










摘要
由于计算和内存成本有限,现有的包含完整图数据的图神经网络无法扩展。因此,在大规模图数据中捕获丰富的信息仍然是一个巨大的挑战。对于无监督的网络嵌入方法,它们过分强调了节点的接近性,其学习到的表示几乎不能直接应用于下游的应用程序任务。近年来,新兴的自我监督学习为解决上述问题提供了一个潜在的解决方案。然而,现有的自监督工作也适用于完整的图数据,在定义基于互信息的损失项时,它偏向于适应全局或非常局部的(1跳邻域)图结构。
本文提出了一种新的基于子图对比度的自监督表示学习方法,即SUBG-CON,利用中心节点与其采样子图之间的强相关性来获取区域结构信息。SUBG-CON不是学习完整的输入图数据,而是使用一种新的数据增强策略,通过基于从原始图中采样的子图定义的对比损失来学习节点表示。
与现有的图表示学习方法相比,SUBG-CON在监督需求较弱、模型学习可扩展性和并行化方面具有显著的性能优势。在来自不同领域的多个真实世界的大规模基准数据集上,与经典的和最先进的图表示学习方法相比,大量的实验验证了我们的工作的有效性和有效性。
1 引言

直观地说,节点和它们的区域邻居更相关,而其他非常远的节点几乎不影响它们,特别是在大规模图中。因此,由区域邻居组成的子图在为节点表示学习提供结构上下文方面起着关键作用。
SUBG-CON考虑了中心节点与其区域子图(包括直接邻居和其他更远的节点)之间的强相关性,如图1所示。
更具体地说,我们首先引入了一种基于子图采样的图数据增强策略。将中心节点及其密切相关的周围节点从原始图中采样,组成上下文子图。然后,将这些子图输入GNN编码器,获得中心节点的表示,池化后得到子图的表示。最后,在潜在空间中引入对比损失,训练编码器区分生成的正样本和负样本(稍后引入),以便充分区分具有不同区域结构的节点。
与之前在完整的图结构上运行的方法相比,SUBG-CON可以在较低的时间和空间成本下,以较小的大小和较简单的结构捕获上下文子图中的区域信息。此外,基于采样的子图实例,SUBG-CON易于并行化,这对于大型图数据至关重要。
2 方法
2.1 基于子图的自监督表示学习
G = { X , A } \mathcal{G}=\{\pmb{X},\pmb{A}\} G={XXX,AAA}
特征矩阵: X = { x 1 , x 2 , . . . , x N } \pmb{X}=\{\pmb{x}_1,\pmb{x}_2,...,\pmb{x}_N\} XXX={xxx1,xxx2,...,xxxN}, N N N是图中的节点数, x i ∈ R F \pmb{x}_i∈\mathbb{R}^F xxxi∈RF表示节点 i i i的 F F F维特征向量。
邻接矩阵: A ∈ R N × N \pmb{A}∈\mathbb{R}^{N×N} AAA∈RN×N,本文假设图是未加权的。
对于中心节点 i i i,设计了一个子图采样器 S \mathcal{S} S,即数据增强的代理,从原始图中提取其上下文子图 X i ∈ R N ′ × F \pmb{X}_i∈\mathbb{R}^{N'×F} XXXi∈RN′×F。该上下文子图为学习节点 i i i的表示提供了区域结构信息。 X i ∈ R N ′ × F \pmb{X}_i∈\mathbb{R}^{N'×F} XXXi∈RN′×F表示第 i i i个上下文子图中的节点特征。 A i \pmb{A}_i AAAi表示节点 i i i及其相邻节点之间的关系信息。 N ′ N' N′表示上下文子图的大小。目标是学习一个编码器 E : R N ′ × F × R N ′ × N ′ → R N ′ × F ′ \mathcal{E}:\mathbb{R}^{N'×F}×\mathbb{R}^{N'×N'}→\mathbb{R}^{N'×F'} E:RN′×F×RN′×N′→RN′×F′,以获取上下文图中的节点表示。
本文将重点讨论基于子图的自监督学习方法的三个关键点:上下文子图提取、表示的子图编码和模型优化的自监督借口任务。
- 对于上下文子图的提取,子图采样器 S \mathcal{S} S将作为数据增强的代理。它度量邻居的重要性分数,并采样几个密切相关的节点,以组成一个上下文子图,为表示学习提供区域结构信息。
- 对于子图的编码,我们的目标是通过编码器 E \mathcal{E} E对上下文子图的结构和特征进行编码,以生成中心节点表示 h i \pmb{h}_i hhhi。另一个关键的结果是总结以节点 i i i为中心的子图作为子图表示 s i \pmb{s}_i sssi。
- 对于自监督借口任务,可以利用中心节点与其上下文子图之间的强相关性来优化编码器,从而将从上下文子图中捕获的区域信息嵌入到中心节点表示中。
2.2 基于子图采样的数据增强
