






域自适应(Domain Adaptation,DA)是迁移学习中的一个重要方法,旨在解决源域(Source Domain)和目标域(Target Domain)之间数据分布差异的问题。其核心思想是将源域上学习到的知识迁移到目标域中,以提升模型在目标域的性能
我还整理出了相关的论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
标题:
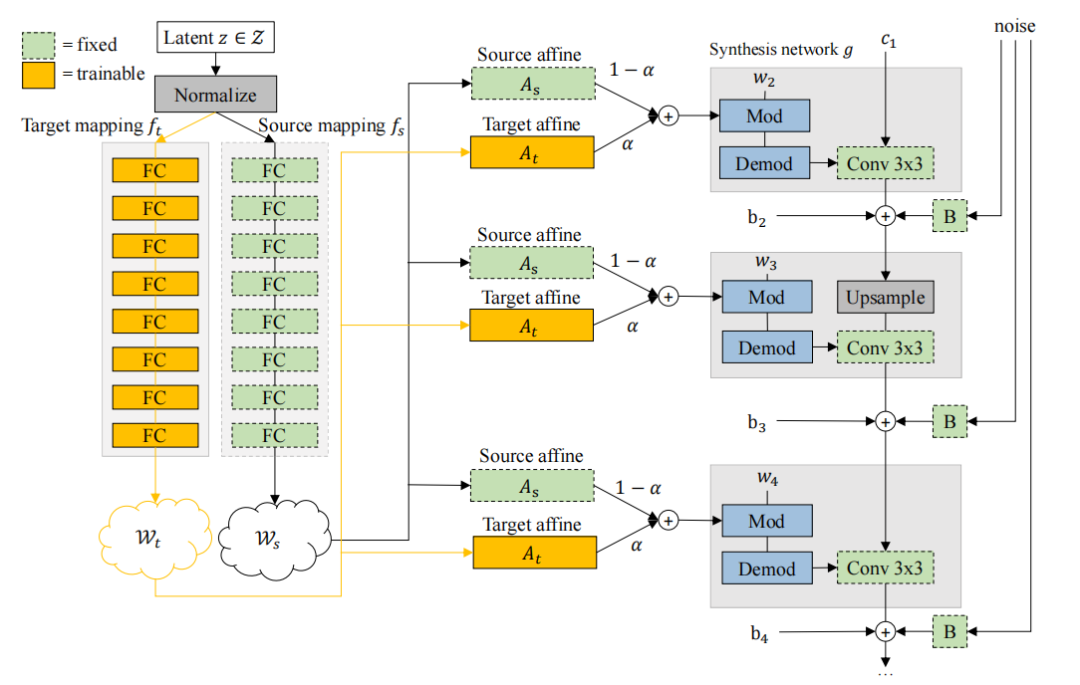
Domain Re-Modulation for Few-Shot Generative Domain Adaptation
用于少样本生成性领域适应的领域重调制
方法:
-
领域重调制(DoRM)结构:提出了一种基于StyleGAN2的新型生成器结构,通过冻结预训练的源生成器并引入新的映射和仿射模块(M&A模块),在风格空间中实现目标领域的属性捕获。
-
线性可组合的领域偏移:通过引入多个M&A模块,生成器能够在训练数据中不存在的混合领域中生成图像,同时保持跨领域的一致性。
创新点:
-
多领域和混合领域生成:DoRM能够通过激活不同的M&A模块实现多领域生成,并通过组合多个M&A模块生成混合领域图像。例如,在混合领域“Sketch-Baby”中,DoRM能够无缝融合领域特定属性,而CDC方法的生成质量较差。
-
相似性结构损失(Lss):通过对齐源图像和目标图像的自相关图,进一步增强了跨领域一致性。在10-shot GDA中,引入Lss后,Identity相似性从CDC的0.326提高到0.445,表明更好的跨领域一致性。
-
存储效率:与CDC方法相比,DoRM在多领域生成中显著减少了存储需求。例如,在10领域生成中,CDC需要240M参数,而DoRM仅需84M参数。
论文2
标题:
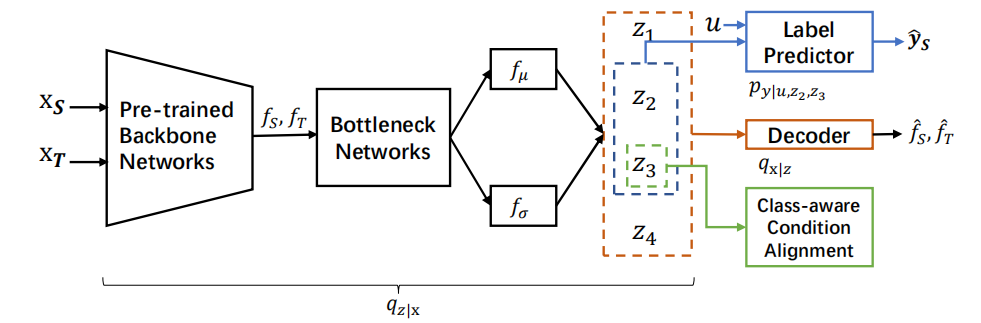
Subspace Identification for Multi-Source Domain Adaptation
