







写在前面:
- 我热爱技术,热爱分享,热爱生活, 我始终相信:技术是开源的,知识是共享的!
- 博客里面的内容大部分均为原创,是自己日常的学习记录和总结,便于自己在后面的时间里回顾,当然也是希望可以分享自己的知识。目前的内容几乎是基础知识和技术入门,如果你觉得还可以的话不妨关注一下,我们共同进步!
- 个人除了分享博客之外,也喜欢看书,写一点日常杂文和心情分享,如果你感兴趣,也可以关注关注!
- 微信公众号:傲骄鹿先生
一条查询SQL是如何执行的?
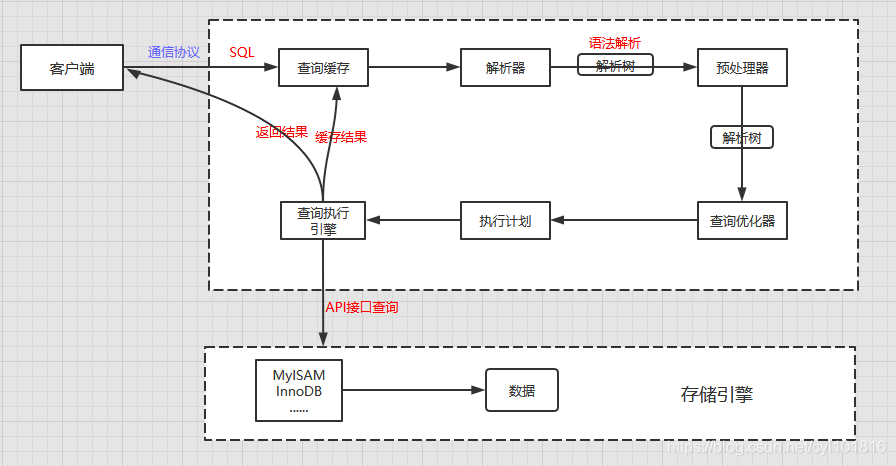
程序或者工具要操作数据库, 第一步跟数据库建立连接
1、通信协议
首先, MySQL 必须要运行一个服务, 监听默认的端口(3306)。
通信协议(MySQL 支持多种通信协议。)
- 第一个就是 TCP/IP 协议, 编程语言的连接模块都是用 TCP 协议连接到 MySQL 服务器的, 比如:mysql-connector-java-x.x.xx.jar
- 第二种是 Unix Socket。 比如我们在 Linux 服务器, 不用通过网络协议, 也可以连接到 MySQL 的服务器, 它需要用到服务器上的一个物理文件(mysql.sock) 。
- 另外还有命名管道( Named Pipes) 和内存共享( Share Memory) 的方式。
通信方式
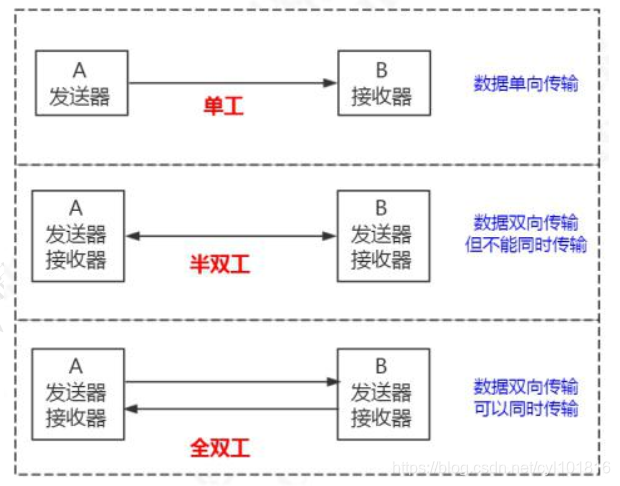
MySQL 使用半双工的通信方式。半双工意味着要么是客户端向服务端发送数据, 要么是服务端向客户端发送数据, 这两个动作不能同时发生。
所以客户端发送 SQL 语句给服务端的时候, ( 在一次连接里面) 数据是不能分成小块发送的, 不管你的 SQL 语句有多大, 都是一次性发送。
如果发送给服务器的数据包过大, 我们必须要调整 MySQL 服务器配置 max_allowed_packet 参数的值( 默认是 4M) 。

