






【目的】:定期一小时监控Yarn上的任务 并且如果失败任务有新增 就告警推送@所有人。
【方法】:采用Yarn api方式 每隔一个小时进行一次采集 并把状态保留下来推送出去
并把当前失败任务数和上一个小时任务失败数做对比 如果大于上一个小时任务失败数 就告警出来@所有人
【效果图】
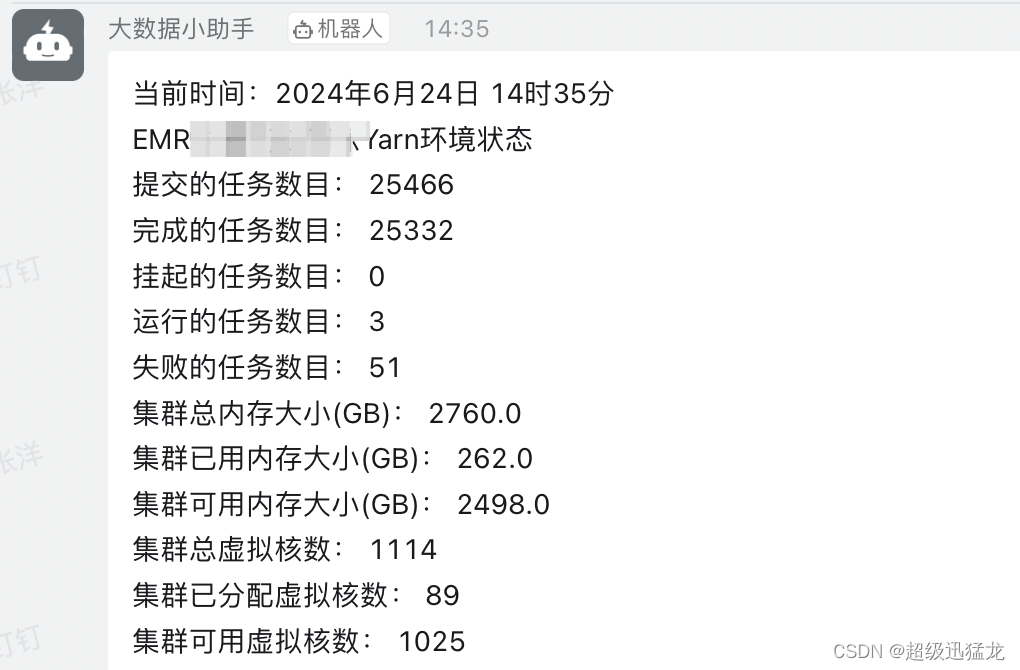
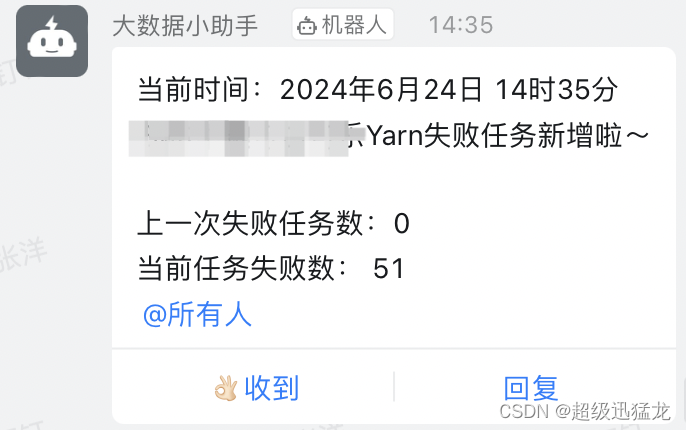
话不多说 直接上代码:
首先上yarn api采集并保存的代码:
url_hdfs_namenode = f"http://{ip}/api/v2/instance/product/Hadoop/service/yarn_resourcemanager"
response_yarn_list = session.get(url=url_hdfs_namenode).json()['data']['list']
try:
for yarn in response_yarn_list:
if yarn['status'] == 'running':
yarn_data = session.get(f"http://{yarn['ip']}:18088/ws/v1/cluster/metrics",
verify=False).json()['clusterMetrics']
print('yarn', ' ', 'resource_manager', ' ', '提交的任务数目', ' ', yarn['ip'], ' ',
yarn_data['appsSubmitted'])
print('yarn', ' ', 'resource_manager', ' ', '完成的任务数目', ' ', yarn['ip'], ' ',
yarn_data['appsCompleted'])
print('yarn', ' ', 'resource_manager', ' ', '挂起的任务数目', ' ', yarn['ip'], ' ',
yarn_data['appsPending'])
print('yarn', ' ', 'resource_manager', ' ', '运行的任务数目', ' ', yarn['ip'], ' ',
yarn_data['appsRunning'])
print('yarn', ' ', 'resource_manager', ' ', '失败的任务数目', ' ', yarn['ip'], ' ',
yarn_data['appsFailed'])
print('yarn', ' ', 'resource_manager', ' ', '集群总内存大小(GB)', ' ', yarn['ip'], ' ',
yarn_data['totalMB'] / 1024)
print('yarn', ' ', 'resource_manager', ' ', '集群已用内存大小(GB)', ' ', yarn['ip'], ' ',
yarn_data['allocatedMB'] / 1024)
print('yarn', ' ', 'resource_manager', ' ', '集群可用内存大小(GB)', ' ', yarn['ip'], ' ',
yarn_data['availableMB'] / 1024)
print('yarn', ' ', 'resource_manager', ' ', '集群总虚拟核数', ' ', yarn['ip'], ' ',
yarn_data['totalVirtualCores'])
print('yarn', ' ', 'resource_manager', ' ', '集群已分配虚拟核数', ' ', yarn['ip'], ' ',
yarn_data['allocatedVirtualCores'])
print('yarn', ' ', 'resource_manager', ' ', '集群可用虚拟核数', ' ', yarn['ip'], ' ',
yarn_data['availableVirtualCores'])
csv.writer(f).writerow(
['yarn', 'resource_manager', '提交的任务数目', yarn['ip'], yarn_data['appsSubmitted']])
