







2021SC@SDUSC
seafile中,此部分的相关内容与git大体相同。
提交
版本管理理论前提
想要对仓库进行版本化管理,即持久化追踪仓库中的更新,则需要一个节点来存储每个版本下仓库内容的拷贝。这个节点就是提交。
每次提交后,仓库将重新组织新的seafile文件系统,生成新的seafobj,产生新的块,也就是一个拷贝。但显然,每次都重新拷贝一份实在是太浪费空间了。这时候,分块、SHA1命名的作用就体现出来了。每次更新只会影响被修改的块,所有被修改的内容只会影响被修改的块;SHA1命名基于操作系统文件系统,会替换同名的文件,而SHA1相同又代表内容相同。综上,在分块和SHA1命名的前提下,两个版本的交集实际上并没有被拷贝,拷贝的仅仅是新版本相对于老版本的增量内容。
在关于新版本的空间问题被解决后,剩下就是文件系统的重新组织问题,因为新版本与老版本的文件树很一定不一致。新版本实际上是仍然按照旧版本生成文件树,并保存seafile对象,且由于SHA1命名的关系,如果一个文件没被修改或一个目录没被修改,那么对象内部的链接仍然指向同一个对象,所以新版本相对旧版本只是根目录到某一个子目录的一个子树上做了更新。对于旧版本而言,文件系统的组织结构也是增量更新的。
上述两段论证了基于seafile文件系统(包括分块、文件组织)的版本管理,不论是从内容的角度还是从文件结构的角度,都是增量更新的。这大大提高了空间利用率,使得版本化管理更加高效。
提交的实质
提交的实质就是指向某个根目录的指针。

每次提交后,重新对用户文件系统的原始目录进行组织,生成对应的新的seafile文件结构,然后新的提交就指向了新的根目录。根据版本管理增量更新的理论依据,旧的文件结构与内容都仍然存在,并且仍然可由旧的提交找到,所以我们可以进一步把提交泛化为一个抽象的対象,该对象就代表了一个版本的仓库,包括了该版本下的文件内容与文件结构。(这也是从用户的角度,去理解提交的概念)
Seafile提交
seafile版本管理中的提交对象,拥有以下信息:
struct _SeafCommit { // 提交对象
struct _SeafCommitManager *manager; // 提交管理器
int ref; // 引用次数(GC)
char commit_id[41]; // 提交id
char repo_id[37]; // 仓库id
char root_id[41]; // 根目录id
char *desc; // 提交描述
char *creator_name; // 创建者名字
char creator_id[41]; // 创建者id
guint64 ctime; // 创建时间
char *parent_id; // 父提交id
char *second_parent_id; // 第二父提交id
char *repo_name; // 仓库名
char *repo_desc; // 仓库排列顺序
char *repo_category; // 仓库分类
char *device_name; // 设备名
char *client_version; // 客户端版本
gboolean encrypted; // 是否加密
int enc_version; // 加密版本
char *magic; // 仓库密码校验
char *random_key; // 随机密钥
char *salt; // 盐
gboolean no_local_history; // 有无本地记录
int version; // 版本
gboolean new_merge; // 是否是新的合并
gboolean conflict; // 是否冲突
gboolean repaired; // 是否被修复
};
一个提交对象包含的信息主要由以下几个方面。
-
签名
包括提交者、提交时间等。
-
仓库
依照从用户角度的理解,一个提交就对应了某版本下的整个仓库。实际上,提交中含有一个指针(repo_id)指向了其所在的仓库。同时我们还发现了许多与仓库对象耦合的字段,这些字段其实只是为了方便获取,实际上不包含在提交对象中。
-
历史提交图
每个提交可能有一或两个父提交,这是因为两个提交可以合并成一个新的提交(准确来说是分支的合并)。如果我们把提交间以父指针联系起来,则组成了一个DAG(有向无环图),每个节点代表一个提交,且节点入度小于等于2;并且该DAG只有一个根,称为初始提交(init)。
和历史提交图有关的信息包括:父指针、合并相关信息。
提交管理操作
在commit-mgr中定义了一些提交管理操作,仅限于对提交的管理。合并等不在其中。
这些操作中除了增删查改提交对象(键值对存储)外,还有拓扑遍历操作。拓扑遍历操作将从一个提交开始,向上遍历所有提交;如果某个提交有两个父提交,则会遍历各个分支(图分支)。
分支
我们知道一次提交是基于另一次提交之上、或者是两个提交的合并,那么如何指代另一个提交或者另两个提交?显然,如果细粒度地使用提交名,效率太低,可读性太差。
分支广义上是指得到某个提交的过程,那么得到不同的提交就对应了不同的分支。以小版本发布的开源软件为例,此时需要两个分支,一个是成品,另一个是开发过程中的半成品;前者指代得到某个版本的成品的过程,后者指代开发的过程;发布新版本时,我们不需要关心两个过程中各个提交间的具体联系,只需要将开发分支向成品分支合并,得到新的成品分支。
如果提交是对版本的细粒度管理,那么分支则是对版本的粗粒度管理。狭义上,用一个分支去指代一个提交,并且随着新提交的加入,分支向新提交移动。
我们还要区分一下历史提交图上的图分支和分支的区别。分支在版本管理中只是指代不同的提交,而图分支代表图上不相交的路径。两者是完全截然不同的概念,只在合并操作中会出现交集(合并既是分支的合并,也是图分支的合并)。
分支的实质
分支实质就是指向提交的指针。
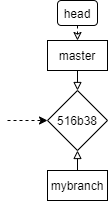
如图,有两个分支指向同一个提交。在提交了若干次后,分支和提交的关系可能如下:

两个不同的分支向两个不同的提交方向移动,最终指向两个不同的提交,代表两个不同的提交过程。
-
Head指针
指向分支的指针,代表该分支为当前分支。此后的提交、合并,都向head指针指向的分支进行。
Seafile分支
struct _SeafBranch { // 分支对象
int ref; // 引用次数
char *name; // 分支名
char repo_id[37]; // 仓库id
char commit_id[41]; // 提交id
};
分支的对象结构很简单,包含repo_id代表所在仓库;name表示分支名;commit_id表示所指向的提交。
Seafile分支操作
分支可以很好地用关系去描述,因此被持久化至数据库。主要操作就是增删查改,略。















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









