






在深度学习领域,损失函数和注意力机制的结合已经成为一种重要的研究方向。这种结合能够显著提升模型的性能和泛化能力,帮助模型更精确地捕捉数据中的关键信息,同时减少不必要的计算消耗
今天就损失函数+注意力机制整理出了论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
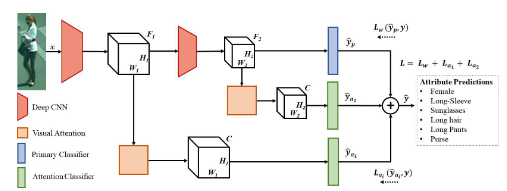
Deep Imbalanced Attribute Classification using Visual Attention Aggregation
基于视觉注意力聚合的深度不平衡属性分类
方法:
-
多尺度视觉注意力机制:在不同尺度上提取视觉注意力掩码,通过聚合不同阶段的注意力信息来增强特征表示。
-
加权焦点损失函数:提出一种加权焦点损失函数,用于处理类别不平衡问题,同时关注难以分类的样本。
-
注意力损失函数:引入注意力损失函数,惩罚具有高预测方差的注意力掩码,以稳定训练过程。
-
特征提取与聚合:使用预训练网络进行特征提取,并在多个尺度上聚合视觉注意力掩码,以提高分类性能。
创新点:
-
多尺度注意力机制:通过在多个尺度上提取注意力掩码并聚合信息,模型能够学习更具判别力的特征表示,从而提升分类性能。
-
加权焦点损失函数:与传统的二元交叉熵损失相比,加权焦点损失函数能够更好地处理类别不平衡问题,同时关注难以分类的样本,从而提高模型的准确率。
-
注意力损失函数:通过惩罚具有高预测方差的注意力掩码,有效解决了注意力机制在弱监督条件下的不稳定性问题,进一步提升了模型的性能。
-
性能提升:在WIDER-Attribute数据集上,该方法的平均精度(mAP)达到了86.4%,比之前的最佳方法提高了1.3个百分点;在PETA数据集上,F1分数达到了86.46%,比之前的最佳方法提高了1.7个百分点。
论文2
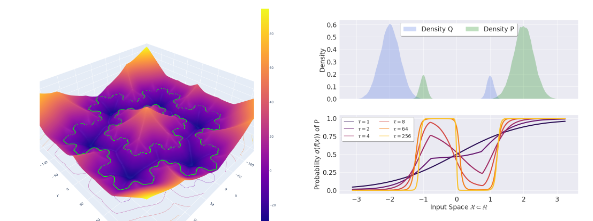
Pay attention to your loss: understanding misconceptions about 1-Lipschitz neural networks
关注你的损失函数:理解关于1-Lipschitz神经网络的误解
方法:
-
1-Lipschitz网络构建:通过限制网络的Lipschitz常数为1,构建具有鲁棒性保证的神经网络。
-
损失函数调整:通过调整损失函数的超参数(如温度参数τ),控制网络的准确性和鲁棒性权衡。
-
泛化能力分析:证明1-Lipschitz网络在训练集规模增加时,训练损失会收敛到测试损失,从而具有更好的泛化能力。
-
PAC学习理论:利用PAC学习理论,为1-Lipschitz网络提供样本复杂度的界限,确保在大样本情况下不会过拟合。
创新点:
-
鲁棒性与准确性统一:证明1-Lipschitz网络在保持高准确性的同时,能够提供鲁棒性半径证书,解决了以往认为鲁棒性与准确性相互矛盾的观点。
-
损失函数的关键作用:揭示了损失函数的超参数(如温度参数τ)在控制网络准确性和鲁棒性权衡中的关键作用,为网络训练提供了新的视角。
-
泛化能力提升:与无约束网络相比,1-Lipschitz网络在训练集规模增加时,训练损失能够更好地逼近测试损失,从而具有更强的泛化能力。
-
性能提升:在CIFAR-10数据集上,通过调整损失函数的超参数,1-Lipschitz网络能够达到与无约束网络相当的准确率,同时具有更高的鲁棒性。
-