多源领域适应的子空间识别
方法:
-
子空间识别理论:提出了一种新的子空间识别理论,通过更少的辅助变量(n+1个领域)实现领域不变和领域特定变量的解耦。
-
数据生成过程:设计了一个更通用的数据生成过程,考虑了目标偏移,并将潜在变量分为四类:领域特定且与标签无关、领域特定且与标签相关、领域不变且与标签相关、领域不变且与标签无关。
创新点:
-
类感知条件对齐:通过预测不确定性对每个类别进行加权,提高了目标偏移场景下的性能。在Office-Home数据集上,SIG方法的平均准确率比WADN高出1.3%-4%,表明类感知对齐能够有效缓解目标偏移的影响。
-
通用数据生成过程:引入了领域特定但与标签相关的潜在变量和领域不变但与标签无关的潜在变量,更贴近现实世界的数据分布。例如,在DomainNet数据集上,SIG方法的平均准确率比iMSDA高出3.3%,表明SIG在复杂领域偏移场景下的优越性。
-
性能提升:SIG模型在多个基准数据集上显著优于现有方法。例如,在PACS数据集的“Cartoon”任务中,SIG的准确率比iMSDA高出0.7%,在DomainNet数据集上平均准确率比iMSDA高出5.4%。
论文3
标题:
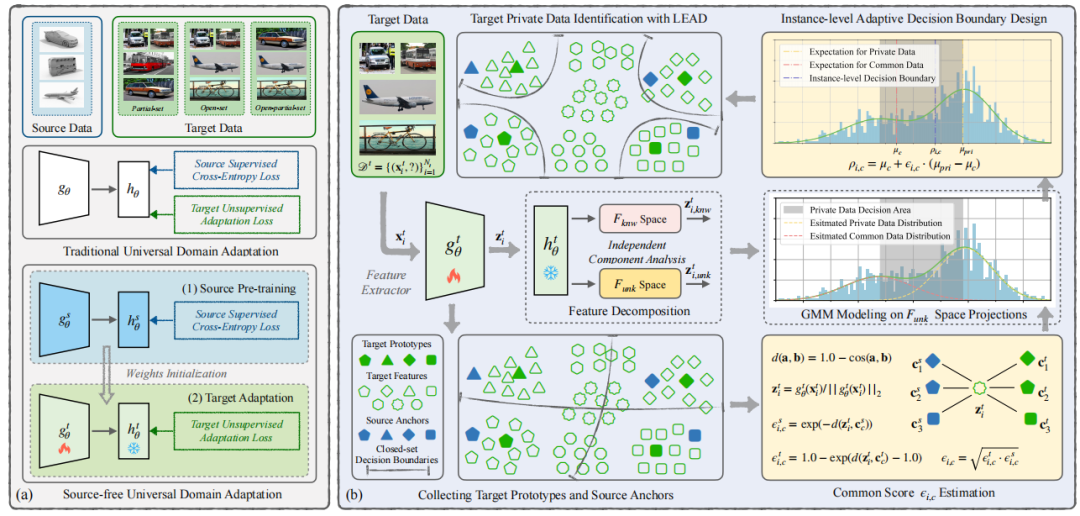
LEAD: Learning Decomposition for Source-free Universal Domain Adaptation
LEAD:用于无源数据的通用领域适应的学习分解方法
方法:
-
特征分解:通过正交分解将特征空间划分为源已知空间和源未知空间,以识别目标私有数据。
-
实例级决策边界:基于目标原型和源锚点的距离,建立实例级决策边界,用于自适应识别目标私有数据
创新点:
-
特征分解:通过正交分解将特征空间划分为源已知和未知部分,为识别目标私有数据提供了新的视角。这一方法在VisDA数据集的OPDA场景中,将H-score从GLC的73.1%提升至76.6%,提升了3.5%。
-
