










目录
摘要
HDGI使用元路径对异质图中涉及语义的结构进行建模,并利用图卷积模块和语义级注意机制来捕获单个节点的局部表示。通过最大化局部-全局互信息,HDGI有效地学习了基于异质图中不同信息的节点表示。实验表明,HDGI在节点分类和聚类任务上都显著优于最先进的无监督图表示学习方法。通过将学习到的表示输入参数模型,如逻辑回归,与最先进的监督端到端GNN模型相比,我们甚至在节点分类任务中实现了可比的性能。
1 引言
现有的无监督图表示学习模型可以分为基于因式分解的模型和基于边的模型。
基于因式分解的模型通过因式分解样本关联矩阵来捕获全局图信息。通过关联矩阵分解,可以很好地掌握完整的图结构。然而,这些方法忽略了节点属性和局部邻域关系。
基于边的模型通过边的连接或随机游走路径利用局部和高阶邻域信息。如果节点在相同的路径中连接或同时出现,则它们倾向于具有相似的表示。基于边的模型容易保持有限阶的节点相似性。它们缺乏一种保存全局图结构的机制。
而基于互信息的模型同时考虑了局部和全局信息。
2 相关工作
(1)图表示学习
(2)图神经网络
(3)互信息
3 定义
(1)异质图
异构图定义为 G = ( V , E ) \mathcal{G}=(\mathcal{V},\mathcal{E}) G=(V,E),具有节点类型映射函数 ϕ : V → T \phi:\mathcal{V}→\mathcal{T} ϕ:V→T 和边类型映射函数 ψ : E → R ψ:\mathcal{E}→\mathcal{R} ψ:E→R 。其中, ∣ T ∣ + ∣ R ∣ > 2 |\mathcal{T}|+|\mathcal{R}|>2 ∣T∣+∣R∣>2。节点的属性和内容可以编码为初始特征矩阵 X X X。
(2)异质图表示学习
给定 G \mathcal{G} G 和 X X X,表示学习任务是学习低维节点表示 H ∈ R ∣ V ∣ × d H∈\mathbb{R}^{|\mathcal{V}|×d} H∈R∣V∣×d,其中同时包含 G \mathcal{G} G 中的结构信息和 X X X 中的节点属性。学习到的表示 H H H 可以应用于节点分类、节点聚类等下游图相关任务。本文主要学习一种特定类型节点的表示。我们将用于表示学习的节点集表示为目标类型节点 V t \mathcal{V}_t Vt。
元路径,代表了两个节点之间的节点和边类型。形式上,路径 v 1 → R 1 v 2 → R 2 ⋅ ⋅ ⋅ → R n − 1 v n v_1 \stackrel{R_1}{\rightarrow}v_2\stackrel{R_2}{\rightarrow}···\stackrel{R_{n-1}}{\rightarrow}v_n v1→R1v2→R2⋅⋅⋅→Rn−1vn被定义为节点 v 1 v_1 v1和 v n v_n vn之间的元路径,其中 R = R 1 ◦ R 2 ◦ ⋅ ⋅ ⋅ ◦ R n − 1 R=R_1◦R_2◦···◦R_{n-1} R=R1◦R2◦⋅⋅⋅◦Rn−1被定义节点 v 1 v_1 v1和 v n v_n vn之间的复合关系。本文为了简化问题的设置,使用对称且无向的元路径定义目标类型节点 V t \mathcal{V}_t Vt 间的相似性。
我们将本文中使用的元路径集表示为 { Φ 1 , Φ 2 , ⋅ ⋅ ⋅ , Φ P } \{Φ_1,Φ_2,···,Φ_P\} {Φ1,Φ2,⋅⋅⋅,ΦP},其中 Φ i Φ_i Φi表示第 i i i种元路径类型。
(3)基于元路径的邻接矩阵
