







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
本文介绍的关联规则的主要算法,是对我们老师的ppt进行简要的总结。
一、关联分析概述
1.问题背景
最初提出的动机是针对购物篮分析(Market Basket Analysis)问题提出的,其目的是为了发现交易数据库(Transaction Database)中不同商品之间的联系规则。
2.关联规则介绍——事务与规则
事务: 若干项组成的集合tj
项集:所有项的集合I={i1, i2,…, id}
事务集合:所有事务集合T={t1,t2,…, tN}(第一列所有事务的集合)
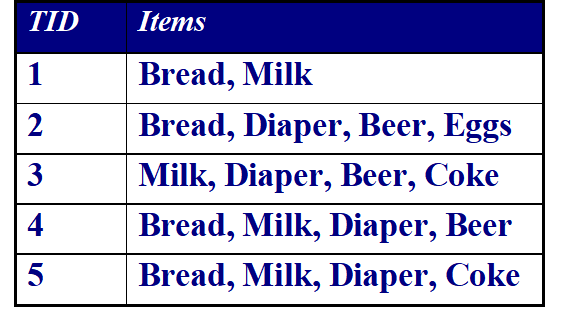
(1)关联规则(Association Rule): 一般记为 X→Y 的形式,用于表示数据内隐含的关联性
关联规则的强度由“三度”控制:支持度、置信度、提升度
1.支持度(Support )
指所有项集中{X,Y}同时出现的项集所占的百分比,即项集中同时含有X和Y 的概率:
![]()
最小支持度:即用户规定的关联规则必须满足的最小的支持度阈值。
频繁项集:支持度大于或等于minsupport的非空项集
2.置信度Confidence
关联规则X→Y的置信度(Confidence),是指包含X和Y的项集数与包含X的项集数之比,即 Confidence(X→Y ) = support(X,Y)/ support(X)易知, Confidence(X→Y ) =P(Y |X).
最小置信度minconfidence: 即用户规定的关联规则必须满足的最小的置信度阈值,它反应了关联规则的最低可靠度。
强关联规则(Strong Association Rule): 同时满足最小支持度(Minsupport)和最小置信度(Minconfidence)的关联规则称为强关联规则
例如:支持度 s:一次交易中同时包含{X 、 Y }的可能性 置信度 c :包含项X 的交易中同时也包含Y的条件概率