另一方面, 对于服务端来说, 也是一次性发送所有的数据, 不能因为你已经取到了想要的数据就中断操作。所以, 我们一定要在程序里面避免不带 limit 的这种操作。
连接方式
MySQL 既支持短连接, 也支持长连接。 短连接就是操作完毕以后, 马上 close 掉。 长连接可以保持
打开, 后面的程序访问的时候还可以使用这个连接。
长时间不活动的连接, MySQL 服务器会断开。
show global variables like 'wait_timeout'; (非交互式超时时间, 如 JDBC 程序)
show global variables like 'interactive_timeout'; (交互式超时时间, 如 数据库工具),默认是28800s,8小时。
MySQL 默认的最大连接数是 151 个 , 最大是 16384(2^14) 。

使用 SHOW FULL PROCESSLIST;查看查询的执行状态。

一些常见的状态:
| Sleep | 线程正在等待客户端,以向他发送一个新的语句 |
| Query | 线程正在执行查询或往客户端发送数据 |
| Locked | 该查询被其他的查询锁定 |
| Copying to tmp table on disk | 临时结果集合大于tmp_table_size,线程把临时表从存储器内部格式改变为磁盘模式,以节省存储器 |
| Sending data | 线程正在为select语句处理行,同时正在向客户端发送数据 |
| Sorting for group | 线程正在分类,以满足group by要求 |
| Sorting for order | 线程正在分类,以满足oroup by要求 |
2、 查询缓存(Query Cache)
MySQL 内部自带了一个缓存模块。 默认是关闭的。 主要是因为 MySQL 自带的缓存的应用场景有限, 第一个是它要求 SQL 语句必须一模一样。 第二个是表里面任何一条数据发生变化的时候, 这张表所有缓存都会失效。
3、 语法解析和预处理(Parser & Preprocessor)
假如我们随便执行一个字符串或者查询一个不存在表里面的数据,会进行报错,这个就是 MySQL 的 Parser 解析器和 Preprocessor 预处理模块。
这一步主要做的事情是对 SQL 语句进行词法和语法分析和语义的解析。
词法解析
词法分析就是把一个完整的 SQL 语句打碎成一个个的单词。
比如一个简单的 SQL 语句:select name from user where id = 1;它会打碎成 8 个符号, 记录每个符号是什么类型, 从哪里开始到哪里结束。
语法解析
第二步就是语法分析, 语法分析会对 SQL 做一些语法检查,
比如单引号有没有闭合, 然后根据 MySQL定义的语法规则, 根据 SQL 语句生成一个数据结构。 这个数据结构我们把它叫做解析树。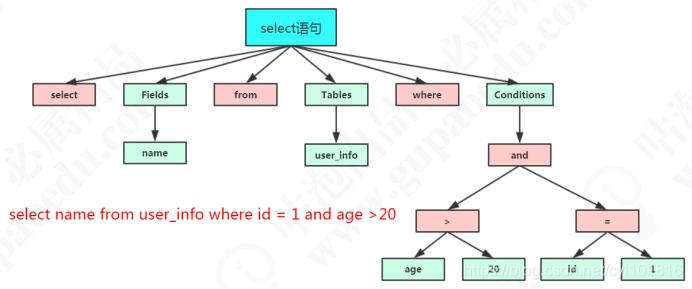
预处理器(Preprocessor)
如果表名错误, 会在预处理器处理时报错。它会检查生成的解析树, 解决解析器无法解析的语义。 比如, 它会检查表和列名是否存在, 检查名字和别名, 保证没有歧义。
4、 查询优化(Query Optimizer) 与查询执行计划
什么是优化器?
这里存在一个问题:一条 SQL 语句是不是只有一种执行方式? 或者说数据库最终执行的 SQL 是不是就是我们发送的 SQL?
这个答案是否定的。 一条 SQL 语句是可以有很多种执行方式的。 但是如果有这么多种执行方式, 这些执行方式怎么得到的? 最终选择哪一种去执行? 根据什么判断标准去选择?
这个就是 MySQL 的查询优化器的模块(Optimizer) 。
查询优化器的目的就是根据解析树生成不同的执行计划, 然后选择一种最优的执行计划, MySQL 里面使用的是基于开销(cost) 的优化器, 那种执行计划开销最小, 就用哪种。
使用如下命令查看查询的开销:
show status like 'Last_query_cost';
如果我们想知道优化器是怎么工作的, 它生成了几种执行计划, 每种执行计划的 cost 是多少, 应该怎么做?
优化器是怎么得到执行计划的?
https://dev.mysql.com/doc/internals/en/optimizer-tracing-typical-usage.html
首先我们要启用优化器的追踪(默认是关闭的) :

