







我们已经在“ 单链表排序(冒泡排序法)“中探讨过怎样用冒泡排序法进行单链表的排序,但是在各种排序算法中,冒泡排序并非最高效的,对链表这一特定数据结构而言,最好使用归并排序算法。而堆排序、快速排序这些在数组排序时性能非常好的算法,用在只能“顺序访问“的链表中却不尽如人意(由于无法对链表随机访问,快速排序的的效果并不好,堆排序也是无法实现的),但是归并排序却可以,它不仅保持了O(nlogn)的时间复杂度,而且它的空间复杂度也从O(n)降到了o(1),除此之外,归并排序是分治法的实现。
实现过程中,用到了“ 归并排序(递归实现)“、“ 寻找单链表的中间节点“和“ 合并两个有序的链表(非交叉)“中的知识点。
具体实现如下:
#include <iostream>
typedef struct node
{
int data;
struct node *next;
} NODE;
NODE *create_end(int arr[], int len)
{
NODE *head = (NODE *)malloc(sizeof(NODE *));
head->next = NULL;
NODE *end = head;
for (int i = 0; i < len; i++) {
NODE *p = (NODE *)malloc(sizeof(NODE *)); // 也可用 new NODE();
p->data = arr[i];
end->next = p;
end = p;
}
end->next = NULL;
return head;
}
// 此方法适用于不带头节点的单链表的打印,对于带头节点的单链表要稍作处理。
void print(NODE *head)
{
if (head == NULL) return;
while (head != NULL) {
printf("%d ",head->data);
head = head->next;
}
}
// 适用于无头单链表(利用快慢指针找链表的中间位置并将链表一分为二)
// 当链表中有偶数个元素时,最中间的两个节点都可以算作中间节点;
// 但通过该方法查找到的是前面那个节点;如{1,2,3,4,5,6},通过该方法查找到的中间节点是3。
// 将链表一分为二时,要返回第二部分的链表首元素(4)。
NODE *searchMid(NODE *head) // 找中点的同时,拆分链表。
{
NODE *fast = head;
NODE *slow = head;
NODE *mid = NULL;
NODE *mid_aft = NULL;
while (fast != NULL && fast->next != NULL && fast->next->next != NULL) // 注意点1:此处用的是fast。
{
fast = fast->next->next;
slow = slow->next;
}
mid = slow;
mid_aft = mid->next;
mid->next = NULL; // 将链表一分为二
return mid_aft;
}
// 合并两个有序链表
// 为什么使用引用形式的形参?这样可以不用有返回值,也不用在外部新增一个参数来接受返回值了。
void Merge(NODE *&head1, NODE *head2)
{
NODE *p1 = head1, *p2 = head2;
NODE *head3 = (NODE *)malloc(sizeof(NODE)); //合并链表,不需要等长的存储空间;只需开辟一个临时节点(作为头节点)
NODE *p3 = head3;
while (p1 != NULL && p2 != NULL) // 注意点2:此处用的是p1和p2,而不是p1->next和p2->next。
{
if (p1->data <= p2->data)
{
p3->next = p1; // 注意点3:此处用的是p3,而不是head3。
p3 = p1; // p3在合并过程中,始终指向合并链表的当前尾节点;
p1 = p1->next;
}
else
{
p3->next = p2;
p3 = p2;
p2 = p2->next;
}
}
if (p1 == NULL) // 注意点4:此处用的是p1,而不是p1->next。
p3->next = p2;
if (p2 == NULL)
p3->next = p1;
head1 = head3->next;// head1重新指向合并后的链表(head3是头节点,不包含链表数据)
free(head3); // 注意点5
}
// 归并排序
// 为什么使用引用形式的形参?这样可以不用有返回值,也不用在外部新增一个参数来接受返回值了。
void MergeSort(NODE *&head) {
if (head == NULL || head->next == NULL) return; // 递归终止条件(当链表长度小于等于1时,即可不用再分了)
NODE *head1, *head2;
head1 = head;
head2 = searchMid(head);
MergeSort(head1);
MergeSort(head2);
Merge(head1, head2);
head = head1;// 最终归并排序的结果
}
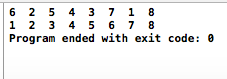
int main(int argc, const char * argv[]) {
int arr[] = {6,2,5,4,3,7,1,8};
int len = sizeof(arr)/sizeof(int);
NODE *head = create_end(arr, len);
// 排序前
print(head->next);
printf("\n");
// 归并排序
MergeSort(head->next);
// 排序后
print(head->next);
printf("\n");
return 0;
}输出如下:
知识点小记:
(1)类比于数组或者连续内存的归并排序。
<1> 单链表归并排序的递归的思路是,将整个链表一直二分,二分成一个个单记录,再反过来对它们执行合并有序链表算法,并层层向上,最终完成对整个链表的排序。
<2> 合并有序链表的算法与合并两个有序数组也有一点不同,即后者需要将总长度的辅助空间“复制”进来。但是对于链表,只需要改变他们的指针即可。即在空间复杂度上降低了。这也是在链表排序上选择归并排序的优势之一。
<3> 另外需要提到的一个技巧,即快慢指针法,此方法利用不同遍历速度的两个指针,可以按照一个比例定位整体链表的位置。这个思想方法可以用在很多地方。
(2)内存泄漏问题
NODE *searchMid(NODE *head)
{
NODE *fast = head;
NODE *slow = head;
NODE *mid = NULL; // 1
NODE *mid_aft = NULL;
while (fast != NULL && fast->next != NULL && fast->next->next != NULL)
{
fast = fast->next->next;
slow = slow->next;
mid = slow;
}
mid_aft = mid->next; // 2
mid->next = NULL;
return mid_aft;
}分析:
2 中存在内存泄漏;因为若while循环不成立,那么此行代码就相当于 NULL = NULL->next; 会造成内存泄漏。
解决方案:1中的mid 初始化为 NODE *mid = head 即可。
(3)如果在合并两个有序链表的方法(Merge)中,不想开辟新的存储空间,那么可以考虑做如下修改。
void Merge(NODE *&head1, NODE *head2)
{
NODE *p1 = head1, *p2 = head2;
NODE *head3 = NULL;
NODE *p3 = NULL;
if (p1->data <= p2->data)
{
head3 = p3 = p1;
p1 = p1->next;
}
else
{
head3 = p3 = p2;
p2 = p2->next;
}
while (p1 != NULL && p2 != NULL)
{
if (p1->data <= p2->data)
{
p3->next = p1,
p1 = p1->next,
p3 = p3->next;
}
else
{
p3->next = p2,
p2 = p2->next,
p3 = p3->next;
}
}
if (p1 == NULL)
p3->next = p2;
if (p2 == NULL)
p3->next = p1;
head1 = head3;// head1重新指向合并后的链表
}














 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









