






 本文介绍了3D-open-pose-editor这款工具,用于AI绘画中的手部和身体姿势编辑,包括深度、法线和Canny地图生成。通过实例展示了如何安装、应用和优化出图效果,同时探讨了AIGC技术的未来发展和学习资源。
本文介绍了3D-open-pose-editor这款工具,用于AI绘画中的手部和身体姿势编辑,包括深度、法线和Canny地图生成。通过实例展示了如何安装、应用和优化出图效果,同时探讨了AIGC技术的未来发展和学习资源。
在AI绘画过程中一般对于手部细节比较一言难尽

我们随便来一个身体姿势看看手部
身体姿势
出图效果
emmmm… 姿势有了,但是四肢确实看不了。
今天我们就来彻底解决这些问题!
一 3d-open-pose-editor 介绍
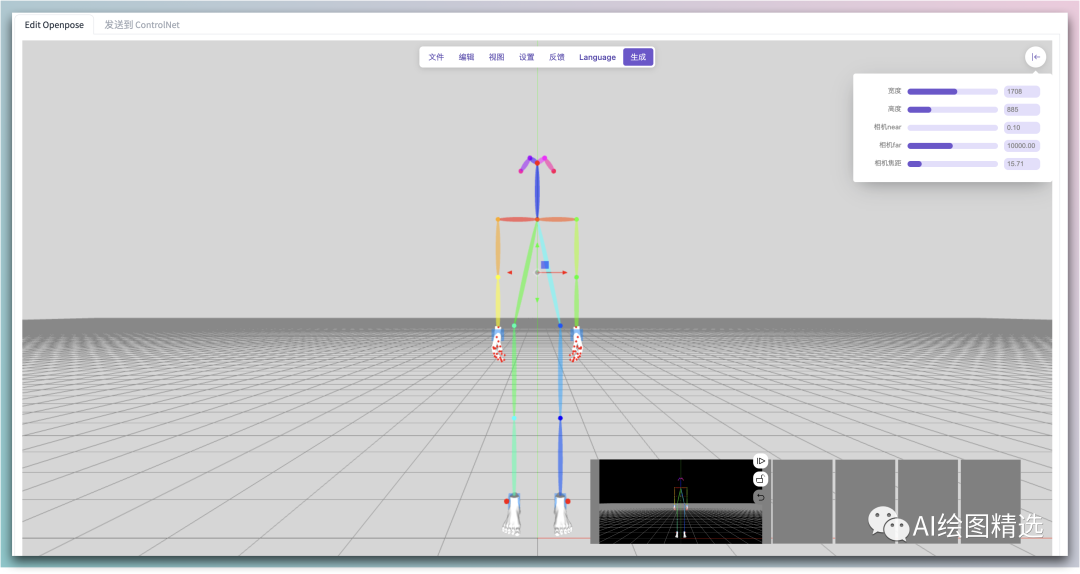
3D open pose editor 功能:
-
姿势编辑: 通过选择关节并使用鼠标旋转编辑 3D 模型的姿势。
-
手部编辑: 通过选择手部骨骼并使用彩色圆圈微调位置来精调手部位置。
-
深度 / 法线 / Canny 地图: 生成和可视化深度、法线和 Canny 地图,以提高 AI 绘图的质量。
