




 本文探讨了路由器如何接收和转发数据报,涉及IP分组转发算法,从路由查找、直接交付到内部网关协议(IGP)如RIP和OSPF,以及外部网关协议(EGP)如BGP的运作。重点介绍了RIP的链路状态更新和OSPF的链路状态数据库构建。
本文探讨了路由器如何接收和转发数据报,涉及IP分组转发算法,从路由查找、直接交付到内部网关协议(IGP)如RIP和OSPF,以及外部网关协议(EGP)如BGP的运作。重点介绍了RIP的链路状态更新和OSPF的链路状态数据库构建。
一、路由器收到待转发的数据报时会做什么?
当路由器收到一个待转发的数据报,在从路由表得出下一跳路由器的IP地址后,不是把这个地址填入IP数据报,而是送交数据链路层的网络接口软件。网络接口软件负责把下一跳路由器的IP地址转换成硬件地址(必须使用ARP),并将此硬件地址放在链路层的MAC帧的首部,然后根据这个硬件地址找到下一跳路由器。
二、路由器的分组转发算法
路由器的分组转发算法如下:
- 从IP数据报的首部提取目的主机的IP地址D,得出目的网络地址为N。
- 若N就是与此路由器直接相连的某个网络地址,则进行直接交付,不需要再经过其他的路由器,直接把数据报交付给目的主机(这里包括把目的主机的地址D转换为具体的硬件地址,把数据报封装成MAC帧,再发送此帧);否则就是间接交付,执行第3步。
- 若路由表中有目的地址为D的特定主机路由(对特定的目的主机指明一个路由),则把数据报传送给路由表中所指明的下一跳路由表;否则,执行4。
- 若路由表中有到达网络N的路由,则把数据报传送给路由表中所指明的下一跳路由器;否则,执行5。
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;否则,执行6。
- 报告转发分组出错。
路由表中并没有给分组指明到某个网络的完整路径。路由表所指出的是,到达某个网络应当先先到达某个路由器(即下一跳路由器),在到达下一跳路由器后,再继续查找其路由表,知道再下一步应当到哪个路由器。这样一步一步地查找下去,直到最后到达目的网络。