对于元路径 Φ i Φ_i Φi,如果节点 v i ∈ V t v_i∈\mathcal{V}_t vi∈Vt和 v j ∈ V t v_j∈\mathcal{V}_t vj∈Vt之间存在一个路径实例,我们称 v i v_i vi和 v j v_j vj是基于 Φ i Φ_i Φi的“连接邻居”。这些邻域信息可以用基于元路径的相邻矩阵 A Φ i ∈ R ∣ V t ∣ × ∣ V t ∣ A^{Φ_i}∈\mathbb{R}^{|\mathcal{V}_t|×|\mathcal{V}_t|} AΦi∈R∣Vt∣×∣Vt∣表示,其中 v i v_i vi和 v j v_j vj通过元路径 Φ i Φ_i Φi连接时, A i j Φ i = A j i Φ i = 1 A^{Φ_i}_{ij}=A^{Φ_i}_{ji}=1 AijΦi=AjiΦi=1,否则, A i j Φ i = A j i Φ i = 0 A^{Φ_i}_{ij}=A^{Φ_i}_{ji}=0 AijΦi=AjiΦi=0。
4 HDGI方法
4.1 HDGI体系结构概述
HDGI的概述如图2所示。

表1总结了模型中用到的符号。

HDGI的输入是一个异构图
G
\mathcal{G}
G ,包含
N
N
N个目标类型的节点,其初始
d
d
d维特征用
X
∈
R
N
×
d
X∈\mathbb{R}^{N×d}
X∈RN×d表示,以及元路径集
{
Φ
i
}
i
=
1
P
\{Φ_i\}^P_{i=1}
{Φi}i=1P。基于
{
Φ
i
}
i
=
1
P
\{Φ_i\}^P_{i=1}
{Φi}i=1P,我们可以计算基于元路径集的邻接矩阵
{
A
Φ
i
}
i
=
1
P
\{A^{Φ_i}\}^P_{i=1}
{AΦi}i=1P。
第4.2节中描述的基于元路径的局部表示编码有两个步骤:
- 从 X X X和每个 A Φ i A^{Φ_i} AΦi中学习单个节点表示 H Φ i H^{Φ_i} HΦi,
- 通过一个语义级注意力机制聚合 { H Φ i } i = 1 P \{H^{Φ_i}\}^P_{i=1} {HΦi}i=1P来生成节点表示 H H H。
第4.3节提出了一种全局表示编码器 R \mathcal{R} R,用于从 H H H导出一个图 summary vector s ⃗ \vec{s} s。
discriminator D \mathcal{D} D 的训练目标是最大化正节点和图级 summary s ⃗ \vec{s} s 之间的互信息。
同时,HDGI通过以互信息最大化为目标的反向传播进行端到端优化。
第4.4节中,我们详细阐述了基于互信息的discriminator D \mathcal{D} D 和 负样本生成器 C \mathcal{C} C。
4.2 基于元路径的局部表示编码
4.2.1 针对特定元路径的节点表示学习
使用一个节点级编码器,推导出一个包含初始节点特征
X
X
X和
A
Φ
i
A^{Φ_i}
AΦi信息的节点表示:
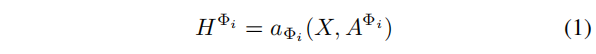
本文考虑了两种编码器:
(1)GCN
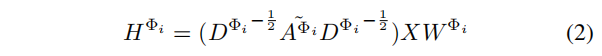
其中,
A
~
Φ
i
=
A
Φ
i
+
I
\widetilde{A}^{Φ_i}=A^{Φ_i}+I
A
Φi=AΦi+I,
D
Φ
i
D^{Φ_i}
DΦi是
A
Φ
i
A^{Φ_i}
AΦi的对角线节点度矩阵。矩阵
W
Φ
i
∈
R
d
×
F
W^{Φ_i}∈\mathbb{R}^{d×F}
WΦi∈Rd×F【
d
d