定义1(图上的数据增强): 给定一个图 G = { X , A } \mathcal{G}=\{\pmb{X},\pmb{A}\} G={XXX,AAA},数据增强是一种利用在 G \mathcal{G} G的特征和关系上的各种变换来生成一系列变体图 G ′ = { X ′ , A ′ } \mathcal{G}'=\{\pmb{X}',\pmb{A}'\} G′={XXX′,AAA′}的策略。
本文采用了一种基于子图采样的数据增强策略。因为从直观上看,节点和它们的区域邻域的相关性更高,而远程节点几乎不影响它们。随着图的大小的增加,这种假设更加合理。因此,我们从原始图中采样一系列包含区域邻居的子图作为训练数据。
考虑到不同邻居的重要性不同,对于特定的节点
i
i
i,子图采样器
S
\mathcal{S}
S首先通过个性化pagerank算法测量邻居节点的重要性得分。
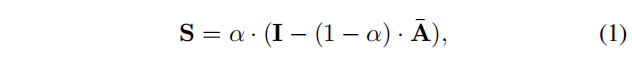
其中,
I
I
I是单位矩阵,
α
∈
[
0
,
1
]
α∈[0,1]
α∈[0,1]是一个参数,总是设置为0.15。
D
(
i
,
i
)
=
∑
j
A
(
i
,
j
)
\pmb{D}(i,i)=\sum_j\pmb{A}(i,j)
DDD(i,i)=∑jAAA(i,j)为对角矩阵,
A
‾
=
A
D
−
1
\overline{\pmb{A}}=\pmb{A}\pmb{D}^{-1}
AAA=AAADDD−1。
S
(
i
,
:
)
\pmb{S}(i,:)
SSS(i,:)是节点
i
i
i的重要性得分向量,表示其与其他节点的相关性。
对于特定的节点
i
i
i,子图采样器
S
\mathcal{S}
S选择前
k
k
k个重要邻居用得分矩阵
S
\pmb{S}
SSS构成子图。所选节点的索引可以表示为:
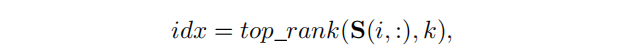
其中,
t
o
p
_
r
a
n
k
top\_rank
top_rank是返回前
k
k
k个值的索引的函数,
k
k
k表示上下文子图的大小。
子图采样器
S
\mathcal{S}
S将使用节点索引对原始图进行处理,得到节点
i
i
i的上下文子图
G
i
\mathcal{G}_i
Gi。其特征矩阵
X
i
\pmb{X}_i
XXXi和邻接矩阵
A
i
\pmb{A}_i
AAAi如下:
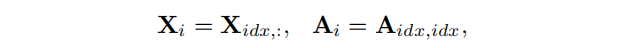
到目前为止,我们可以获得任何特定节点
i
i
i的上下文子图
G
i
=
(
X
i
,
A
i
)
∼
S
(
X
,
A
)
\mathcal{G}_i=(\pmb{X}_i,\pmb{A}_i)∼\mathcal{S}(\pmb{X},\pmb{A})
Gi=(XXXi,AAAi)∼S(XXX,AAA)。对于大型输入图,该过程可以支持并行计算,以进一步提高效率。这些通过数据增强产生的上下文子图可以分解成几个小批次,并输入以训练SUBG-CON。
2.3 编码子图
给定中心节点
i
i
i的上下文子图
G
i
=
(
X
i
,
A
i
)
\mathcal{G}_i=(\pmb{X}_i,\pmb{A}_i)
Gi=(XXXi,AAAi),编码器
E
:
R
N
′
×
F
×
R
N
′
×
N
′
→
R
N
′
×
F
′
\mathcal{E}:\mathbb{R}^{N'×F}×\mathbb{R}^{N'×N'}→\mathbb{R}^{N'×F'}
E:RN′×F×RN′×N′→RN′×F′对其进行编码,得到潜在表示矩阵
H
i
\pmb{H}_i
HHHi:
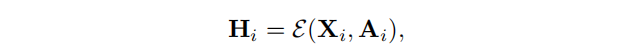
在这里,我们采用GNN作为编码器。节点表示是通过聚合来自邻居的信息来生成的。中心节点嵌入
h
i
\pmb{h}_i
hhhi是从潜在表示矩阵
H
i
\pmb{H}_i
HHHi中选择的:
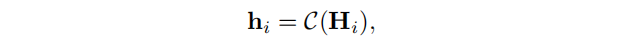
其中,
C
\mathcal{C}
C表示选择中心节点嵌入的操作。
为了得到子图级的总结向量,我们利用读出函数
R
:
R
N
′
×
F
′
→
R
F
′
\mathcal{R}:\mathbb{R}^{N'×F'}→\mathbb{R}^{F'}
R:RN′×F′→RF′,使用它将获得的节点表示汇总为子图级表示
s
i
\pmb{s}_i
sssi:
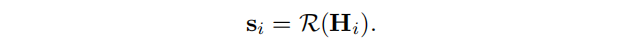
2.4 通过中心节点和上下文子图进行的对比学习
SUBG-CON的体系结构如图2所示。