上述内容所描述的是IP层是怎样根据路由表的内容进行分组转发,并没有涉及路由表一开始是如何建立的以及路由表中的内容是如何进行更新的。下面对此进行讨论描述。
三、互联网路由选择协议
互联网把路由选择协议划分为两大类,即:
- 内部网关协议 IGP(Interior Gateway Protocol) 即在一个自治系统(autonomous system,是指在单一技术管理下的一组路由器,这些路由器使用一种自治系统内部的路由选择协议和共同度量,在目前的互联网中,一个大的ISP就是一个自治系统)内部使用的路由选择协议,而这与在互联网中的其他自治系统选用什么路由选择协议无关。目前这类路由选择协议使用得最多,如 RIP 和 OSPF 协议。
- 外部网关协议 EGP(External Gateway Protocol) 若源主机和目的主机处在不同的自治系统中(这两个自治系统可能使用不同的内部网关协议),当数据报传到一个自治系统的边界时,就需要使用一种协议将路由选择信息传递到另一个自治系统中。这样的协议就是外部网关协议 EGP。目前使用最多的外部网关协议是 BGP 的版本4(BGP-4)。
自治系统之间的路由选择也叫做域间路由选择(interdomain routing),而在自治系统内部的路由选择叫做域内路由选择(intradomain routing)。
每个自治系统自己决定在本自治系统内部运行哪一个内部路由选择协议,但是每个自治系统都有一个或多个路由器除运行本系统的内部路由选择协议外,还要运行自治系统间的路由选择协议。
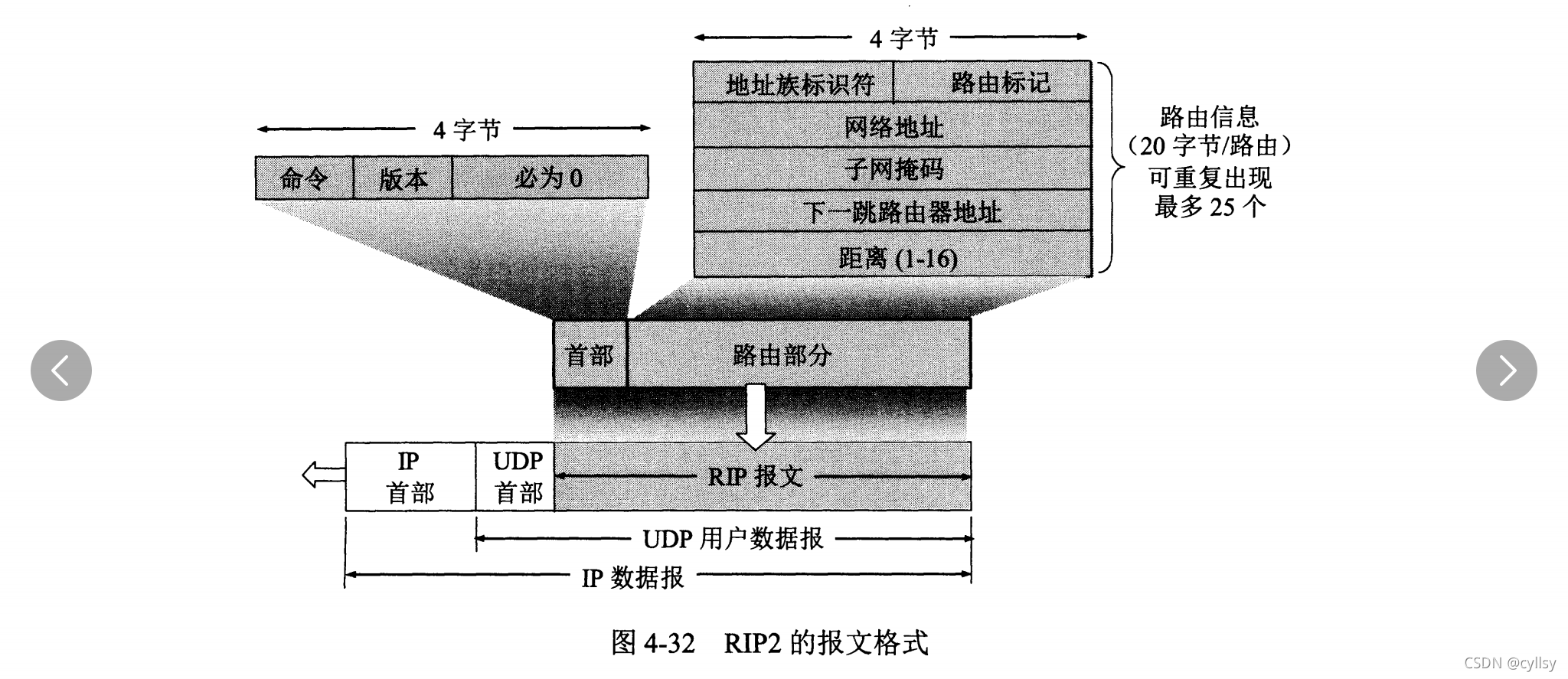