实例级决策边界:与基于全局阈值的方法相比,LEAD通过实例级决策边界显著提高了目标私有数据的识别精度。在Office-Home数据集的OPDA场景中,与GLC相比,LEAD将H-score从75.6%提升至76.2%,时间消耗减少了75%。
-
无源数据适应性:LEAD在无需源数据的情况下实现通用领域适应,符合数据保护政策的要求。在DomainNet数据集上,LEAD将平均准确率从UMAD的70.1%提升至78.0%,提升了7.9%。
论文4
标题:
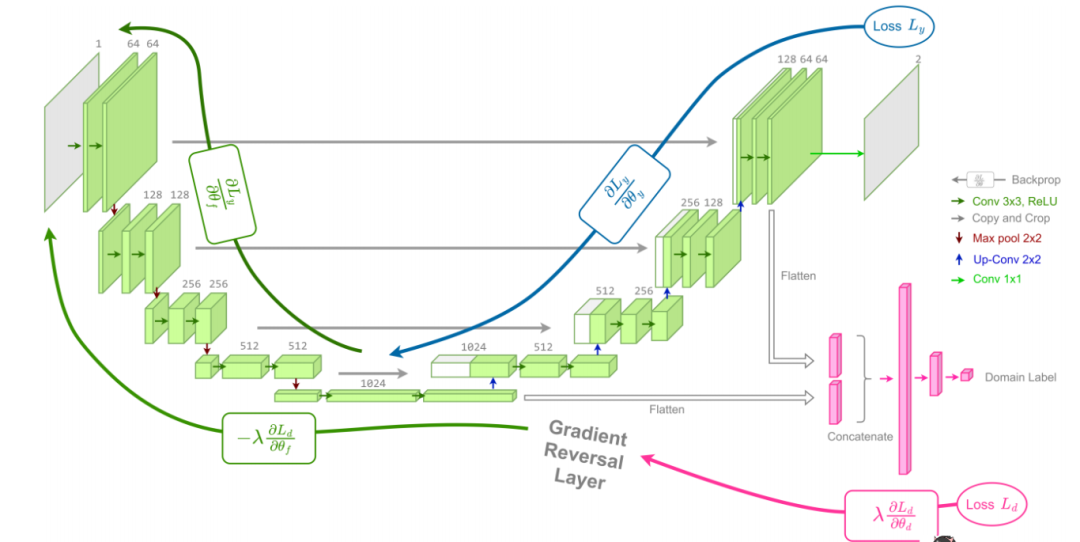
Unsupervised Domain Adaptation of MRI Skull-stripping Trained on Adult Data to Newborns
无监督领域适应:将基于成人数据训练的MRI颅骨剥离模型应用于新生儿
方法:
-
对比度反转:通过反转成人脑MRI中的灰白质对比度,减少成人和新生儿数据之间的领域偏移。
-
领域对抗训练:基于3D U-Net架构,引入领域对抗训练,使模型学习领域不变特征。
-
动态λ调整:在训练过程中动态调整λ值,优先优化分割性能,随后逐步引入领域适应。
创新点:
-
对比度反转:通过反转成人脑MRI的灰白质对比度,显著减少了成人和新生儿MRI之间的领域偏移。这一方法使得模型在新生儿数据上的Dice系数从0.079提升至0.916,提升了约11倍。
-
领域对抗训练:通过领域对抗训练,使模型能够学习领域不变特征,从而在新生儿数据上实现准确的颅骨剥离。与仅使用对比度反转的方法相比,Dice系数提升了137%。
-
无监督学习:该方法无需新生儿数据的标注信息,显著降低了手动标注的工作量和时间成本。在与有监督模型(如SynthStrip和Hippodeep)的对比中,Dice系数仅低2.7%和0.7%,表现出色。
-
模型鲁棒性:该方法不仅在新生儿数据上表现出色,还在成人数据上保持了较高的分割精度(Dice系数为0.9521),证明了模型的鲁棒性。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









