







Datawhale 零基础入门数据挖掘
一、赛题数据
赛题以预测二手车的交易价格为任务,数据集报名后可见并可下载,该数据来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
字段表
| Field | Description |
|---|---|
| SaleID | 交易ID,唯一编码 |
| name | 汽车交易名称,已脱敏 |
| regDate | 汽车注册日期,例如20160101,2016年01月01日 |
| model | 车型编码,已脱敏 |
| brand | 汽车品牌,已脱敏 |
| bodyType | 车身类型:豪华轿车:0,微型车:1,厢型车:2,大巴车:3,敞篷车:4,双门汽车:5,商务车:6,搅拌车:7 |
| fuelType | 燃油类型:汽油:0,柴油:1,液化石油气:2,天然气:3,混合动力:4,其他:5,电动:6 |
| gearbox | 变速箱:手动:0,自动:1 |
| power | 发动机功率:范围 [ 0, 600 ] |
| kilometer | 汽车已行驶公里,单位万km |
| notRepairedDamage | 汽车有尚未修复的损坏:是:0,否:1 |
| regionCode | 地区编码,已脱敏 |
| seller | 销售方:个体:0,非个体:1 |
| offerType | 报价类型:提供:0,请求:1 |
| creatDate | 汽车上线时间,即开始售卖时间 |
| price | 二手车交易价格(预测目标) |
| v系列特征 | 匿名特征,包含v0-14在内15个匿名特征 |
二、数据概览
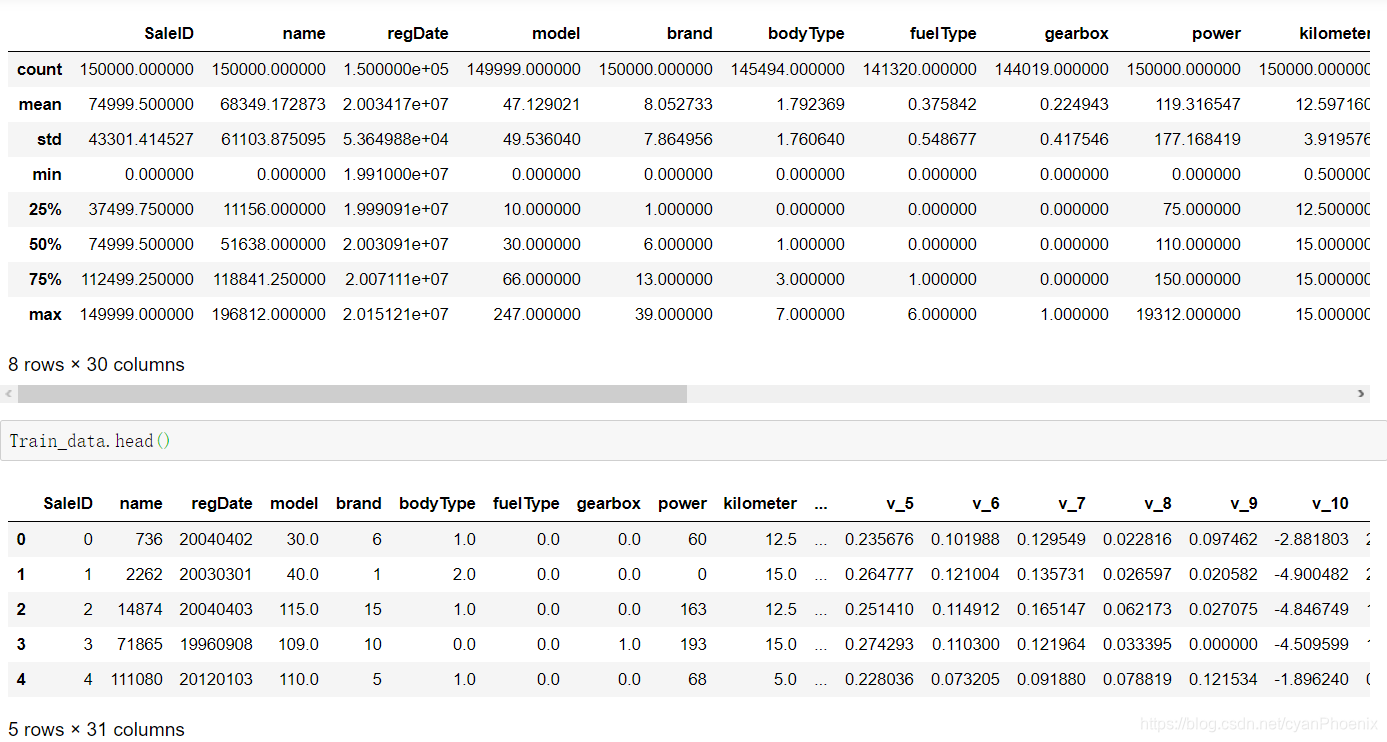
从上述信息可以看到,一共有30个特征列,以及一个标签列“price”。
其中:
1、name,model,brand, bodytype, fueltype, gearbox,notRepairedDamage, regionCode, seller, offerType 均为字符性质的变量。尽管已经被编码为数字,但是不能直接被用于训练。当然,除了值为0或1的二元变量。
对于这一类特征,我的直观理解是可以将它们转化为one-hot编码来参与到后续的训练中。因为有的特征,比如车型,品牌,型号,直观上理解,对二手车销售价格还是非常重要的。Baseline中将这类特征舍弃了,我觉得是不合适的。
2、regDate, creatDate 这类时间变量。均为8位数字的日期。这类数据也不能直接被用于训练。
我的想法是,将这列数据转成时间序列。而后将日期转化为从固定时间开始的计时数目,比如天数或者月数。可能月数比较合适,足够说明问题了。天数太久了,也没有那个必要。
3、匿名特征可能很有代表性,按照该类数据的生成方法,应该是与价格比较相关的数据。
