






CNN+LSTM+Attention是一种深度学习模型,它结合了卷积神经网络(CNN)、长短期记忆网络(LSTM)和注意力机制(Attention)的优势,用于处理序列数据和时间序列预测任务。这种模型因其强大的特征提取和序列建模能力,被广泛应用于各种时空数据的预测和分析任务
今天就这两种技术整理出了论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
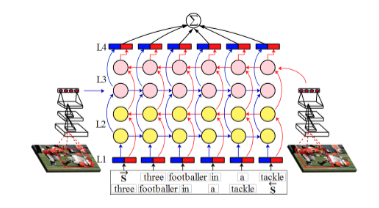
Image Captioning with Deep Bidirectional LSTMs
使用深度双向LSTM的图像描述
方法:
-
深度卷积神经网络(CNN):构建在深度CNN之上,用于提取图像特征。
-
两个独立的长短期记忆网络(LSTM):一个用于编码图像特征,另一个用于编码句子特征。
-
深度双向LSTM(Bi-LSTM)模型:利用历史和未来上下文信息在高级语义空间中学习长期视觉-语言交互。
-
数据增强技术:如多裁剪、多尺度和垂直镜像,用于防止在训练深度模型时过拟合。
创新点:
-
深度双向LSTM模型:提出了两种新型的深度双向变体模型,通过不同方式增加非线性转换的深度,以学习层次化的视觉-语言嵌入,这在图像描述生成和图像-句子检索任务中取得了竞争性的性能,即使没有集成额外机制(例如目标检测、注意力模型等)。
-
数据增强技术:提出了新的数据增强技术,如多裁剪、多尺度和垂直镜像,这些技术可以增加图像-句子训练对的数量,从而有效缓解过拟合问题,使训练对数量增加约40倍。
-
性能提升:在三个基准数据集(Flickr8K、Flickr30K和MSCOCO)上的评估表明,双向LSTM模型在图像描述生成任务上达到了与最新技术相当的表现,并且在检索任务上显著优于最近的方法。
论文2
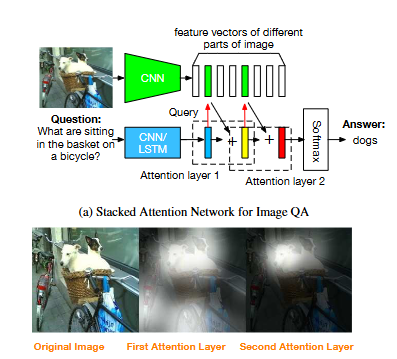
Stacked Attention Networks for Image Question Answering
用于图像问题回答的堆叠注意力网络
方法:
-
语义表示:使用问题的语义表示作为查询,搜索与答案相关的图像区域。
-
多层SAN:开发了一个多层SAN,通过多次查询图像逐步推断答案。
-
视觉注意力层:通过多步推理定位与问题相关的图像区域,用于答案预测。
创新点:
-
多层注意力机制:提出了一个多层SAN,它通过多次查询图像来逐步定位相关视觉区域并推断答案,这在图像问题回答(QA)中需要多步推理。
-
性能提升:在四个图像QA数据集上的实验表明,所提出的SAN显著优于以前的最先进方法。具体来说,在DAQUAR-ALL数据集上,两层SAN(2, CNN)模型比其他最佳基线模型(如IMG-CNN和Ask-Your-Neurons)在准确率上分别提高了5.9%和7.6%。
-
可视化分析:通过可视化SAN的不同注意力层的输出,展示了SAN如何采取多步骤逐步集中注意力在相关视觉线索上的过程,这有助于理解模型是如何工作的,并证明了多步推理的有效性。
论文3
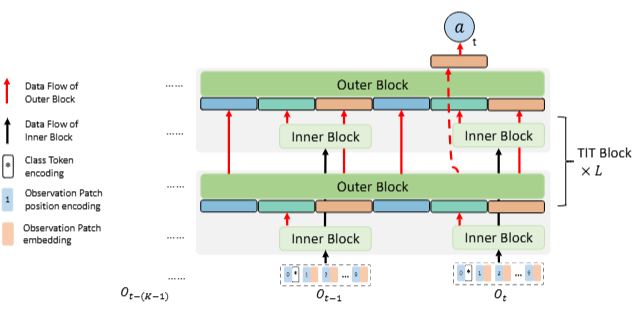
Transformer in Transformer as Backbone for Deep Reinforcement Learning