d是初始特征维度】是滤波器的参数矩阵,它在不同的
A
Φ
A^{Φ}
AΦ之间不共享。
(2)GAT
对于第
m
m
m个节点,其
K
−
h
e
a
d
K-head
K−head 注意力输出可计算为:
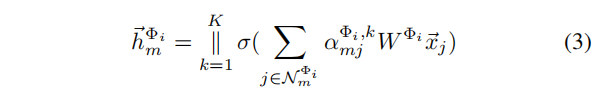
其中,
∣
∣
||
∣∣是连接操作,
W
Φ
i
W^{Φ_i}
WΦi是线性变换参数矩阵,
N
m
Φ
i
\mathcal{N}_m^{Φ_i}
NmΦi是元路径
Φ
i
Φ_i
Φi下节点
m
m
m的邻居集,
α
m
j
Φ
i
,
k
\alpha^{Φ_i,k}_{mj}
αmjΦi,k是由第
k
k
k个注意力机制计算出的归一化注意力系数。
在针对特定元路径的节点表示学习之后,我们得到了节点表示集 { H Φ i } i = 1 P \{H^{Φ_i}\}^P_{i=1} {HΦi}i=1P。
4.2.2 异质图节点表示学习
在这里,我们利用一个语义级注意力层
L
a
t
t
L_{att}
Latt 来学习每个元路径的权重:
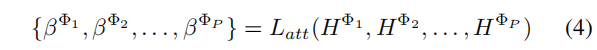
具体来说,不同元路径
Φ
i
Φ_i
Φi的重要性计算如下:
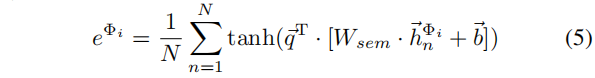
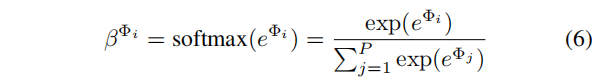
其中,
W
s
e
m
W_{sem}
Wsem是一个线性变换参数矩阵。
q
⃗
\vec{q}
q 是可学习的共享注意力向量。
异质图节点表示
H
H
H由
{
H
Φ
i
}
i
=
1
P
\{H^{Φ_i}\}^P_{i=1}
{HΦi}i=1P的线性组合而得:
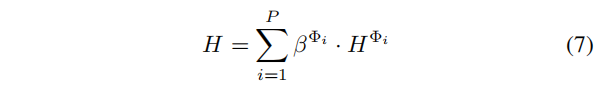
我们的语义级注意力层受到了HAN的启发,但在学习方向上仍存在一些差异。HAN利用分类交叉熵作为损失函数。训练集中的可用标签指导学习方向。在HDGI中学习到的注意力权值由二进制交叉熵损失引导,表示该节点是否属于原图。因此,在HDGI中学习到的权值用于节点的存在。因为没有涉及分类标签,所以权重从已知标签中没有偏差。
表示 H H H作为最终输出的局部特征。需要指出的是,基于元路径的局部表示编码器中的所有参数都为正节点和负节点共享。负节点由负样本生成器生成,我们将在第4.4节中介绍。全局表示编码器利用表示 H H H输出图级 summary,如下一节中所述。
4.3 全局表示编码器
本文考虑了三种编码器函数:
(1)Averaging encoder function
对节点表示取均值作为图级 summary vector
s
⃗
\vec{s}
s:
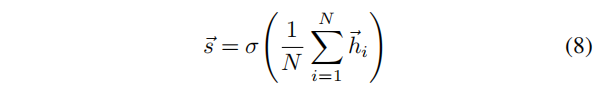
其中,
σ
σ
σ是PReLU激活函数。
(2)Pooling encoder function
将每个节点向量单独输入到一个全连接层。使用元素级的max-pooling操作(对应维度的所有元素取最大值),汇总节点集的信息:
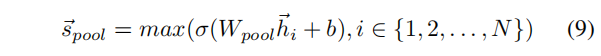
其中,
m
a
x
max
max 表示元素级的max运算器,
σ
σ
σ为非线性激活函数。
(3)Set2vec encoder function
Set2vec基于LSTM架构,因为原始的Set2vec工作于有序节点序列。然而,我们需要汇总来自每个节点的综合信息,而不仅仅是图结构。因此,我们将LSTMs应用于无序集合上节点邻居的随机排列。
4.4 HDGI的学习