RIP(Routing Information Protocol)协议是一种分布式的基于距离向量的协议,其让一个自治系统中的所有路由器都和自己的相邻路由器定期交换路由信息,并不断更新其路由表,使得从每一个路由器到每一个目的网络的路由都是最短的(即跳数最少)。这里还应注意:虽然所有的路由器最终都拥有了整个自治系统的全局路由信息,但由于每一个路由器的位置不同,它们的路由表当然也应当是不同的(比如到达某个网络的下一跳就很有可能不同)。
RIP协议下路由表的建立:路由器刚开始工作时,其路由表是空的,然后路由器就得出到直接相连的几个网络的距离(这些距离定义为1),接着,每一个路由器也只有和数目非常有限的相邻路由器交换并更新路由信息。但经过若干次的更新以后,所有的路由器最终都会知道本自治系统中任何一个网络的最短距离和下一跳路由器的地址。
RIP协议最大的优点是实现简单,开销较小。RIP 协议的缺点较多,首先,RIP限制了网络规模,它能使用的最大距离为15(16表示不可达);其次,路由器之间交换的路由信息是路由器中的完整路由表,因而随着网络规模的扩大,开销也就增加;最后,“坏消息传播得慢”,使得更新过程的收敛时间过长。RIP协议适用于规模较小的网络中。
OSPF(Open Shortest Path First)协议最主要的特征是使用分布式的链路状态协议(link state protocol),而不是像RIP那样的距离向量协议。此外,OSPF和RIP不同的三个要点如下:(1)向本自治系统中的所有路由器发送信息(此处使用洪泛法,即路由器通过所有输出端口向所有相邻的路由器发送信息,而每一个相邻路由器又再将此信息发往其所有的相邻路由器,但不再发送给刚刚发来信息的那个路由器),而RIP协议是仅仅向自己相邻的几个路由器发送信息;(2)发送的信息是与本路由器相邻的所有路由器的链路状态(说明本路由器都和哪些路由器相邻,以及该链路的“度量”),但这只是路由器所知道的部分信息,而RIP协议发送的信息是到所有网络的距离和下一跳路由器,即其路由表;(3)只有当链路状态发生变化时,路由器才向所有路由器用洪泛法发送此信息,而RIP是不管拓扑结构有无发生变化,路由器之间都要定期交换路由信息。
