







目录
CAP 理论是分布式系统设计中的一个重要概念,它描述了在分布式系统中一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个属性之间的权衡。
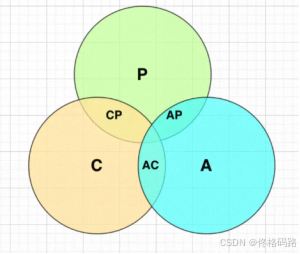
以下是关于 CAP 理论的基本介绍及其在分布式系统设计中的应用:
CAP 理论的定义
CAP 理论指出,在一个分布式系统中,不可能同时实现以下三个目标:
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition tolerance)
这意味着在分布式系统中,必须在一致性和可用性之间做出选择,同时必须保证分区容错性。
三个属性的解释
1. 一致性(Consistency)
定义: 当一个客户端成功提交一个更新后,所有后续的操作都会看到这个更新的结果。
例子: 如果你在银行账户中存入了 100,并且这个操作成功提交了,那么后续的所有查询都应该显示账户余额增加了100,并且这个操作成功提交了,那么后续的所有查询都应该显示账户余额增加了100。
2. 可用性(Availability)
定义: 每个请求都能在合理的时间内得到响应,即使不是最终一致的响应。
例子: 如果你尝试查询你的银行账户余额,系统应该总是能够返回一个结果,即使这个结果不是最新的。
3. 分区容错性(Partition tolerance)
定义: 即使网络分区(网络故障导致的一部分节点无法与其他节点通信)发生时,系统仍然能够正常运作。
例子: 如果银行系统的某个数据中心因为网络问题无法与其他数据中心通信,系统仍然需要能够继续处理客户请求。
CAP 理论的选择
由于分布式系统必须具备分区容错性(P),因此实际上只能在一致性和可用性之间选择一个。这意味着在分布式系统设计时,必须在 C 和 A 之间做出取舍。
选择一致性(CP 系统)
- 特点: 当出现网络分区时,优先保证数据的一致性。
- 例子: 数据库管理系统(如 PostgreSQL)、分布式数据库(如 Cassandra 在某些模式下)。
- 优点: 数据的一致性强,保证所有副本的一致性。
- 缺点: 可能在网络分区期间不可用。
选择可用性(AP 系统)
- 特点: 当出现网络分区时,优先保证系统的可用性。
- 例子: NoSQL 数据库(如 Cassandra 在多数情况下)、分布式缓存(如 Redis Cluster)。
- 优点: 即使在网络分区期间也能提供服务。
- 缺点: 可能导致数据的一致性问题。
实践中的应用
在实际应用中,选择哪种策略取决于系统的具体需求。例如:
- 金融交易系统: 更倾向于 CP 系统,因为数据的一致性非常重要。
- 社交网络: 更倾向于 AP 系统,因为用户体验的连续性更为关键,数据可以稍后达到最终一致性。
如果选择CP
当选择了 CP(一致性和分区容错性)时,系统会有以下效果:
强一致性保障
- 数据在所有节点上保持一致。例如在分布式数据库中,无论对数据进行读写操作,所有节点都会在同一时间呈现相同的数据状态。如多个节点存储用户账户余额信息,当余额发生变更时,所有节点会同时更新,不会出现有的节点数据新、有的节点数据旧的情况,用户在任何节点查询到的余额都是准确且一致的最新数据。
分区容错处理
- 当网络出现分区故障时,系统能够继续运行并保证数据一致性。比如在一个分布式系统中,部分节点因网络问题与其他节点分隔开形成分区,系统会通过一些策略,如在分区内进行数据的独立管理和一致性维护,暂停跨分区的数据操作等,确保在每个分区内数据仍然保持一致。当网络恢复后,系统会自动进行数据同步和整合,使整个系统的数据重新达到一致状态。
可用性的牺牲
- 为了保证一致性和分区容错性,在某些情况下可能会牺牲一定的可用性。例如,当网络分区发生时,为了避免数据不一致,系统可能会拒绝一些读写请求,直到网络恢复或完成数据一致性的修复。这可能导致部分用户在一段时间内无法正常访问系统或进行操作,出现请求超时或被拒绝的情况。
举例说明
- 如果用户A通过某种途径在某银行位于北京和上海的两个网点同时存入1万元,则由于网络分区发生,两个网点之间无法通信,造成数据无法同步,此时用户在北京和上海两个网点都能办理存款业务(保证分区容错性),但是由于用户A在两个网点都暂时无法查询账户最终余额(一致性要求两个网点之间的数据完成同步后才可以查询),保证了一致性型,牺牲了可用性。
如果选择AP
当选择了 AP(可用性和分区容错性)时,系统会有以下效果:
高可用性保障
- 系统会尽可能地保证服务的可用性,即确保用户能够随时访问系统并进行操作。例如,在一个分布式电商系统中,无论系统是否发生网络分区或其他故障,用户都能正常浏览商品、添加商品到购物车、提交订单等。即使部分服务器出现问题,系统也会通过负载均衡、故障转移等机制,将用户请求路由到其他正常工作的服务器上,保证用户的操作能够顺利进行,不会出现长时间等待或无法响应的情况。
分区容错处理
- 与选择 CP 类似,当网络出现分区故障时,系统能够继续运行。各个分区内的节点会独立运行,尽力为本地用户提供服务。例如,在分布式数据库系统中,当网络分区发生时,不同分区内的数据库节点会各自处理本分区内的读写请求,就好像它们是独立的数据库一样。不会因为与其他分区失去联系而停止服务,确保了系统在分区情况下的可用性。
一致性的牺牲
- 为了保证可用性和分区容错性,系统会在一定程度上牺牲数据的强一致性。这意味着在某些情况下,不同节点上的数据可能会出现暂时的不一致。例如,在分布式电商系统中,当用户在不同分区的节点上同时购买同一款商品时,由于分区之间无法及时进行数据同步,可能会出现库存数据在短期内不一致的情况。一个分区的库存可能已经更新,而另一个分区的库存还未更新,导致用户看到的库存信息不准确。不过,系统通常会采用一些最终一致性的策略,在后续的过程中逐渐将数据恢复到一致状态。
举例说明
- 如果用户A通过某种途径在某银行位于北京和上海的两个网点同时存入1万元,则由于网络分区发生,两个网点之间无法通信,造成数据无法同步,此时用户在北京和上海两个网点都能办理存款业务(保证分区容错性),此时,用户A可以在北京或上海任意一个网点查询账户余额(保证了可用性),但是看到的都不是最终的余额(牺牲了一致性)。
总结
CAP 理论帮助我们理解在设计分布式系统时所面临的权衡。在实际设计中,我们需要根据系统的具体需求来决定如何平衡一致性、可用性和分区容错性之间的关系。了解这些概念有助于更好地设计和优化分布式系统。


















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