4.4.1 基于互信息的discriminator
直接计算随机变量之间的互信息并不方便。Belghazi等人证明了
K
L
KL
KL散度符合 Donsker-Varadhan 表示,并且
f
f
f散度表示是其对偶表示。对偶表示提供了随机变量
X
X
X和
Y
Y
Y的互信息的下界:
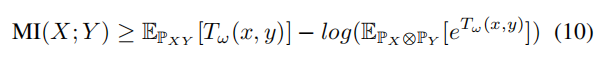
其中,
P
X
Y
\mathbb{P}_{XY}
PXY是联合分布,
P
X
⊗
P
Y
\mathbb{P}_X⊗\mathbb{P}_Y
PX⊗PY是边缘分布的乘积。
T
ω
T_ω
Tω是基于参数
ω
ω
ω的discriminator的深度神经网络。公式(10)中的期望可以使用来自
P
X
Y
\mathbb{P}_{XY}
PXY和
P
X
⊗
P
Y
\mathbb{P}_X⊗\mathbb{P}_Y
PX⊗PY的样本来估计。该discriminator的表达能力保证了高精度的近似MI。
通过训练discriminator D \mathcal{D} D,我们估计并最大化了互信息,从而辨别出正样本集 P o s = { [ h ⃗ n , s ⃗ ] } n = 1 N Pos=\Big\{[\vec{h}_n,\vec{s}]\Big\}^N_{n=1} Pos={[hn,s]}n=1N和负样本集 N e g = { [ h ~ ⃗ m , s ⃗ ] } m = 1 M Neg=\Big\{[\vec{\widetilde{h}}_m,\vec{s}]\Big\}^M_{m=1} Neg={[h m,s]}m=1M。
当节点 h ⃗ i \vec{h}_i hi属于原图(联合分布)时,样本 ( h ⃗ i , s ⃗ ) (\vec{h}_i,\vec{s}) (hi,s)表示为正;而当节点 h ~ ⃗ i \vec{\widetilde{h}}_i h i是生成的假图(边缘分布的乘积)时, ( h ~ ⃗ i , s ⃗ ) (\vec{\widetilde{h}}_i,\vec{s}) (h i,s)为负。
discriminator
D
\mathcal{D}
D 是一个双线性层:
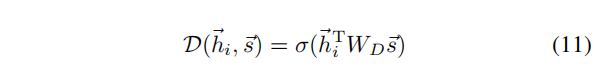
其中,
W
D
W_D
WD是一个可学习的矩阵,
σ
σ
σ是sigmoid激活函数。
使用针对discriminator
D
\mathcal{D}
D 的二元交叉熵损失,最大化互信息:
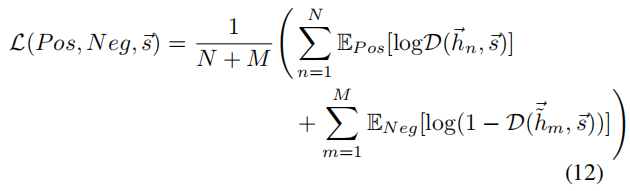
4.4.2 负样本生成器
负样本集 { [ h ~ ⃗ m , s ⃗ ] } m = 1 M \Big\{[\vec{\widetilde{h}}_m,\vec{s}]\Big\}^M_{m=1} {[h m,s]}m=1M由异质图中不存在的样本组成。由于我们的目标是最大限度地提高正节点和图级summary vector之间的互信息,生成的负样本将影响模型捕获的结构信息。这样,我们就需要高质量的负样本来保持结构信息的准确性。
负样本生成器如下:
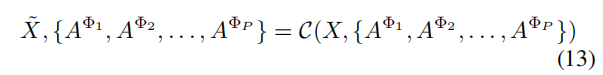
负样本生成器保持所有的基于元路径的邻接矩阵不变,但打乱了初始节点特征矩阵
X
X
X的行,图的结构并没有变,但是每个节点对应的初始的特征向量变了。如图3所示。

5 实验


















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









