







题主最近想自己爬取某网站的全网数据,本以为很简单!数据库选择了mysql,语言选择了python
此网站结构如下;
第一层:主列表分为中国籍、美籍、日本等等 每页30条
第二层:A-Z 字母代表每个人的姓氏开头的人的列表 每个栏目下乐有300页 每页200条 这边爬取数据较大,每个A-Z都生成了单独的表
第三层:为每个人下属的作品列表 这个约10页 每页30条
第四层:为每个作品的详情
题主开始:首先每一层,都有一个爬取的方法,并且每一层的调用都是递归调用,除了第四层之外,都是通过page_no和total_page做比较,然后递归,python的大致代码如下:
def load_list(url,pageNo,params):
data_list = load_url(url,pageNo,params)
data_list_json = json.loads(data_list)
total_page = data_list_json.get("totalPage")
data_list = data_list_json.get("data")
for data in data_list:
//下一层的逻辑
if total_page>pageNo:
load_list(url,pageNo,params)
题主就开始在windows机器上跑了,遇到了一个坑跑了10分钟,竟然卡住了,进程没有退出,后来研究发现python中urlopen需要设置超时参数,否则一致处于等待状态,
改动过后准确无误,准备上线(ubuntu 16.04系统),由于本人的服务器只有1G内存,没想跑了一段时间就自动挂了
查看系统日志/var/log/syslog 发现原因是进程out of memery 被系统进程杀了
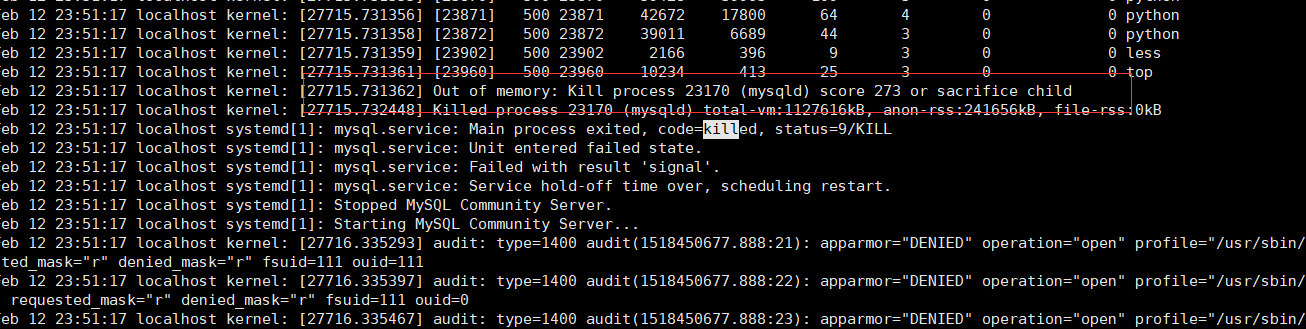
通过各种python性能检测工具发现,代码并没有问题,脑子一转,猜测是由于各种递归,由于递归调用层级多,每层数量有多,导致每次递归没有处理完,内存就out of memery了!
后台想了 准备引入redis 代码如下:
def load_list(url,pageNo,params):
data_list = load_url(url,pageNo,params)
data_list_json = json.loads(data_list)
total_page = data_list_json.get("totalPage")
data_list = data_list_json.get("data")
for data in data_list:
//下一层的逻辑
if total_page>pageNo:
RedisUtils.push(层级名,"%s_%s_%s" % (url,pageNo,params))
然后每一层新启一个守护线程:
class Thread(threading.Thread): def run(self): while True: val = RedisUtils.pop(RedisUtils.NAME) if val: val_list = val.split("_") if len(val_list) is 3: Data.load_url(val_list[0], val_list[1], val_list[2]) else: time.sleep(3)这样你会发现,虽然有了线程,但是通用以mysql连接,是会报
Lost connection to MySQL server during query
这样我又把线成做了一线改动
class Thread(threading.Thread): def __init__(self):
threading.Thread.__init__(self) self.db = MySqlUtils.Mysql(MySqlUtils.db_name) passdef run( self): while True: val = RedisUtils.pop(RedisUtils.NAME) if val: val_list = val.split( "_") if len(val_list) is 3: Data.load_url(val_list[ 0] , val_list[ 1] , val_list[ 2]) else: time.sleep( 3)
结果mysql是不报错了,但是发现最后一层的那个线程总是不能及时执行,突然想到,python存在一个全局锁的概念
最后决定采用进程去处理,并且编写了以shell脚本去启动每个进程,至此,一项简单的项目就不简单了
print "End loadMusicThread:" + val + str(datetime.now())
补充:后面继续监控服务器信息,发现,redis-server老是挂,由于redis是内存数据库数据增多到时oom(out of memery)被ubuntu系统监控进程杀死,最后鉴于服务器硬件水平,在redis.push之前加了一条
while 10000 <= r.llen(key):
time.sleep(60)
可以说鉴于貌似完美的解决了问题。















 3190
3190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









