







写这篇文章是看了好多文章大家只讲了反向传播的权重计算方式,没有讲到偏置计算,查了一些解释才发现和权重计算类似,在此记录一下。
如下图4-6-4神经网络为例,我们记输入层到隐藏层权重参数和偏置参数为1:wij和bi,隐藏层到输出层的权重参数和偏置参数为2:wij和bi.

如下图所示,每个 隐藏层和输出层的节点是在激活函数计算后才输出,因此我们在反向传播中需要对激活函数也进行求导:
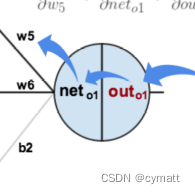
我们记为隐藏层到输出层正向传播激活前的值,
为隐藏层到输出层正向传播激活后的值,
为输入层到隐藏层正向传播激活前的值,
为输入层到隐藏层正向传播激活后的值。
在反向传播中主要应用的原理为梯度下降法,在神经网络中我们使用链式求导来实现。
参数更新是通过输出的损失来更新的,损失一般为模型计算值和真实值之间的偏差,在此单个节点的损失记为
,因此对权重参数的导数求解有如下计算通式:
对于偏置参数的计算和权重参数类似,我们相同的可得如下计算式:
不过由于偏置参数的系数恒为1,因此恒成立,我们可化简上式为:
同样地,我们可以对输入层到隐藏层的权重和偏置进行求导:
至此权重和偏置的导数我们计算完毕,在参数更新时即可使用如下通式进行计算:















 4058
4058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