对于捕获上下文子图中的区域信息的节点表示
h
i
\pmb{h}_i
hhhi,我们将上下文子图表示
s
i
\pmb{s}_i
sssi视为正样本。另一方面,对于一组子图表示,我们使用一个函数
P
\mathcal{P}
P来破坏它们以生成负样本,记为:
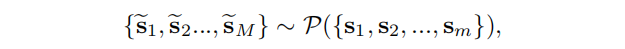
损失表示为:
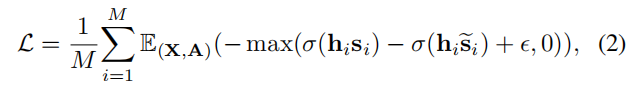
其中,
σ
(
x
)
=
1
/
(
1
+
e
x
p
(
−
x
)
)
\sigma(x)=1/(1+exp(-x))
σ(x)=1/(1+exp(−x))是sigmoid函数,
ϵ
\epsilon
ϵ是 margin value 。
我们在算法1中总结了我们的方法的程序步骤。

2.5 并行化
一方面,子图的提取易于并行化。几个随机的工作人员(在不同的线程、进程或机器中)可以同时探索同一图的不同部分,以提取上下文子图。另一方面,如果不需要需要整个图结构的全局计算,就可以同步对多个子图进行编码,以获得中心节点和子图的表示。
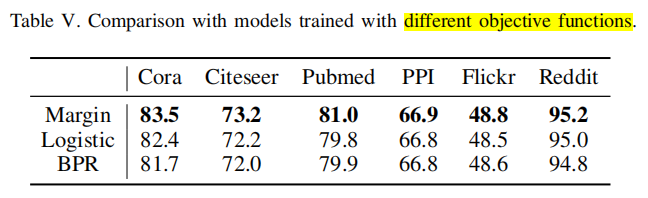
3 实验


















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