OSPF协议使得最终所有的路由器都能建立一个链路状态数据库(link-state database),这个数据库实际上就是全网的拓扑结构。因此,每一个路由器都知道全网共有多少个路由器,以及哪些路由器是相连的,其代价(度量)是多少等等。每个路由器使用链路状态数据库中得到数据,构造出自己的路由表(例如,使用Dijkstra的最短路径优先算法)。对比RIP协议,RIP协议中的每一个路由器虽然知道到所有网络的距离以及下一跳路由器,但却不知道全网拓扑结构(只有到了下一跳路由器,才能知道再下一跳应当怎样走)。
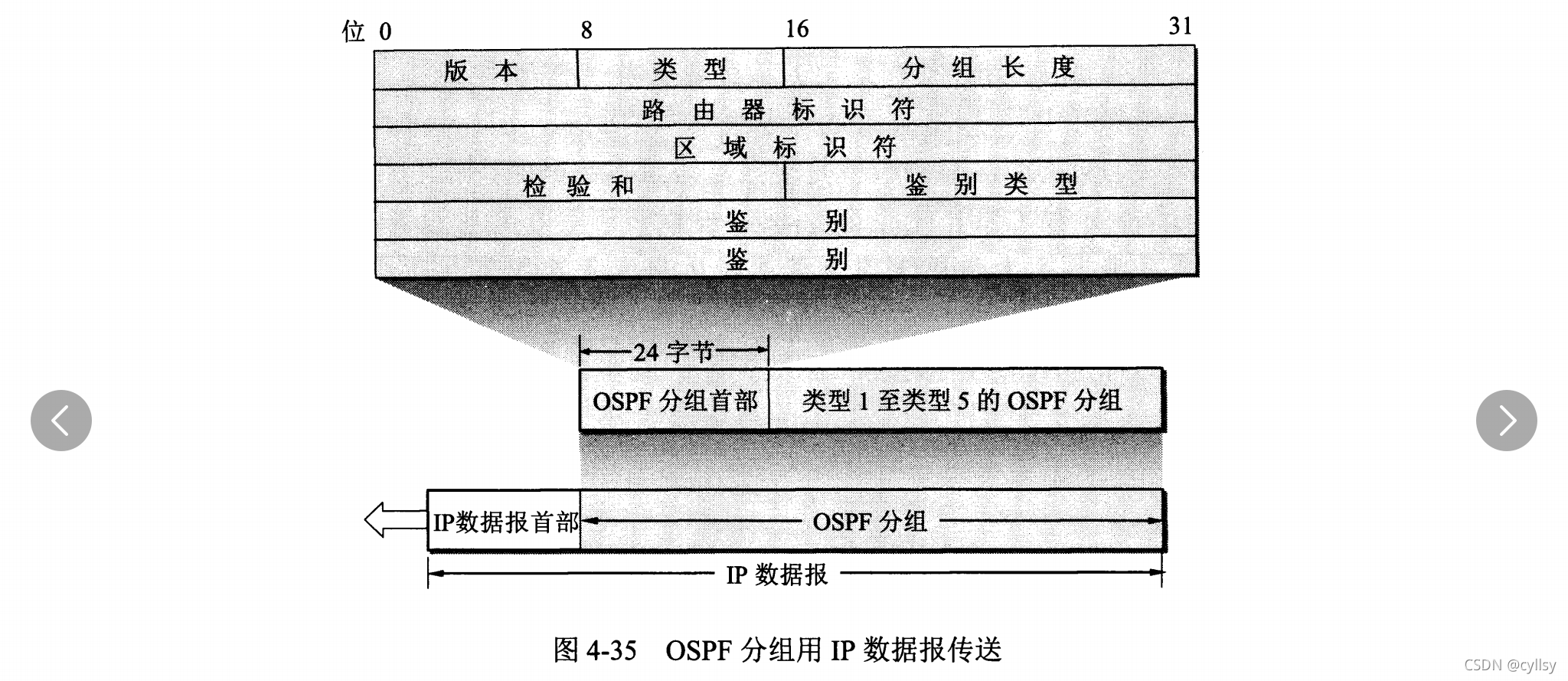
OSPF不使用UDP协议进行传输,而是直接使用IP数据报传送;而RIP协议则使用传输层的用户数据报UDP进行传送。
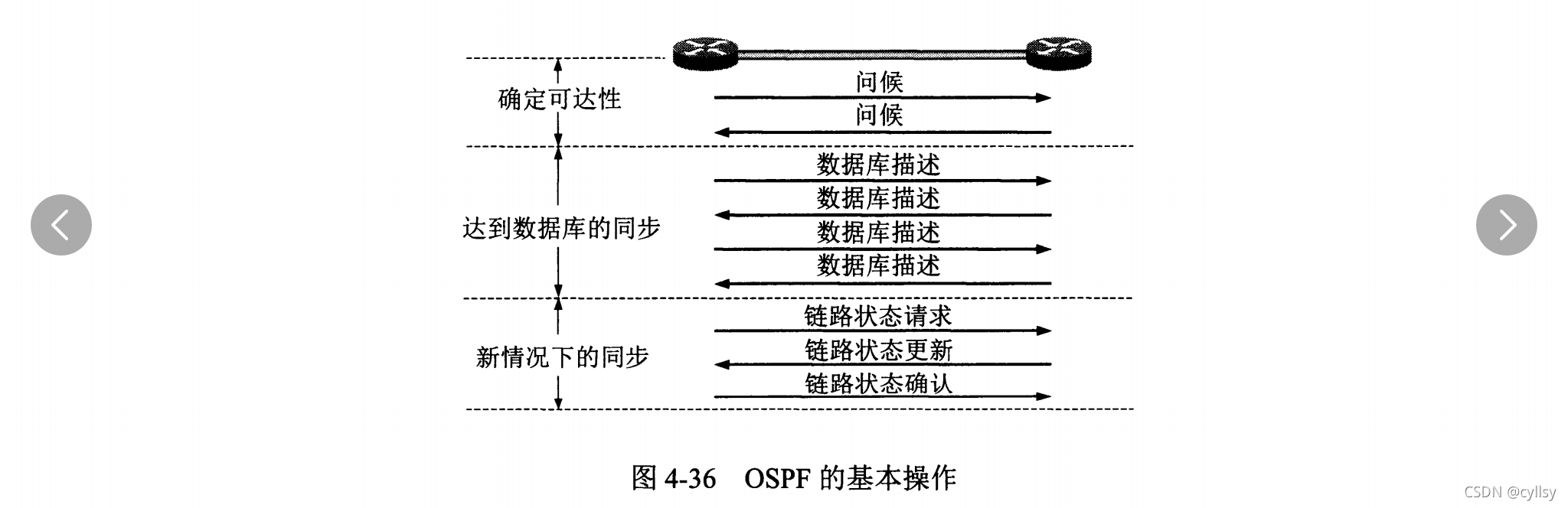
OSPF协议下路由表的建立:当一个路由器开始工作时,它只能通过问候分组得知它有哪些相邻的路由器在工作,以及将数据发往相邻路由器所需的“代价”。OSPF 让每一个路由器用数据库描述分组(OSPF五种分组类型中的一种)和相邻路由器交换本数据库中已有的链路状态摘要信息,摘要信息主要就是指出有哪些路由器的链路状态信息(以及其序号)已经写入了数据库。经过与相邻路由器交换数据库描述分组后,路由器就使用链路状态请求分组(OSPF五种分组类型中的一种),向对方请求发送自己所缺少的某些链路状态项目的详细信息。通过一系列的这种分组交换,全网同步的链路数据库就建立了。如下图示为OSPF的基本操作:
OSPF的五种分组类型:(1)问候分组,用来发现和维持邻站的可达性;(2)数据库描述分组,向邻站给出自己的链路状态数据库中的所有链路状态项目的摘要信息;(3)链路状态请求分组,向对方请求发送某些链路状态项目的详细信息;(4)链路状态更新分组,用洪泛法对全网更新链路状态,此分组是最复杂的,也是OSPF协议最核心的部分;(5)链路状态确认分组,对链路更新分组的确认。