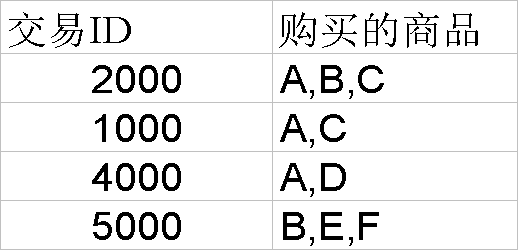
设最小支持度为0.5, 最小可信度为 0.5,
则可得到关联规则 A ---> C (0.5, 0.67) C ---> A (0.5, 1)
3.提升度(list)
重新考虑关联规则的客观度量问题。期望通过引入新的度量机制和重新认识关联规则的系统客观性来改善挖掘质量。 提升度(Lift值) :
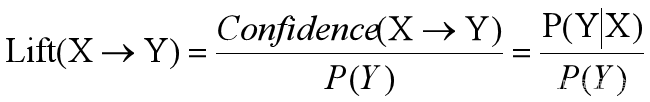
Lift=1,前项和后向经验独立;
Lift>1,表明前后两项是正相关的,说明X与Y实际同时发生的概率大于X与Y独立时同时发生的概率;
Lift<1,表明前后两项是负相关的。
说明:提升度与置信度均用于衡量规则的可靠性,它可以看作是置信度的一种 补充指标。
3.挖掘关联规则问题可以划分成两个子问题:
发现频繁项目集:通过用户给定Minsupport ,寻找所有频繁项目集或者最大频繁项目集。
生成关联规则:通过用户给定Minconfidence ,在频繁项目集中,寻找关联规则。
4.例题说明

二、关联规则算法
1.Apriori
Apriori算法将发现关联规则的过程分为两个步骤:
1.检索出事务数据库中的所有频繁项集,即支持度不低于用户设定最小支持度阈值的项集;
2.利用频繁项集构造出满足用户最小置信度的规则。
Apriori的基本思想: 频繁项集的任何子集也一定是频繁的; 非频繁项集的超集一定是非频繁的。
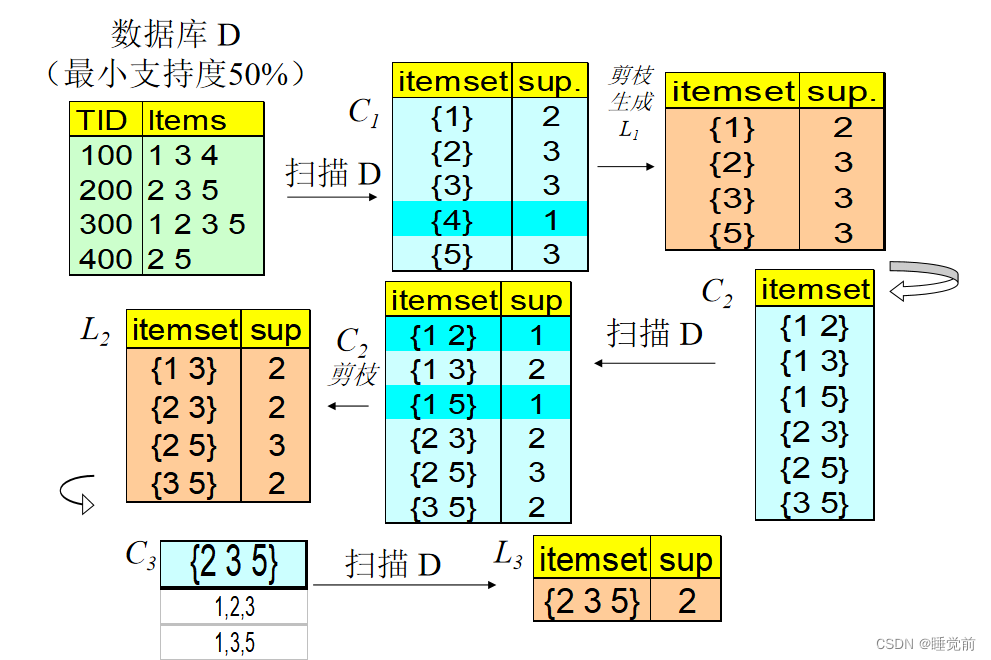
Apriori算法的简单应用:
1次扫描生成满足最小支持度的1单位的频繁项集。
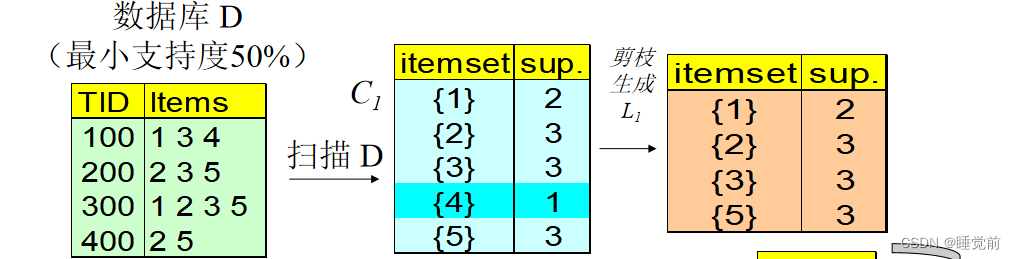
将生成的1项频繁项集两两连接,生成2项频繁项集。在对2项频繁项集进行扫描进而剪枝得到满足最小支持度的2项频繁项集。可见4项集被删去,则包含4的任何超集都是非频繁项集。

将生成的2项频繁项集两两连接,生成3项频繁项集。在对3项频繁项集进行扫描进而剪枝得到满足最小支持度的3项频繁项集。

