







/* Author: cyh_24 */
/* Date: 2014.10.2 */
/* Email: cyh@buaa.edu.cn */
/* More: http://blog.csdn.net/cyh_24 */
http://blog.csdn.net/cyh_24/article/details/39755661
由于导师给我们布置了每周阅读两篇大牛论文,并写ppt的任务。反正ppt都写了,所以我想干脆直接把ppt的内容再整理一下写成博客。近期的阅读论文都是人脸识别相关的主题。
如果你研究过人脸识别,或者对这方面有兴趣,那么你一定听说过Paul Viola。他可以算得上是人脸检测识别的始祖,他的一篇大作《RobustReal-time Object Detection》可以说是人脸识别领域最重要的一篇论文。
本文主要就这篇论文展开,介绍Haar特征,积分图,Adaboost等内容。
1、Haar特征
1.1 特征
什么是特征?
想一想我们是如何分辨物体的?更具体一点,你是如何辨别一张图片里面的人脸是一个人脸的?其实很简单,你会去找是不是有眼睛、嘴巴等面部器官。当然这些器官的位置基本是固定的。是否有眼睛,眼睛之间的距离,眼睛跟鼻子的位置关系等等这些都叫特征。选择使用特征的一个重要的原因:基于特征的系统的运行速度要远比基于像素的快。
有的人想,特征什么的谁不知道,但是怎么表示这些特征呢?我要怎么表示、分辨特征呢?
1.2 Haar特征
讲haar特征之前,我想先直观地给大家看看haar特征长什么样,下图就是viola等人提出的haar特征:
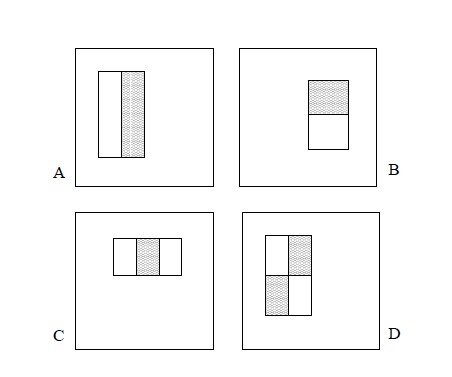
当然,这只是第一次提出的样子,后来又有很多人对这些图进行了改进,Lienhart等大神后来又提出了下面这些haar特征:

这些图有什么用呢?
也很简单,把这些图形放到人脸区域上,然后,将白色区域的像素和–黑色区域的像素和,得到的结果就是一个特征值。如下图:

例如:我们都知道,眼睛跟眼窝的颜色不同,眼睛更黑。我们定义一个阈值K,当一张使用(上黑下白)的矩形特征模板进行运算(白色区域的像素和 – 黑色区域的像素和),如果运算的结果>=K时,我们就认为找到了眼睛。
有的人就反对了,凭什么你用一个矩形特征模板运算得到一个结果>=K就算找到眼睛了,万一我这个图像就是一个区域上面是黑的,下面是白的呢?
不要着急,我们再使用第二个矩形特征模板对这块区域进行验证,是不是能增加可靠度呢?如果再用其他的矩形特征模板验证,是不是还可以增加可靠度呢?如果再换个区域,再换个矩形特征模板再验证,是不是还可以增加可靠度呢?
通过改变特征模板的大小和位置,可在图像子窗口中穷举出大量的特征。对于一个给定的24*24像素的人脸图像,根据不同的位置,以及不同的缩放,可以产生160,000个特征。
有这么多的特征,我想这个时候的精确度应该已经很高了,但是同时其他问题也出现了——运算速度。
为了提高运算速度,我们的大神viola又提出了积分图的概念。
2、积分图
积分图是个啥东西呢?
上面提到haar特征计算方法是用白色区域的像素和-黑色区域的像素和,如果是我,我可能会这么做:
1、 找出黑色区域所有像素点,全部加起来=BSum;
2、 找出白色区域所有像素点,全部加起来=WSum;
3、 WSum-BSum;
这么算显然是很笨的,因为有很多值我之前都算过了,重复计算就是无意义的消耗cpu了。
所以viola提出了积分图的概念,算法的思想其实有点像动态规划,就是一次计算,多次使用。实际上,积分图只需要遍历一次图像就可以求出图像中所有区域像素和,大大提高了图像特征值计算的效率。
来看看他究竟是这么做的。还是先放图:

