HiEve中不同操作的一些示例。最后,对所有注释进行双重检查,以确保其质量。
3.2 HiEve Statistics(HiEve统计)
我们的数据集包含32个视频序列,大部分长度超过900帧。它们的总长度是33分18秒。表1显示了我们的HiEve数据集的基本统计数据:它有49820帧,1,302,481个bounding-box annotation, 2,687个track annotation, 1,099,357个human pose annotation, 56,643个action annotation,是我们所知规模最大的以人为中心的数据集。
为了进一步说明我们的数据集的特征,我们进行以下统计分析。
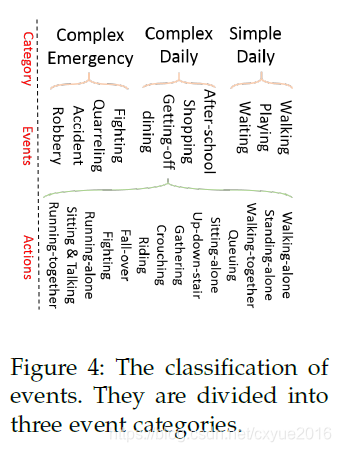
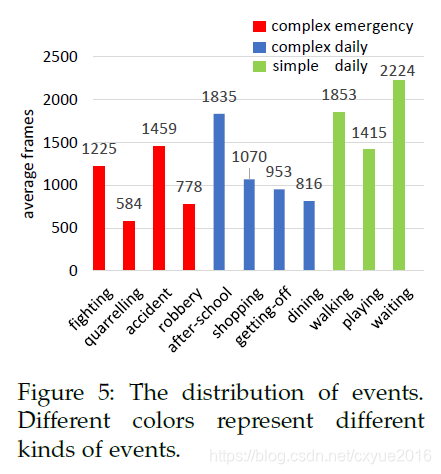
首先,我们分析了不同事件的一些统计信息。在视频内容方面,我们可以将我们的视频序列分成11个事件:打架、争吵、事故、抢劫、放学、购物、下车、吃饭、散步、玩耍、等待。每个事件包含不同数量的参与者和动作类型。然后,根据这些事件的复杂性,我们进一步将这些事件分为三类:复杂的紧急事件、复杂的日常事件和简单的日常事件。类别、事件和动作之间的层次关系如图4所示。我们在图10中展示了上述3个事件的姿态、对象和轨迹的数量,这证明了我们定义的复杂事件具有更以人为中心的信息。此外,图5显示了每个事件的平均帧数,表明我们的HiEve数据集是由复杂事件主导的。
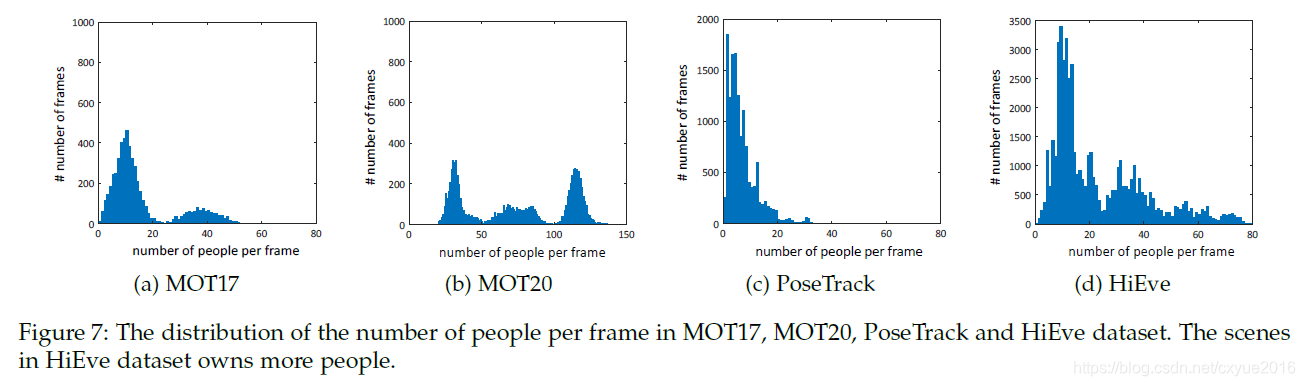
其次,我们在图7中展示了我们的数据集中每帧的人数,这表明我们的视频序列中的场景比MOT17和Pose- Track[4]的人数更多,这使得我们的跟踪任务更加困难。虽然mot - 20[6]收集了一些视频序列与更多的人(多达141人),它只涵盖有限的场景和人类的行动。
第三,我们采用Crowdpose[3]中定义的人群指数来衡量我们数据集的拥挤程度。对于给定的帧,其人群指数(CI)计算为
C I = 1 n ∑ i = 1 n N i b N i a CI =\frac{1}{n}\sum^n_{i=1}\frac{N^b_i}{N^a_i} CI=n1∑i=1nNiaNib
其中n是这个坐标系中的总人数。 N i a N^a_i Nia为来自第i个人类实例的关节数, N i b N^b_i Nib为位于第i个人类实例边界箱内但不属于第i个人类实例的关节数。我们评估了我们的HiEve数据集和广泛使用的姿态数据集MSCOCO[1]和MPII[2]的人群指数分布。图9显示,我们的HiEve数据集更关注拥挤的场景,而其他基准测试主要是不拥挤的场景。这一特点使得我们的数据集上的最先进的方法既可以覆盖简单的情况,也可以忽略拥挤的情况。
第四,我们分析了数据集中没有联系的人类轨迹的比例。没有联系的人体轨迹被定义为由于以下原因在某些帧上边界框不可用的轨迹标注:(1)一个物体暂时离开摄像机视图并在稍后返回。(2)一个对象长期被前景对象或某些障碍严重遮挡,注释者无法给它分配一个近似的边界框(如图14所示)。值得注意的是,这样的数据集PoseTrack
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8364
8364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









