






在人工智能领域,对比学习(Contrastive Learning)是一种重要的学习范式,通过对比样本之间的相似性和差异性来学习数据的有效表示
我还整理出了相关的论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
标题:
Enzyme function prediction using contrastive learning
利用对比学习进行酶功能预测
方法:
-
对比学习框架(Contrastive Learning Framework):通过学习酶的嵌入空间,使得具有相同EC编号的氨基酸序列在嵌入空间中距离较近,而不同EC编号的序列距离较远。
-
嵌入表示(Embedding Representation):使用语言模型ESM1b生成的蛋白序列嵌入作为输入,通过前馈神经网络生成功能感知的嵌入表示
创新点:
-
对比学习框架:与传统的多标签分类框架相比,对比学习能够更好地处理酶功能编号(EC)的不平衡性,尤其是在训练数据中某些EC编号样本数量极少的情况下。
-
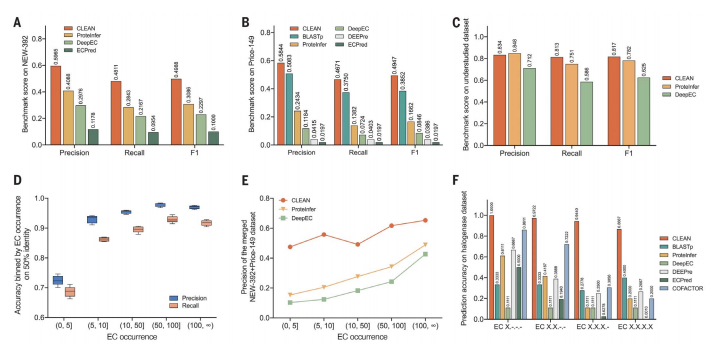
性能提升:在测试集与训练集序列一致性低于50%的情况下,CLEAN的F1分数达到0.865,即使在10%序列一致性聚类下,F1分数仍能达到0.67,显著优于现有方法。
-
对未研究酶的注释能力:CLEAN能够准确注释未被充分研究的酶的功能,且在包含稀有EC编号的验证数据集上,F1分数达到0.817,比现有方法高出约13%。
-
纠正错误标注的酶:在实验验证中,CLEAN成功纠正了被错误标注的酶(如MJ1651和TTHA0338),并准确预测了具有多种功能的酶(如SsFlA)的多个EC编号。
论文2
标题:
TimesURL: Self-Supervised Contrastive Learning for Universal Time Series Representation Learning
TimesURL:用于通用时间序列表示学习的自监督对比学习
方法:
-
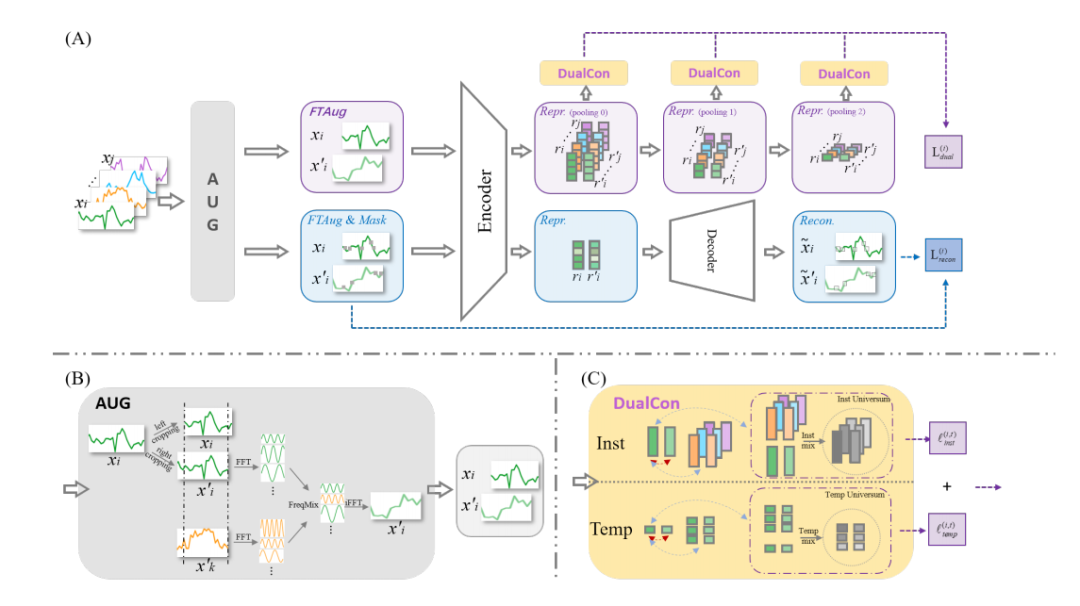