PAC学习理论应用:为1-Lipschitz网络提供了PAC学习理论支持,证明了在适当选择边际参数m的情况下,网络的VC维度是有限的,从而确保了网络在大样本情况下的学习能力。
论文3
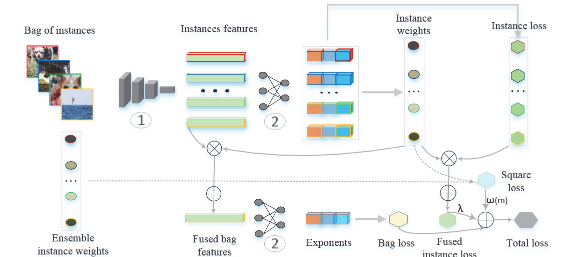
Loss-Based Attention for Deep Multiple Instance Learning
基于损失函数的深度多实例学习注意
方法:
-
损失函数引导的注意力机制:提出了一种基于损失函数的注意力机制,通过计算实例权重来同时学习实例预测和包预测。
-
实例权重计算:基于softmax和交叉熵损失函数计算实例权重,并与全连接层共享参数,以同时学习实例和包的预测。
-
正则化项引入:引入一个由学习到的实例权重和交叉熵函数组成的正则化项,以增强实例权重与损失之间的联系。
-
一致性代价:引入一致性代价来平滑神经网络的训练过程,提升模型的泛化性能。
创新点:
-
性能提升:在多个基准数据库上,所提方法在包分类和图像分类任务上优于现有的最先进的多实例学习(MIL)方法。例如,在MUSK1数据集上,分类准确率达到了91.7%,比之前的最佳方法提高了约2.8个百分点。
-
实例权重与损失的直接联系:首次直接将注意力机制与损失函数连接起来,用于多实例学习,使得实例权重的计算更加直接和有效。
-
提升实例召回率:通过引入正则化项,显著提升了实例的召回率。实验结果表明,与仅使用softmax和交叉熵函数的注意力机制相比,所提方法能够更好地识别出与包标签一致的实例。
-
平滑训练过程:一致性代价的引入有效平滑了训练过程,使得模型在训练过程中更加稳定,从而提高了模型的泛化能力。
论文4
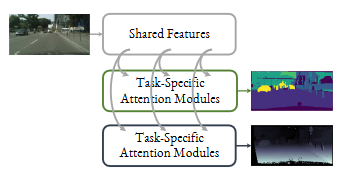
End-to-End Multi-Task Learning with Attention
端到端多任务学习中的注意力机制
方法:
-
多任务注意力网络(MTAN):提出了一个多任务学习架构,包含一个共享网络和每个任务的软注意力模块,允许从全局特征池中学习任务特定的特征。
-
任务特定注意力模块:通过在共享网络的每一层应用软注意力掩码,自动确定共享特征对各自任务的重要性,从而学习任务共享和任务特定的特征。
-
动态权重平均(DWA):提出了一种新的权重方案,通过考虑每个任务损失的变化率来动态调整任务权重,简化了多任务学习中权重调整的复杂性。
-
端到端训练:整个架构可以基于任何前馈神经网络构建,并且可以端到端地训练,简单高效。
创新点:
-
性能提升:在多个数据集上的实验表明,MTAN在多任务学习中达到了最先进的性能。例如,在NYUv2数据集上,与Cross-Stitch网络相比,MTAN在语义分割任务上的mIoU(平均交并比)提升了约3.2个百分点,在深度估计任务上的绝对误差降低了约0.014。
-
参数效率:MTAN通过共享全局特征池和注意力掩码自动学习特征共享,相比其他多任务学习方法,参数数量显著减少,例如在SegNet基础上实现MTAN时,参数增加量不到10%。
-
对权重方案的鲁棒性:MTAN对多任务损失函数中的权重方案具有更高的鲁棒性,避免了繁琐的权重调整过程。实验表明,MTAN在不同的权重方案下都能保持相似的学习趋势。
-
任务特定特征学习:通过注意力模块,MTAN能够为每个任务学习特定的特征,使得模型在处理复杂任务时更加灵活和高效。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