2.FP-Growth
FP-growth算法只需要对数据集扫描两次,它发现频繁项集的过程如下:
1.构建FP树
2.从FP树中挖掘频繁项集
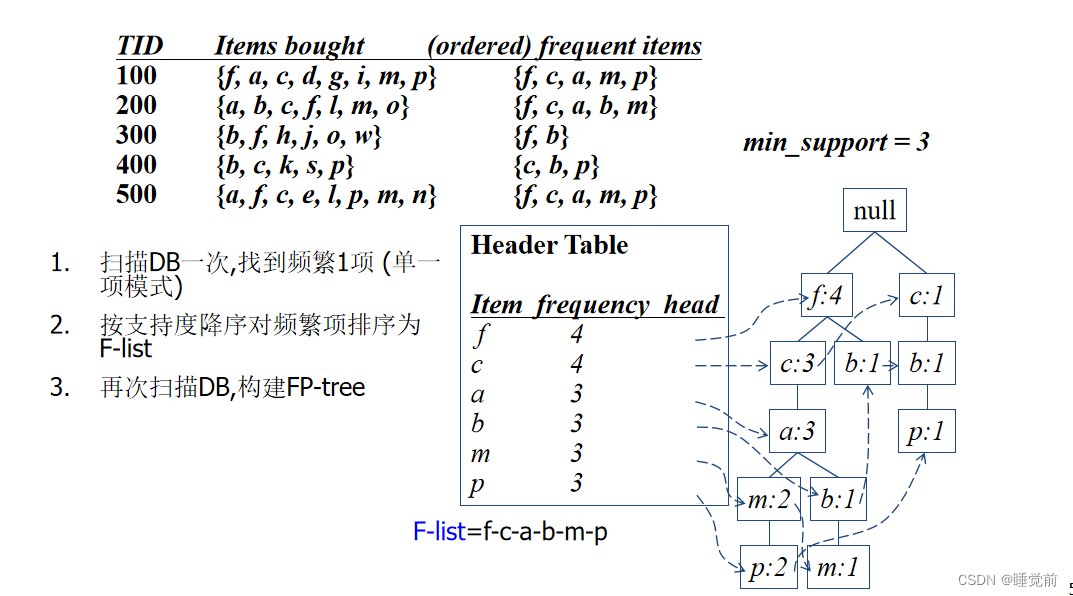
1.FP-树 构建
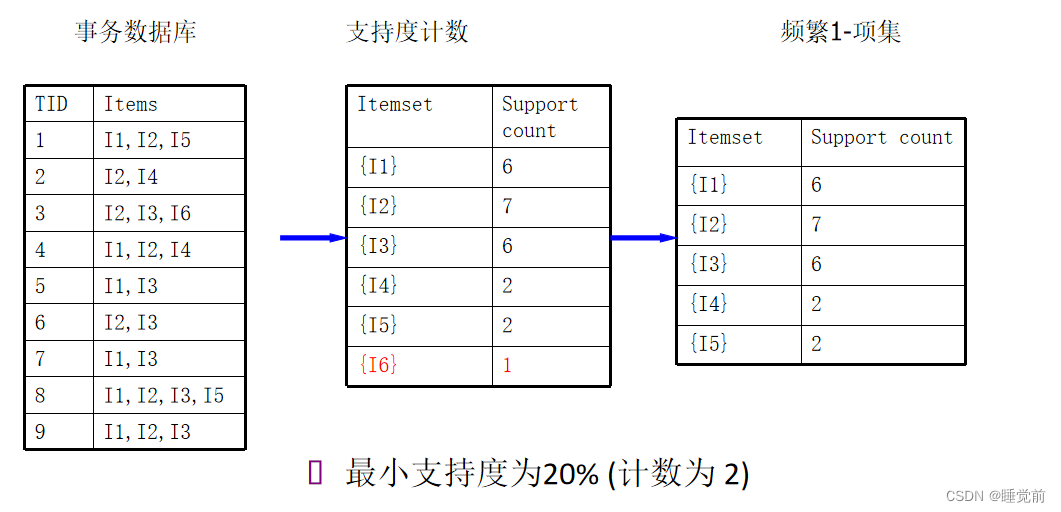
1.扫描DB,找出频繁1项集
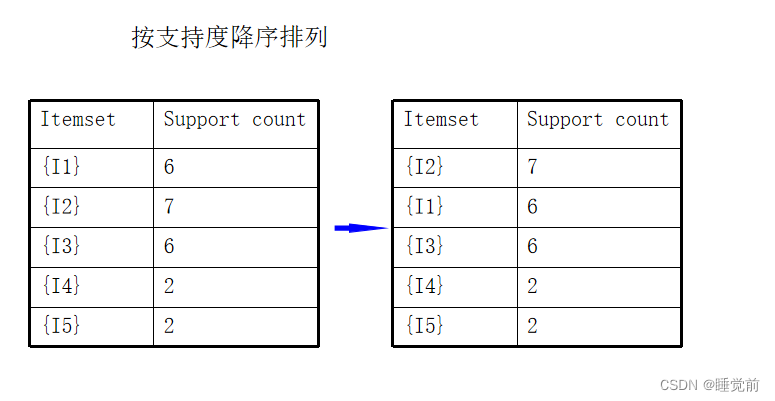
2.对频繁项按频率降序排序, 得到f-list
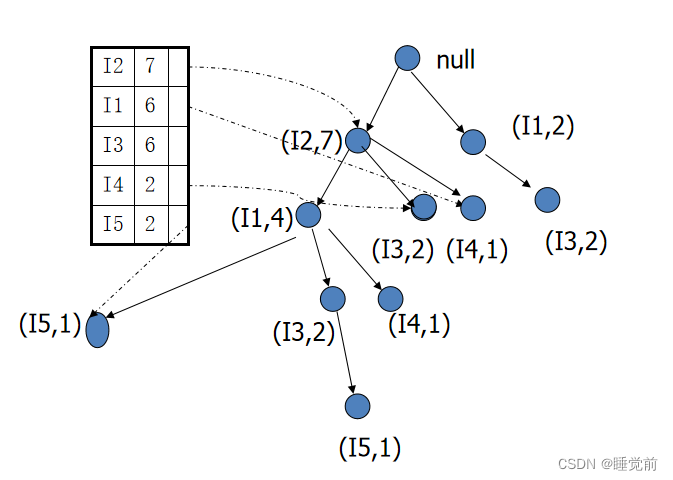
3.扫描DB, 构造 FP-tree
将项集按照支持度进项调换顺序(含6非频繁项集删去)


再进行从左往右的二叉树排列就可以生成FP-tree
另外一个例子:
优点:无论数据集多复杂,只需扫描原始数据集两遍,速度比 Apriori 算法快
缺点:实现比 Apriori 算法复杂
2.FP树中挖掘频繁项集
步骤:
(1)从FP树中获得条件模式基;
(2)利用条件模式基,构建一个条件FP树;
(3)迭代重复步骤1-2,直到树包含一个元素项为止。
(也就是倒退的意思,在满足条件的情况下,倒推频繁项集)
| 项 | 条件模式基 | 生成的频繁模式 |
| I5 | {(I2 I1:1), (I2 I1 I3:1)} | I2 I5:2, I1 I5:2, I2 I1 I5:2 |
| I4 | {(I2 I1:1), (I2:1)} | I2 I4:2 |
| I3 | {(I2 I1:2, (I2:2), (I1:2)} | I2 I3:4, I1 I3:4, I2 I1 I3:2 |
| I1 | {(I2:4)} | I2 I1:4 |
3.例题说明


4.FP-tree 结构的优点
1.完整性
--保持了频繁项集挖掘的完整信息
--没有打断任何事务的长模式
2.紧密性
--减少不相关的信息: 不频繁的项没有了
--项按支持度降序排列: 越频繁出现,越可能被共享