外部网关协议BGP:与内部网关协议(如RIP或OSPF)的区别来看,内部网关协议主要是设法使数据报在一个AS中尽可能有效地从源站传送到目的站,在一个AS内部也不需要考虑其他方面的策略;而BGP则不同,它使用的环境并不是在AS内部,而是在AS之间,主要原因为:(1)互联网规模太大,使得自治系统AS之间的路由选择非常困难;(2)自治系统AS之间的路由选择必须考虑有关策略。
边界网关协议BGP只能是力求寻找一条能够到达目的网络且比较好的路由,而并非要寻找一条最佳路由。BGP采用了路径向量路由选择协议,它与距离向量协议和链路状态协议都有很大区别。
在配置BGP时,每一个自治系统的管理员要选择至少一个路由器作为该自治系统的“BGP发言人”(一般是BGP边界路由器,当然也可以不是),一个BGP发言人与其他AS 的BGP发言人要交换路由信息,就要先建立TCP连接(端口号为179),然后在此连接上交换BGP报文以建立BGP会话,利用BGP会话交换路由信息。使用TCP连接交换路由信息的两个BGP发言人,彼此成为对方的邻站或对等站。每个BGP发言人除了必须运行BGP协议外,还必须运行该自治系统所使用的内部网关协议。
边界网关协议BGP所交换的网络可达性的信息就是要到达某个网络(用网络前缀表示)所要经过的一系列自治系统。BGP协议交换路由信息的结点数量级是自治系统个数的量级,这要比这些自治系统中的网络数少很多。BGP 支持无分类域间路由选择CIDR,因此BGP的路由表也就应当包括目的网络前缀、下一跳路由器,以及到达该目的网络所要经过的自治系统序列。
在BGP刚刚运行时,BGP 的邻站是交换整个BGP路由表,但以后只需要在发生变化时更新有变化部分。关于BGP报文参见计算机网络(第七版)谢希仁——p166-167。

















 6267
6267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









