







 本文通过实例演示如何在Selenium中使用JavaScript进行精准元素定位,特别是当常规定位方法失效时,利用Chrome开发者工具和JavaScript语句,精确找到并操作目标元素。
本文通过实例演示如何在Selenium中使用JavaScript进行精准元素定位,特别是当常规定位方法失效时,利用Chrome开发者工具和JavaScript语句,精确找到并操作目标元素。
以搜狐网首页为例,我们要定位“搜狗邮箱”这个链接(如果是xpath等等各种selenium内置提供的定位方法都没用的情况下)
第一步,找到该元素,此时显示 <div class="title">搜狐邮箱</div>

第二步:一个HTML文档id只有一个,class是有多个的,但往往就没有id给你定位,只有class的属性,怎么办?
不用急,按下F12,打开Chrome开发者工具,点击Console(控制台)标签,输入一条JavaScript语句:
document.getElementsByClassName('title').length
回车查看结果,结果是4,说明整个HTML文档,有4个地方用了class="title"。那怎么办呢?看第三步
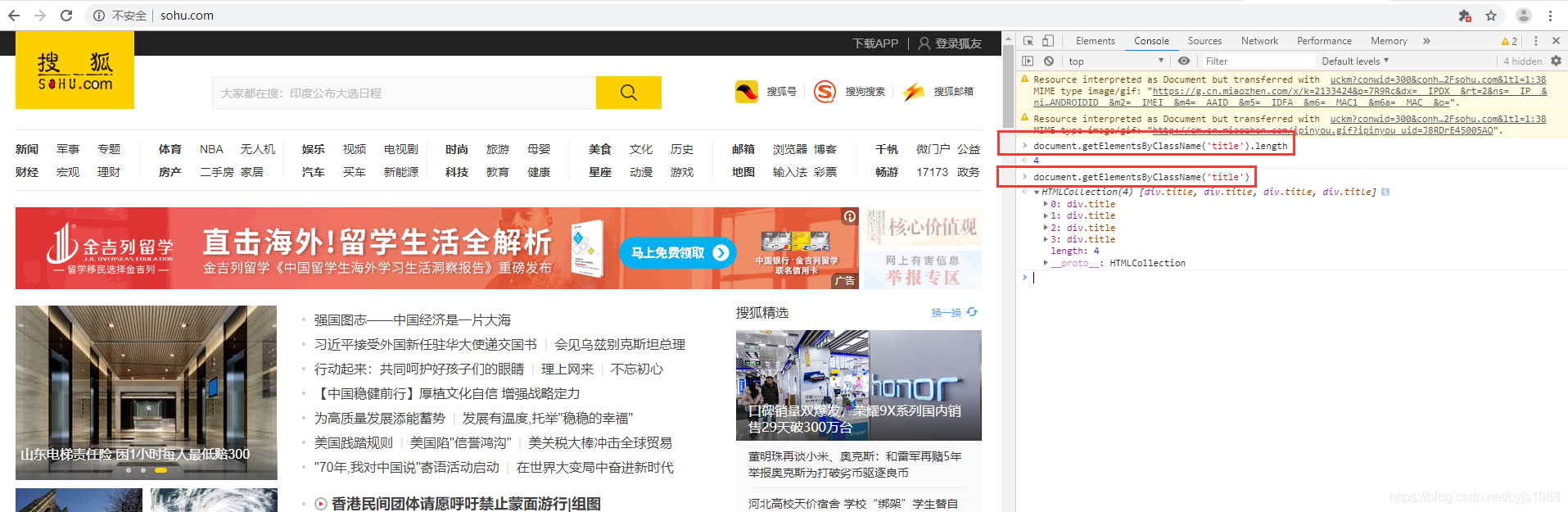
第三步,直接输入document.getElementsByClassName('title'),回车
结果出来了,有四个用到class="title"的地方,把鼠标指针浮在每个元素上,并同时关注页面上的蓝色定位标志。
找到了!(如下图)是下标为2的div.title
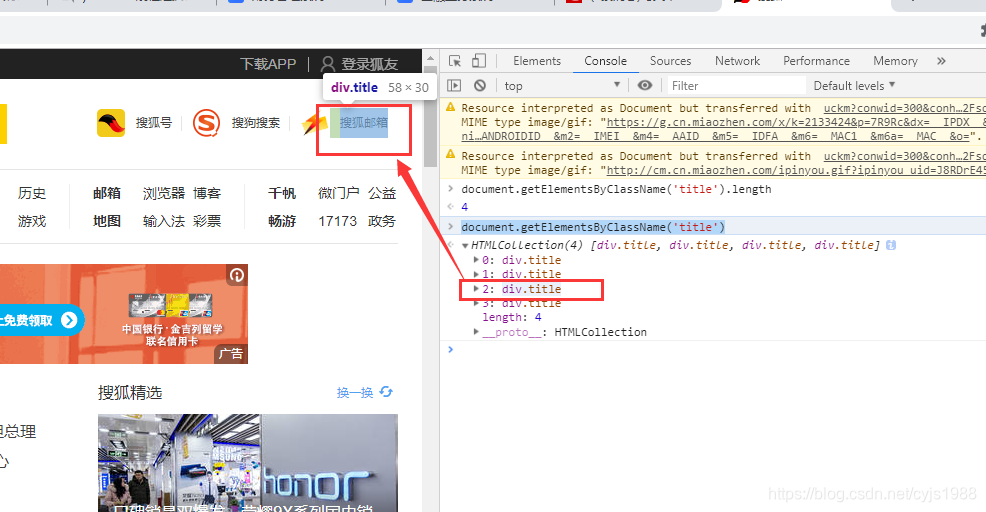
那么结果就是document.getElementsByClassName('title')[2]
不是要做点击操作吗?那么直接就是(python语言为例): js = "document.getElementsByClassName('title')[2].click();"
JavaScript语句规定,下标一律从0开始算起;而Xpath是从1开始算起,千万别搞混淆了!
那么完整selenium定位代码如下所示:
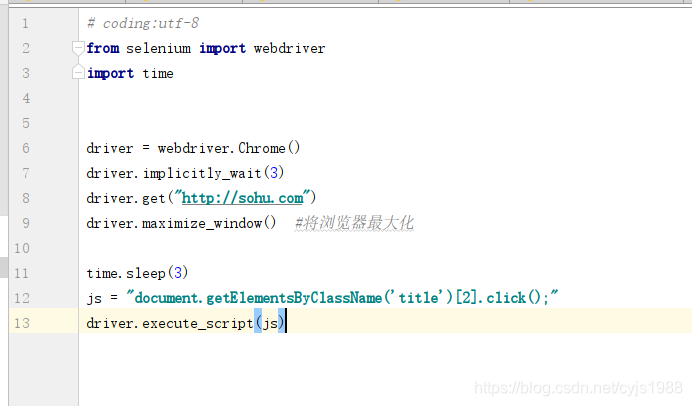
# coding:utf-8
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.implicitly_wait(3)
driver.get("http://sohu.com")
driver.maximize_window() #将浏览器最大化
time.sleep(3)
js = "document.getElementsByClassName('title')[2].click();"
driver.execute_script(js)效果图(gif动态演示):
gif录制工具:链接: https://pan.baidu.com/s/1poNN5uWy0NHv3IGAAygZSg 提取码: c5cn


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