csv.writer(f).writerow(
['yarn', 'resource_manager', '完成的任务数目', yarn['ip'], yarn_data['appsCompleted']])
csv.writer(f).writerow(
['yarn', 'resource_manager', '挂起的任务数目', yarn['ip'], yarn_data['appsPending']])
csv.writer(f).writerow(
['yarn', 'resource_manager', '运行的任务数目', yarn['ip'], yarn_data['appsRunning']])
csv.writer(f).writerow(['yarn', 'resource_manager', '失败的任务数目', yarn['ip'], yarn_data['appsFailed']])
csv.writer(f).writerow(
['yarn', 'resource_manager', '集群总内存大小(GB)', yarn['ip'], yarn_data['totalMB'] / 1024])
csv.writer(f).writerow(
['yarn', 'resource_manager', '集群已用内存大小(GB)', yarn['ip'], yarn_data['allocatedMB'] / 1024])
csv.writer(f).writerow(
['yarn', 'resource_manager', '集群可用内存大小(GB)', yarn['ip'], yarn_data['availableMB'] / 1024])
csv.writer(f).writerow(
['yarn', 'resource_manager', '集群总虚拟核数', yarn['ip'], yarn_data['totalVirtualCores']])
csv.writer(f).writerow(
['yarn', 'resource_manager', '集群已分配虚拟核数', yarn['ip'], yarn_data['allocatedVirtualCores']])
csv.writer(f).writerow(
['yarn', 'resource_manager', '集群可用虚拟核数', yarn['ip'], yarn_data['availableVirtualCores']])
break
except Exception as e:
print(e)对比当前时间和上一次时间的任务情况
def filed_task_add():
time_H = get_file_time_H()
prev_hour = get_prev_hour_time_H()
i = 0
for filename in os.listdir('./yarn/'):
# i = i+1
# print(i)
if time_H in filename:
with open(os.path.join('./yarn/', filename), 'r') as f:
for line in f:
if '失败的任务数目' in line:
failed_tasks_current = int(line.split(',')[-1])
print(f"当前失败的任务数:{failed_tasks_current}")
break
elif prev_hour in filename:
with open(os.path.join('./yarn/', filename), 'r') as f:
for line in f:
if '失败的任务数目' in line:
failed_tasks_prev = int(line.split(',')[-1])
print(f"上一次失败任务数: {failed_tasks_prev}")
break
try:
if failed_tasks_current > failed_tasks_prev:
print(f"任务失败数增加: \n 上一次失败任务数:{failed_tasks_prev} \n当前任务失败数: {failed_tasks_current}")
return True, failed_tasks_current, failed_tasks_prev
else:
print("任务失败并没有增加.")