--决不会比原数据库更大 (不计结点链接和计数域)
3.ECLAT
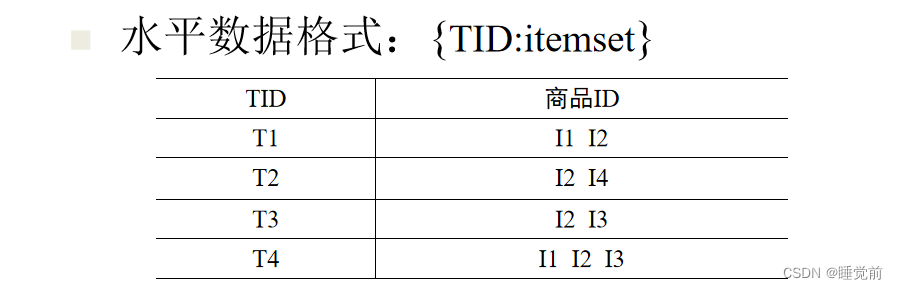
通过垂直数据格式挖掘关联规则 ECLAT
项集和事务发生了调换
 算法步骤:
算法步骤:
1、扫描事务数据库TDB,将水平数据格式转化成垂直数据格式。
2、通过扫描数据库,得到满足最小支持度域值min_sup的频繁1项集。
3、通过频繁k项集产生候选k+1项集,通过集合求交来产生频繁K+1项集。
4、直到不再生成候选项集或不再产生频繁项集,程序结束
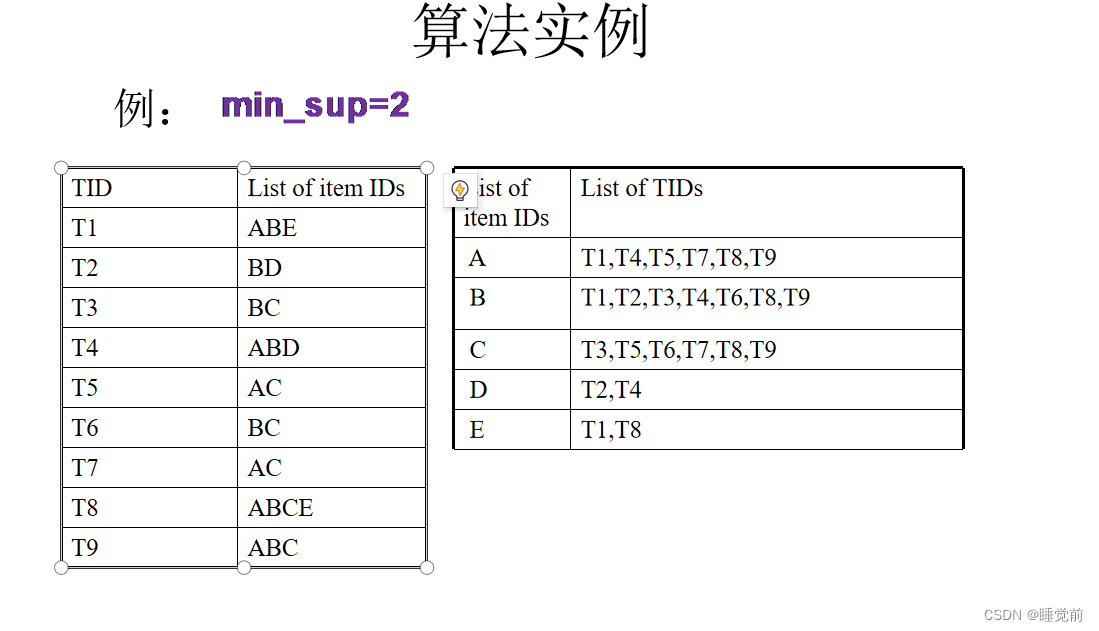 主要思想就是每个项集不断取交集,判断标准就是看交集中所含事务数量能否满足min_sup=2,不满足就删去,满足就继续交集,一直下去。
主要思想就是每个项集不断取交集,判断标准就是看交集中所含事务数量能否满足min_sup=2,不满足就删去,满足就继续交集,一直下去。 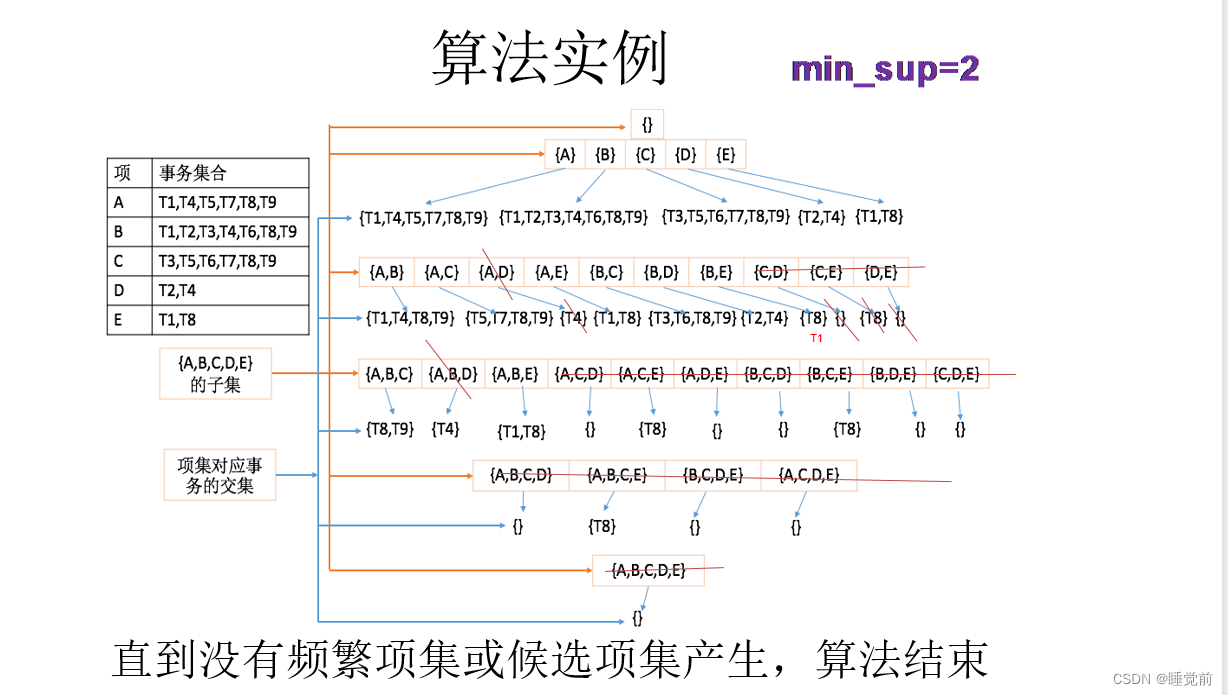
上述案例中{A,B,C}{A,B,E}是3项频繁项集,往上就是2项和1项频繁项集,往下没有4项频繁项集。
三.关联规则的具体应用
1.本文介绍的关联规则的具体应用, 针对目前我国的股票市场,对 2022 年 1 月 4 日至 2023 年 4 月 28 日 我国股票市场的 20 个板块指数的日收盘数据进行关联规则挖掘,利用 Apriori 算法分析板块之间的关联关系。
一.数据采集及预处理
| 时间 | 传媒 | 通信服务 | 计算机应用 | 教育 |
| 2022-12-01,四 | 3.64% | 2.33% | 2.59% | 2.19% |
| 2022-12-02,五 | 1.15% | -0.31% | -0.48% | 0.65% |
| 2022-12-05,一 | -1.33% | -1.08% | -0.33% | -0.54% |
| 2022-12-06,二 | -2.23% | -2.88% | -2.26% | -2.83% |
