









探讨yarn的监控数据采集方式以及需要关注的核心指标,便于日常生产进行监控和巡检。
1. 监控指标采集
监控指标的采集方式使用promethues + jmx_prometheus_javaagent的方式进行,具体方案部署方案可以参考HDFS监控方法以及核心指标
需要注意的是,调整几个关键配置,
1, 配置resourcemanager.yaml和nodemanager.yaml
root@Master:/usr/local/hadoop/jmx# cat /usr/local/monitor/resourcemanager.yaml
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
root@Master:/usr/local/hadoop/sbin# cat /usr/local/monitor/nodemanager.yaml
startDelaySeconds: 0
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
root@Master:/usr/local/hadoop/sbin#
2, 配置yarn相关的OPTS
vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
# 增加jmx_prometheus_javaagent采集配置
export HADOOP_RESOURCEMANAGER_OPTS="$HADOOP_RESOURCEMANAGER_OPTS -javaagent:/usr/local/monitor/jmx_prometheus_javaagent-0.20.0.jar=10000:/usr/local/monitor/resourcemanager.yaml"
export HAROOP_NODEMANAGER_OPTS="$YARN_NODEMANAGER_OPTS -javaagent:/usr/local/monitor/jmx_prometheus_javaagent-0.20.0.jar=10002:/usr/local/monitor/nodemanager.yaml"
小技巧:
由于版本问题,有时候一直搞不明白,yarn使用的是哪个一个配置(/usr/local/hadoop/etc/hadoop/yarn-env.sh中注释的是YARN_RESOURCEMANAGER_OPTS,但实际使用的是HADOOP_RESOURCEMANAGER_OPTS)容易搞晕。
可以到/usr/local/hadoop/libexec/hadoop-functions.sh文件中打印输出配置,以判断具体是哪个变量。
vim /usr/local/hadoop/libexec/hadoop-functions.sh
3,正常启动yarn
cd /usr/local/hadoop/sbin
./yarn-daemon.sh start resourcemanager
./yarn-daemon.sh start nodemanager
4, 启动的进程中会携带jmx_prometheus_javaagent参数