return False, failed_tasks_current
except Exception as e:
print(e)
return False, failed_tasks_currentdingding发送代码就不上啦 大家都很熟悉啦
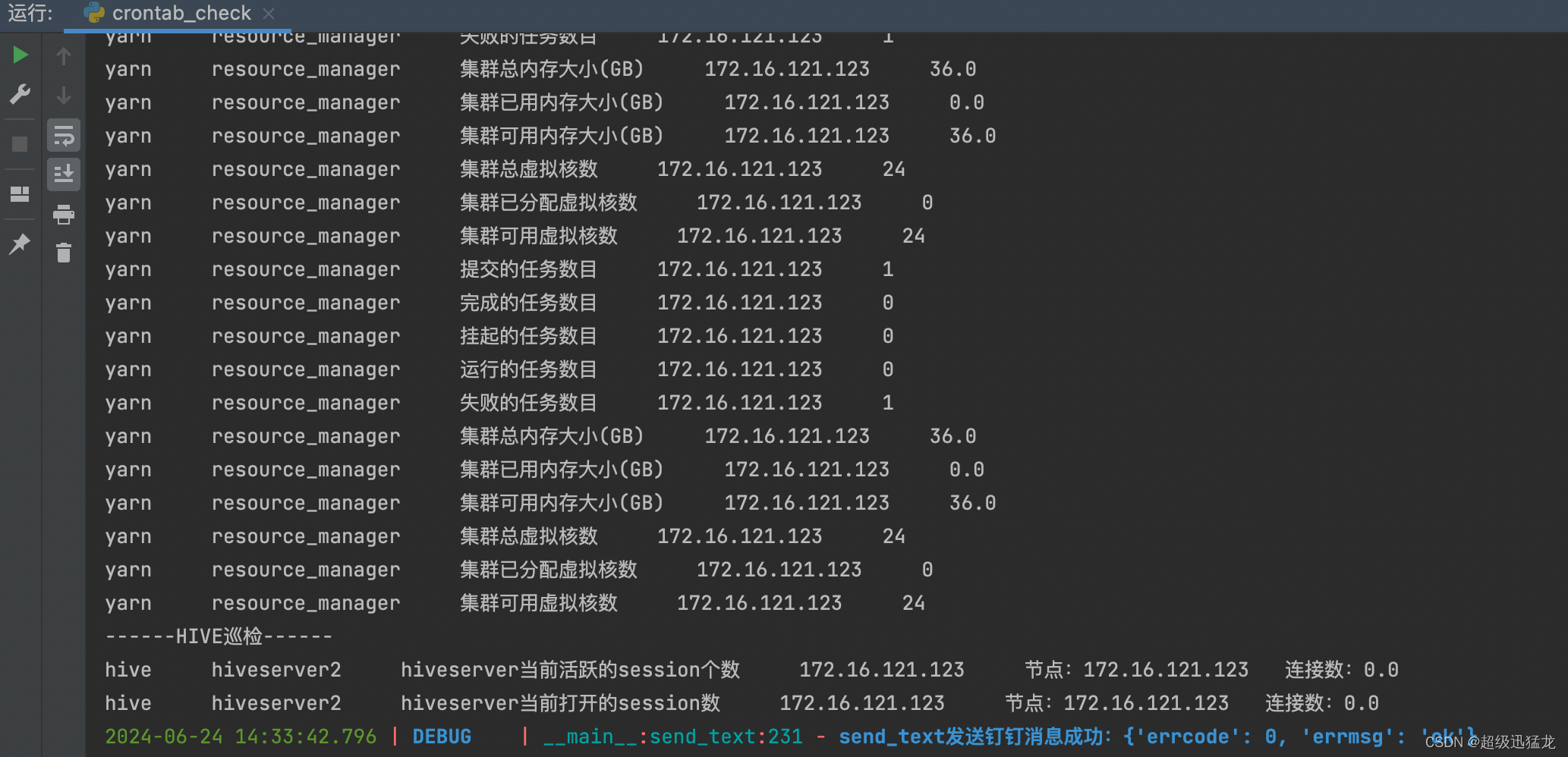
完成~















 3659
3659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