-
保存/加载/还原场景: 使用内置的保存和加载功能保存进度并在以后恢复。
-
调整身体参数: 调整各种身体参数,如身高、体重和肢体长度,创建自定义的 3D 模型。
简单来说,可以支持身体姿势和四肢的编辑,并且生成姿势、深度、法线和canny 特征图,一键发送到 文生图/图生图中使用。
二 安装
和其它插件安装方法一致,直接在 拓展菜单中输入地址进行安装,重启 https://github.com/nonnonstop/sd-webui-3d-open-pose-editor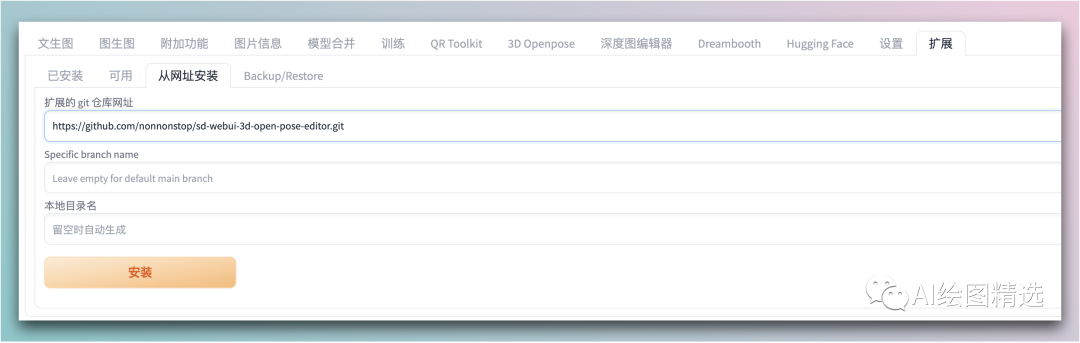
三 应用
我们通过 一个完整的例子来看看效果到底怎么样。
姿势编辑
我们可以通过加载一张图片或者是直接设置随机姿势进入编辑态。

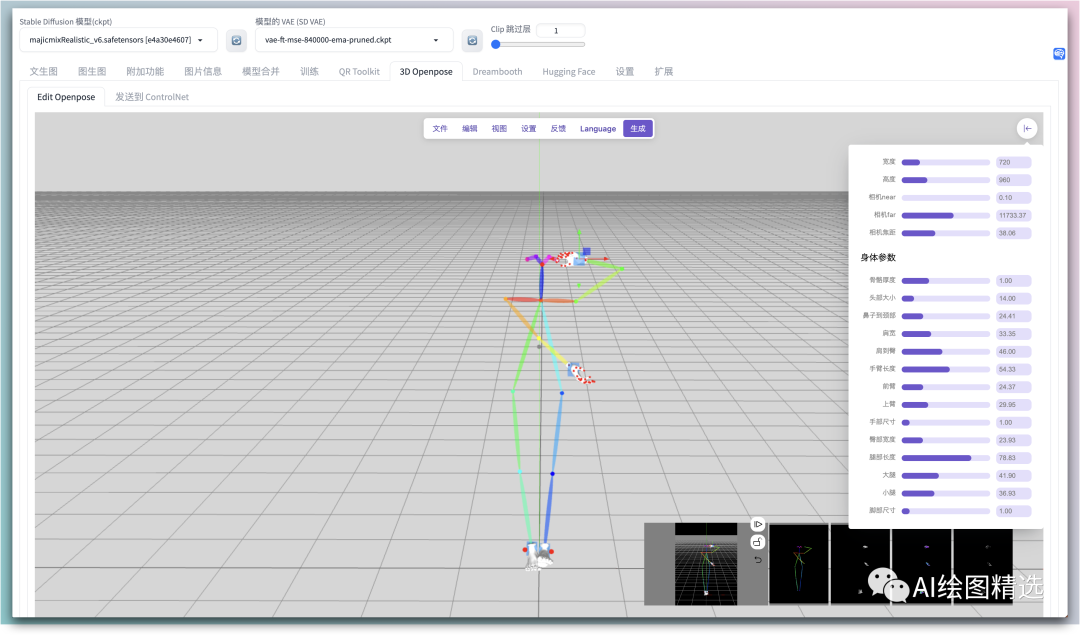
可以通过点击关节处进行编辑姿势。编辑完成后可以点击 生成或这样右下角播放按钮进行生成 姿势图/canny/深度和法线特征图
姿势导入
编辑完成后,可以点击右下角的四张预览图就可以下载到本地了