启用优化器的追踪是会消耗性能的,因为他要把优化分析的结果写到表里面去,接着再执行一个sql语句,优化器会生成执行计划,这个时候优化器分析的的过程已经记录到系统表里面去了。
优化器可以做什么?
MySQL 的优化器能处理哪些优化类型呢?
比如:
1、 当我们对多张表进行关联查询的时候, 以哪个表的数据作为基准表。
2、 select * from user where a=1 and b=2 and c=3, 如果 c=3 的结果有 100 条, b=2 的结果有 200条, a=1 的结果有 300 条, 你觉得会先执行哪个过滤?
3、 如果条件里面存在一些恒等或者恒不等的等式, 是不是可以移除。
4、 查询数据, 是不是能直接从索引里面取到值。
5、 count()、 min()、 max(), 比如是不是能从索引里面直接取到值。
6、 其他。
优化器得到的结果
优化器最终会把解析树变成一个查询执行计划, 查询执行计划是一个数据结构。当然, 这个执行计划是不是一定是最优的执行计划呢? 不一定, 因为 MySQL 也有可能覆盖不到所有的执行计划。
MySQL 提供了一个执行计划的工具。 我们在 SQL 语句前面加上 EXPLAIN, 就可以看到执行计划的信息。
EXPLAIN select name from user where id=1;
5、 存储引擎(Storage Engine)
我们的数据是放在哪里的? 执行计划在哪里执行? 是谁去执行?
存储引擎基本介绍
在关系型数据库里面, 数据是放在表里面的。 我们可以把这个表理解成 Excel 电子表格的形式。所以我们的表在存储数据的同时, 还要组织数据的存储结构, 这个存储结构就是由我们的存储引擎
决定的, 所以我们也可以把存储引擎叫做表类型。在 MySQL 里面, 支持多种存储引擎, 他们是可以替换的, 所以叫做插件式的存储引擎。
为什么要搞这么多存储引擎呢? 一种还不够用吗?
是因为我们在不同的业务场景中对数据操作的要求不同, 这些不同的存储引擎通过提供不同的存储机制、 索引方式、 锁定水平等功能, 来满足我们的业务需求。
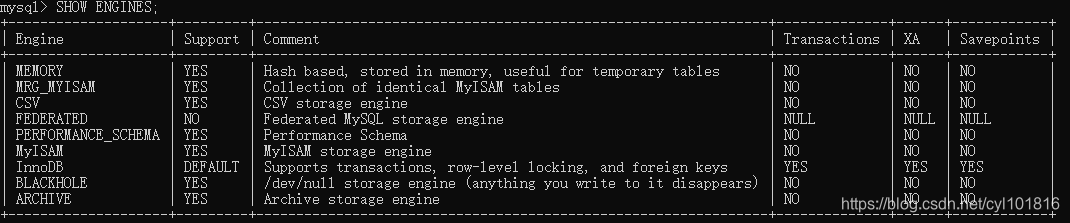
查看存储引擎
查看当前数据库所支持的存储引擎:SHOW ENGINES;
查看数据库表的存储引擎:SHOW TABLE STATUS FROM `setalone`;
在 MySQL 里面, 我们创建的每一张表都可以指定它的存储引擎, 它不是一个数据库只能使用一个存储引擎。 而且, 创建表之后还可以修改存储引擎。
数据库存放数据的路径:
show variables like 'setalone';
每个数据库有一个自己文件夹,任何一个存储引擎都有一个 frm 文件, 这个是表结构定义文件。
关于存储引擎后续再进行详细探讨。
7、 执行引擎( Query Execution Engine) , 返回结果
执行引擎, 它利用存储引擎提供了相应的 API 来完成对存储引擎的操作。 最后把数据返回给客户端, 即使没有结果也要返回。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