| 2022-12-07,三 | 0.34% | 0.46% | 1.58% | -0.28% |
在进行关联规则挖掘前,必须对所搜集的数据进行预处理,根据每种股票板块指数在当天交易的涨跌情况将其对应的日收盘数据转化为二项分类型数据。收 益率大于 0 即为股价上涨,用"Yes"表示,收益率小于 0 即为股价下跌,用"No" 表示。

library(arules)
library(arulesViz)
library(tidyverse)
library(openxlsx)
data=read.xlsx("data.xlsx")
data=as.data.frame(data)
data1=data[42:61]
data2=as(data1,"transactions")二.生成最大频繁项集
数据预处理后,根据股票板块指数“涨”、“跌”情况这两种属性,利用关联规则算法进行挖掘。
生成最大频繁项集。

options(digits=3)
#生成最大频繁项集
parameter1<-list(support=0.4,target="maximally frequent itemsets")
item_maxF<-data2 %>% apriori(parameter=parameter1) %>% sort(by="support")
item_maxF <- inspect(item_maxF) 三.生成频繁项集
#生成频繁项集
parameter2<-list(support=0.4,target="frequent itemsets")
item_F<-data2 %>% apriori(parameter=parameter2) %>% sort(by="support")
item_F<-inspect(item_F) 
四.生成规定参数的关联规则
当支持度阈值为 0.4,置信度(confidence)阈值为 0.8 时,可以从模型中找到 许多有意义的强关联规则。最终我们共找到 52 条关联规则。