将下载好的特征图分别放入到不同的 ControlNet 设置中。(建议最多放三个即可,设置的过多出图效果反而很差)
在这我导入了 openpose, canny 和 depth 三个ControlNet
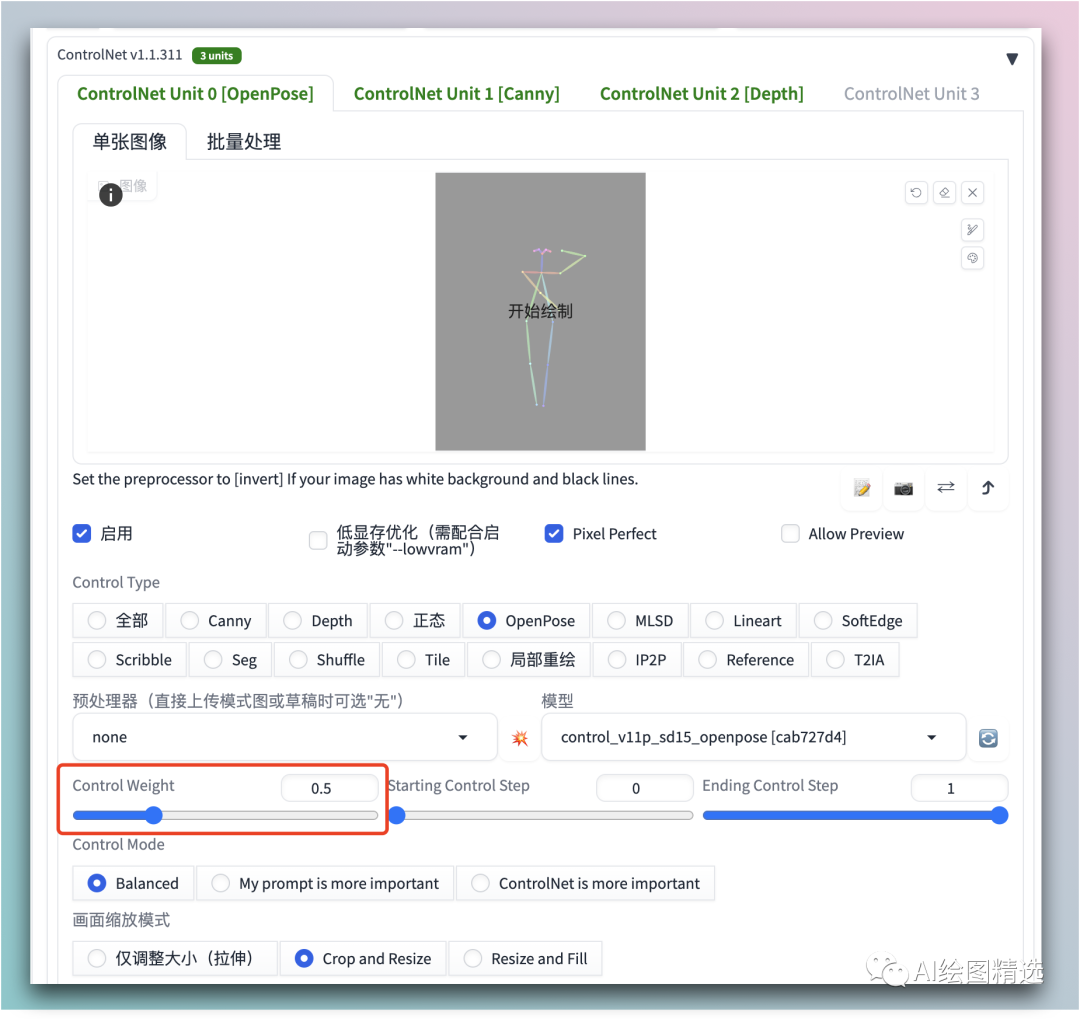
其中:
-
openpose:模型是
control_v11p_sd15_openpose,不需要设置预处理器 -
canny:模型是
control_v11p_sd15_canny,不需要设置预处理器 -
depth:模型是
control_v11p_sd15_depth,不需要设置预处理器
出图
最后来看看出图的效果
整体抽卡的成功率还是很高的。如果希望整体效果更好,特别是手部的细节。那么可以在编辑姿势的时候尽可能的让整个姿势图占到整个图片的大小或者设置更大的分辨率。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除

















 3773
3773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