坐标(x,y)的值 = 阴影部分所有像素之和。
积分图构建算法:
1)用s(i,j)表示行方向的累加和,初始化s(i,-1)=0;
2)用ii(i,j)表示一个积分图像,初始化ii(-1,i)=0;
3)逐行扫描图像,递归计算每个像素(i,j)行方向的累加和s(i,j)和积分图像ii(i,j)的值
s(i,j)=s(i,j-1)+f(i,j)
ii(i,j)=ii(i-1,j)+s(i,j)
4)扫描图像一遍,当到达图像右下角像素时,积分图像ii就构造好了。
积分图构造好之后,图像中任何矩阵区域的像素累加和都可以通过简单运算得到如图所示:
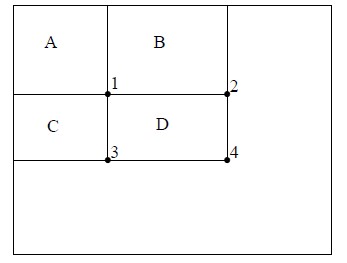
例如:区域D的像素值之和 = (4 + 1 -(2+3))
3、Adaboost
有的人说,有了haar特征,有了提升性能的积分图,是不是已经可以很好的解决问题了?答案是:no. 因为,计算每一个特征值的时候速度都大幅提升了,但是,一个小小的24*24是人脸图像根据不同的位置,以及不同的缩放,可以产生超过160,000个特征!这个数量太庞大了,所以肯定要舍弃大量的特征。那么,如何保证使用少量的特征,而又能得到精确的结果呢?大神永远有解决方法,viola等人使用adaboost来进行分类。
声明一下,adaboost并不是viola等人提出的,而是Freund和Schapire提出。但是viola的伟大正是因为他将这个模型首次用到了人脸识别中,这使得人脸识别成为一个可能的事情。
这里不对adaboost进行详细的探讨,网络上关于这方面的信息很多。这里只简单介绍一下人脸识别中,是如何使用这个模型的。
3.1 级联结构
所有伟大的东西,其思想都是很简单的。
所谓的级联结构无非就是:
将多个强分类器连接在一起进行操作。每一个强分类器都由若干个弱分类器加权组成。例如,一个级联用的强分类器包含20个左右的弱分类器,然后在将10个强分类器级联起来,就构成了一个级联强分类器,这个级联强分类器中总共包括200个(20*10)分类器。因为每一个强分类器对负样本的判别准确度非常高,所以一旦发现检测到的目标位负样本,就不在继续调用下面的强分类器,减少了很多的检测时间。因为一幅图像中待检测的区域很多都是负样本,这样由级联分类器在分类器的初期就抛弃了很多负样本的复杂检测,所以级联分类器的速度是非常快的;只有正样本才会送到下一个强分类器进行再次检验,这样就保证了最后输出的正样本的伪正(false positive)的可能性非常低。
3.2 最优弱分类器的诞生:
寻找合适的阈值,使该分类器对所有样本的判断误差最小
对于每个特征f,计算所有训练样本的特征值并排序:
遍历排序后的特征值,对于序列中的每个元素,计算以下值:
1.全部人脸样本的权重和t1
2.全部非人脸样本的权重和t0
3.在此元素之前的人脸样本的权重和s1
4.在此元素之前的非人脸样本的权重和s0
5.此元素的分类误差:r=min{[s1+(t0-s0)],[s0+(t1-s1)]}
找出r值最小的元素作为最优阈值,最优分类器诞生
3.3 强分类器:
For T轮迭代:
1.重新统一权重
2.训练出本轮的最优弱分类器(详见上一P)
3.根据本轮迭代中的分类结果重新分配样本权重(增加错误分配样本的权重)
这样,T轮之后将产生T个最优弱分类器
组合T个最优弱分类器得到强分类器:
相当于让所有弱分类器投票,再对投票结果按照弱分类器的错误率加权求和,将投票加权求和的结果与平均投票结果比较得出最终的结果
3.4 如何训练一个级联分类器
1.在更高的检测率和更低的错误率之间权衡。
2.在更多的特征点和更快的运行速度之间权衡。
所以在我们的框架中以下三个值关系到上述两点:
1. the number of classifier stages
2. the number of features of eachstage,ni
3. the threshold of each stage
3.5 训练详细过程:
1.设定每层最小要达到的检测率d,最大误识率f,最终级联分类器的误识率Ft
2. P=人脸训练样本,N=非人脸训练样本,D0=1.0,F0=1.0
3.for( i=0;Fi<=Ft; i++ )
ni = 0; Fi = Fi-1;
while Fi > f x Fi-1
ni++;
利用AdaBoost算法在P和N上训练具有ni个弱分类器的强分类器;
衡量当前级联分类器的检测率Di和误识率Fi ;
for : di < d x Di-1
降低第i层的强分类器阈值
衡量当前级联分类器的检测率Di和误识别率Fi
N = Φ
用当前级联分类器检测非人脸图像,将误识别图像放入N
4、论文实验效果
论文中提到的效果:测试使用MIT+CMU测试集,平均6061个特征中有10个特征被挑出。发现有大量子窗口被级联的第一层和第二层剔除。
在700M的奔腾3CPU上,该人脸检测可以约0.67秒的速度处理一幅384×288像素大小的图像。
这个速度大概是Rowley-Baluja-Kanade检测器的15倍,Schneiderman- Kanade检测器的约600倍。
















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