作为深度强化学习主干的Transformer内嵌Transformer
方法:
-
纯Transformer基础网络:提出基于纯Transformer的网络设计,用于深度强化学习(Deep RL),旨在提供适用于在线和离线设置的即用型主干网络。
-
内部Transformer:用于处理单个观测,学习包含重要空间信息的观测表示。
-
外部Transformer:负责处理观测历史,捕捉跨多个连续观测的重要时间信息。
-
Transformer内嵌Transformer(TIT)主干:通过级联两个Transformer来提取空间-时间表示,以进行更好的决策。
创新点:
-
纯Transformer主干网络:首次展示了纯Transformer可以作为标准在线和离线RL方法(例如PPO和CQL)的主干,只要正确设计主干网络。这类似于ViT证明了基于纯Transformer的网络可以很好地执行计算机视觉任务。
-
TIT主干网络:提出了两种TIT主干网络,实验表明最佳模型不仅在在线和离线RL设置中,而且在最近提出的决策Transformer的监督学习范式中,都达到了与几个强基线相当的或更好的性能。
-
性能提升:在Flickr8K数据集上,Bi-LSTM模型在BLEU-N评估中达到了61.9/43.3/29.7/20.0的成绩,而使用VggNet的Bi-LSTM模型在MSCOCO数据集上达到了67.2/49.2/35.2/24.4的成绩,显示出显著的性能提升。
-
多角度分析:通过从多个方面分析主干网络,提供了对所提方法的深入理解。
论文4
Translating Math Formula Images to LaTeX Sequences Using Deep Neural Networks with Sequence-level Training
使用具有序列级训练的深度神经网络将数学公式图像翻译成LaTeX序列
方法:
-
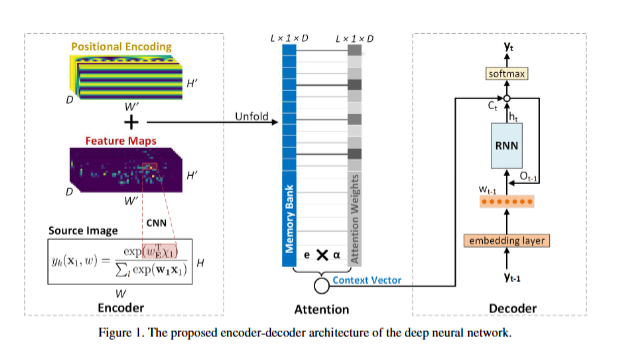
编码器-解码器架构:提出了一个深度神经网络模型,该模型使用编码器-解码器架构将数学公式图像翻译成LaTeX标记序列。
-
卷积神经网络(CNN):作为编码器,将图像转换为一组特征图。
-
2D位置编码:为了更好地捕捉数学符号的空间关系,特征图通过2D位置编码增强,然后展开成向量。
-
堆叠双向长短期记忆(LSTM)模型:作为解码器,集成了软注意力机制,作为语言模型将编码器输出翻译成LaTeX标记序列。
创新点:
-
2D位置编码:提出了一种新的2D位置编码技术,以丰富表示空间局部性信息,帮助模型更好地区分数学符号的二维空间关系。
-
序列级训练目标:提出了基于BLEU分数的序列级训练目标函数,这可以更好地捕捉LaTeX序列中不同标记之间的相互关系。
-
消除暴露偏差问题:通过在序列级训练期间关闭解码器中的反馈回路,即在每个时间步骤中输入预测的标记而不是真实的标记,从而消除了暴露偏差问题。
-
性能提升:在IM2LATEX-100K数据集上训练和评估模型,显示出在基于序列和基于图像的评估指标上都达到了最先进的性能,例如BLEU分数达到了90.28%,图像编辑距离达到了92.28%。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