4、我个人直观上感觉比较重要的特征是:品牌、型号、车型、变速箱、故障、公里数、注册日期。
三、数据分析
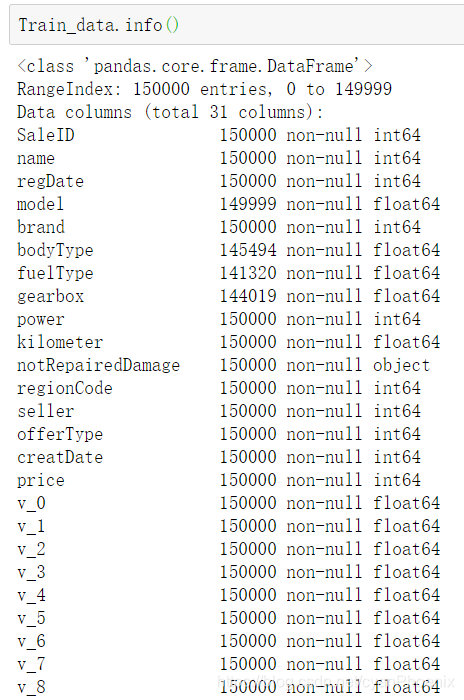
首先该类数据是含有缺失值的。缺失值的处理有这样几种方法:
1、常数补全
2、均值补全
3、低秩矩阵补全
3.1 检查各类特征的情况
在检查各个特征的时候。首先看的是时间。在使用pd.to_datetime来转化时间格式的时候,有报错。检查后发现,有一万多条数据是0月,因此无法识别。
因此,设计了一个小程序,如果不能转化,就只读取转化为年份。
from datetime import datetime
def num2data(time):
Time,index,error_info = [],[],[]
for i in range(len(time)):
try:
item = datetime.strptime(str(time[i]),'%Y%m%d')
except:
item_ = str(time[i])[0:4]
item = datetime.strptime(item_,'%Y')
index.append(i)
#error_info.append(item)
Time.append(item)
return Time将所有时间减去最早的时间,将日期转化为天数作为训练的特征。
from datetime import timedelta
latest_reg_time = TestA_data["regDate"].min()
Train_data["regDate"] = Train_data["regDate"] - latest_reg_time + timedelta(1)
TestA_data["regDate"] = TestA_data["regDate"] - latest_reg_time + timedelta(1)
Train_data["creatDate"] = Train_data["creatDate"] - latest_reg_time + timedelta(1)
TestA_data["creatDate"] = TestA_data["creatDate"] - latest_reg_time + timedelta(1)
#最后加上timedelta(1) 是为了使得最早的时间为1,非0这个代码运行的结果得到的四列数据就是timedelta的格式。
但是这个格式不能直接转成一个数组。
比如:
print(np.array(Train_data["regDate"], dtype="int"))
print(Train_data["regDate"])
结果是这样:
[-823721984 -434831360 1614151680 ... -489684992 1051852800 1837301760]
0 4841 days
1 4443 days
2 4842 days
...