## 设置置信度confidence=0.6,利用函数ruleInduction()生成关联规则
options(digits=3)
parameter2<-list(support=0.4,target="frequent itemsets")
item_F<-data2 %>% apriori(parameter=parameter2)
MyRules_lift<-item_F %>% ruleInduction(transactions=data2,confidence=0.8) %>%
sort(by="lift")
MyRules_l<-MyRules_lift%>% inspect()
五.可视化展示
MyRules_lift %>% plot(method="graph")
MyRules_lift %>% plot(method="paracoord")
综合而言,在满足最小支持度的情况下,专用设备与消费电子板块之间联动 效应较强的规则的置信度为 0.8686,提升度大于 1.5,说明是强关联规则;传媒、 计算机应用与通信服务板块之间的联动效应较强的规则的置信度为 0.9485,提升度大于 1.5,说明结论可靠性较高。结合网络结构图,从整体来看,计算机应用、 通信服务和传媒板块;通信服务、消费电子和专用设备板块;专用设备、电力设 备和工业金属板块之间的所指向的气泡较大,说明支持度较高,且颜色较深说明
提升度较高,规则可靠,联动效应较强。

总结
Apriori算法为基础,但是因为其每次产生频繁项集都要遍历一遍数据,所以效率很低。FP-Growth算法,只需要遍历两遍数据,效率很高但是模型复杂;ELACT算法采用了与传统挖掘算法不同的垂直数据库结构,由于这样只要扫描两次数据库,大大减少了挖掘规则所需要的时间,从而提高了挖掘关联规则的效率。该算法没有对产生的候选集进行删减操作,若项目出现的频率非常高,,频繁项集庞大, 进行交集操作时会消耗系统大量的内存。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