如果遇到启动失败,并且出现如下提示,可以调整一下yarn的启动用户即可
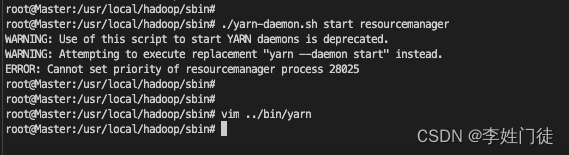
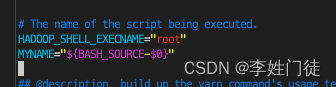
vim /usr/local/hadoop/bin/yarn
# 修改启动用户为root
HADOOP_SHELL_EXECNAME="root"
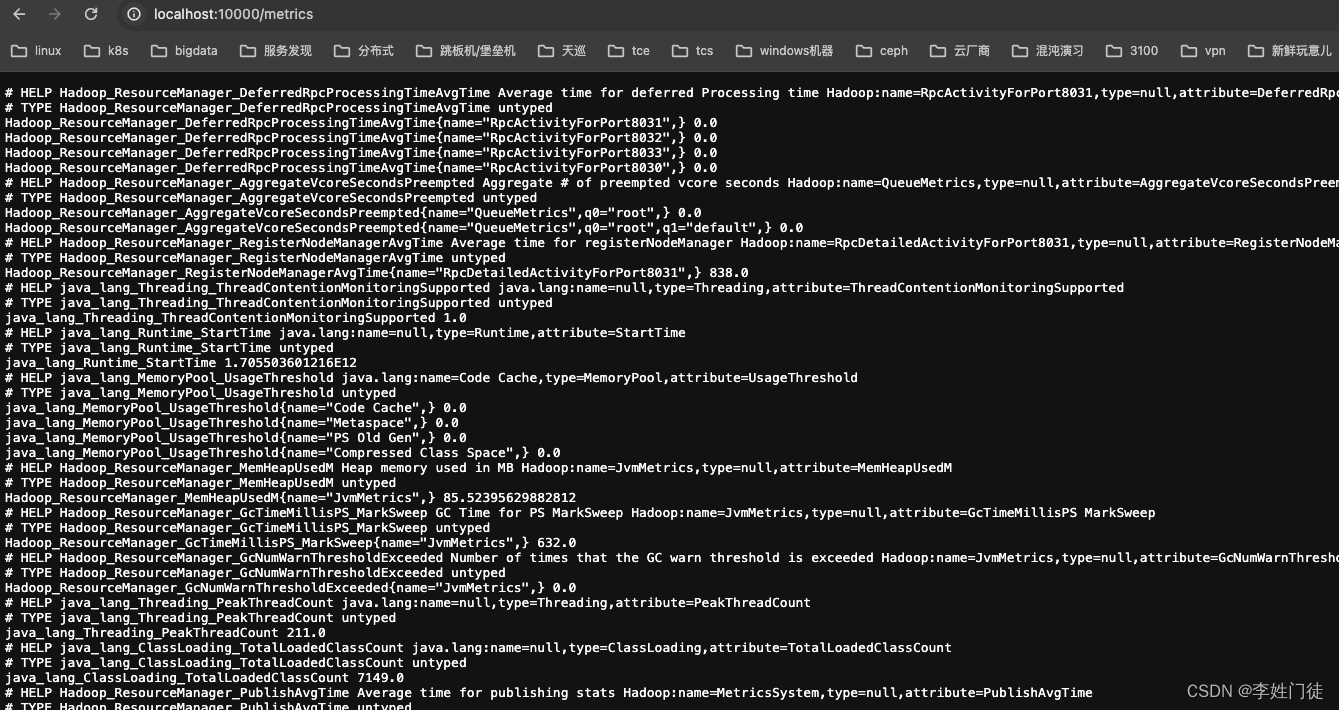
5, 查看相关的指标
# resourcemanager指标
curl localhost:10000/metrics
# nodemanager指标
curl localhost:10002/metrics
配置prometheus等细节,可以参考可以参考HDFS监控方法以及核心指标,本文不再继续赘述。
2. 核心告警指标
2.1 RM核心指标梳理
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 |
| 主备情况 | haState | 1:主,0:备 | 集群必须包含1主1备 |
| CallQueueLength | 当前 RPC 处理队列长度 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| RpcProcessingTimeAvgTime | RPC请求平均处理时间 | <= 100ms | rpc处理慢和队列长度有一定的关系,也是nn性能差或者压力大导致,需要注意调优jvm或者线程,以及更换nn更好的磁盘,提升磁盘io能力 |
| NumOpenConnections | 当前打开的连接个数 | <= 1000 | 不宜有太多的链接,涉及性能问题,根据实际情况调整 |
| NumDecommissionedNMs | 当前打开的连接个数 | <= 0 | 当前 Decommissioned 的 NodeManager 个数 |
| NumLostNMs | 当前打开的连接个数 | <= 0 | 当前 Lost 的 NodeManager 个数 |
| NumUnhealthyNMs | 当前打开的连接个数 | <= 0 | 当前 Unhealthy 的 NodeManager 个数 |
| MemHeapUsedM/MemHeapMaxM | Jvmd堆内内存使用率 | <= 60% | |
|AppsFailed | 当前队列失败的作业个数 | <= 0 | 此告警最好提供给对应的app开发者,酌情处理 |
|PendingContainers | 当前队列的资源请求中 pending 的 container 个数(资源满足,但是还在排队等待创建) | <= 0 | 涉及集群资源配合集群的资源使用率,理想情况下,不应该有pending的containers |
|ReservedContainers | 当前队列中 reserved 的 container 个数 (资源不足,等待资源分配) | <= 0 | 涉及集群资源配合集群的资源使用率,根据资源使用情况进行调整,理想情况下,不应该有申请不到资源的containers |
2.2 NM核心指标梳理
| 指标名称 | 指标说明 | 参考值 | 备注 |
|---|---|---|---|
| 进程 | 进程 | 进程存在 == 1 | |
| CallQueueLength | 当前 RPC 处理队列长度 | <= 1000 | 过长的rpc队列会导致nn处理不过来了,注意调优jvm或者线程数量以及客户端的缓存 |
| RpcProcessingTimeAvgTime | RPC请求平均处理时间 | <= 100ms | rpc处理慢和队列长度有一定的关系,也是nn性能差或者压力大导致,需要注意调优jvm或者线程,以及更换nn更好的磁盘,提升磁盘io能力 |
| MemHeapUsedM/MemHeapMaxM | Jvmd堆内内存使用率 | <= 60% | |
| AvailableVCores / (AllocatedVCores + AvailableVCores ) | NodeManager 可用的 VCore 占比 | <= 90% | 涉及容量资源,不同环境根据实际情况调整 |
| AvailableGB / (AllocatedGB + AvailableGB ) | NodeManager 可用的 内存 占比 | <= 90% | 涉及容量资源,不同环境根据实际情况调整 |
| BytesWrittenMB | 写入 DN 的字节速率 | 根据机器的网卡带宽调整 | |
| BytesReadMB | 读取 DN 的字节速率 | 根据机器的网卡带宽调整 | |
| VolumeFailures | 磁盘故障次数 | <= 0 | |
| DatanodeNetworkErrors | 网络错误统计 | <= 0 | |
| 磁盘使用率 | <= 70 | ||
| 磁盘await | 磁盘读写的await | <= 1ms |














 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