149999 2957 days
Name: regDate, Length: 150000, dtype: timedelta64[ns]直接用·导入到numpy里,数据会变化。找了很久,找到了一种把这个timedelta转化为numpy的方法:
Train_data["regDate"] = ((Train_data["regDate"] / np.timedelta64(1, 'D'))/30).astype(int)而后, 开始分析其他的数值型特征。先分析数值特征和价格的相关性。
numeric_features = ["used_time","regDate", "creatDate", 'power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode']
numeric_features.append("price")
Train_data["used_time"] = Train_data["creatDate"] - Train_data["regDate"]
#添加一列使用时间作为新特征但是相关性里,有三个选项。
DataFrame.corr(method='pearson', min_periods=1)
method : {‘pearson’, ‘kendall’, ‘spearman’}
- pearson : standard correlation coefficient
- kendall : Kendall Tau correlation coefficient
- spearman : Spearman rank correlation
min_periods : int, optional
Minimum number of observations required per pair of columns to have a valid result. Currently only available for pearson and spearman correlation
1、pearson相关系数
price 1.000000
v_12 0.692823
v_8 0.685798
v_0 0.628397
power 0.219834
v_5 0.164317
v_2 0.085322
v_6 0.068970
v_1 0.060914
v_14 0.035911
v_13 -0.013993
v_7 -0.053024
v_4 -0.147085
v_9 -0.206205
v_10 -0.246175
v_11 -0.275320
kilometer -0.440519
v_3 -0.730946
Name: price, dtype: float64 
2、spearman 相关系数
price 1.000000
v_0 0.873225
v_12 0.860065
v_8 0.836034
regDate 0.779260
v_2 0.597624
power 0.577343
v_6 0.423424
v_5 0.353681
v_14 0.189175
v_1 0.150472
v_13 0.052532
v_7 0.021379
creatDate 0.018517
v_4 -0.149911
v_9 -0.235606
kilometer -0.409778
v_11 -0.410023
v_10 -0.507179
used_time -0.779137
v_3 -0.925305
Name: price, dtype: float64 组合一下看看对比结果:
pd.concat(dict(pearson = df1, spearman = df2),axis=1)
pearson spearman
used_time -0.612050 -0.779137
regDate 0.612168 0.779260
creatDate 0.015538 0.018517
power 0.219834 0.577343
kilometer -0.440519 -0.409778
v_0 0.628397 0.873225
v_1 0.060914 0.150472
v_2 0.085322 0.597624
v_3 -0.730946 -0.925305
v_4 -0.147085 -0.149911
v_5 0.164317 0.353681
v_6 0.068970 0.423424
v_7 -0.053024 0.021379
v_8 0.685798 0.836034
v_9 -0.206205 -0.235606
v_10 -0.246175 -0.507179
v_11 -0.275320 -0.410023
v_12 0.692823 0.860065
v_13 -0.013993 0.052532
v_14 0.035911 0.189175从数据上来看,价格与使用时间的相关性比注册时间略低。
这两种相关系数,pearson主要是用来测试线性相关性的。而spearman则没有这个限制,它主要是对排序进行计算相关性。我的理解是可以衡量一部分的非线性相关性。因此在选择相关特征的时候,选择了spearman相关系数来判断。筛选出相关系数大于0.3的特征。并提取出来,使用SVR进行训练拟合。
拟合结果有待揭晓···因为程序到现在还没有跑出来结果
use_index = list(price_corr[price_corr.abs()>0.3].index)[0:]
use_index[:-1]
['used_time',
'regDate',
'power',
'kilometer',
'v_0',
'v_2',
'v_3',
'v_5',
'v_6',
'v_8',
'v_10',
'v_11',
'v_12']from sklearn.svm import SVR
data_train = Train_data[use_index[:-1]]
data_label = Train_data[use_index[-1]]
svr_model = GridSearchCV(SVR(), param_grid={"kernel": ("linear", 'rbf'), "C": np.logspace(-3, 3, 7), "gamma": np.logspace(-3, 3, 7)})
svr_model.fit(data_train, data_label)
下次再决定用网格之前我一定先跑一遍看看时间···跑了四天了结果还是没出来。我这暂停也舍不得,不暂停又尴尬。哭了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