频率-时间增强(FTAug):结合时间域的随机裁剪和频率域的频率混合,生成增强样本对,同时保持时间序列的上下文一致性和时间特性。
-
双重Universum学习(Dual Universum Learning):通过在实例维度和时间维度上混合正样本和负样本,生成高质量的硬负样本对,增强对比学习的效果。
创新点:
-
频率-时间增强(FTAug):通过频率混合和时间裁剪生成增强样本,避免了传统方法对时间序列时间特性的破坏,从而更好地保留了时间序列的语义信息。
-
双重Universum学习:引入双重Universum作为硬负样本,显著提高了对比学习的性能。在代理任务中,模型性能下降了约10%,但在下游任务中,分类准确率从0.896提升到0.985,表明Universum显著增强了模型的泛化能力。
-
性能提升:在多个下游任务中,TimesURL均取得了显著的性能提升。例如,在时间序列分类任务中,平均准确率比之前的最佳方法(InfoTS)提高了3.8%(UEA数据集)和0.7%(UCR数据集)。在时间序列填补任务中,TimesURL在多个数据集上取得了最低的均方误差(MSE)和平均绝对误差(MAE)。
论文3
标题:
Understanding Contrastive Learning via Distributionally Robust Optimization
通过分布鲁棒优化理解对比学习
方法:
-
对比学习(CL)与分布鲁棒优化(DRO)的联系:通过理论分析,将对比学习(CL)视为一种对负样本分布进行分布鲁棒优化(DRO)的过程,揭示了CL在不同潜在分布下的鲁棒性。
-
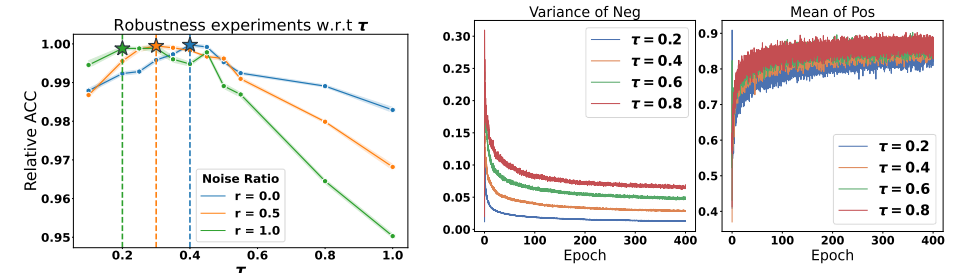
温度参数τ的重新解读:将温度参数τ视为拉格朗日系数,用于调节潜在分布集合的大小,从而控制模型对不同分布的鲁棒性。
创新点:
-
鲁棒性解释:揭示了对比学习对采样偏差的内在容忍性,其本质是通过DRO优化负样本分布,从而在不同潜在分布下表现出鲁棒性。
-
性能提升:通过调整温度参数τ,对比学习能够在不同采样偏差下实现与专门解决采样偏差方法(如DCL和HCL)相当的性能。
-
理论联系:建立了对比学习与互信息(MI)之间的理论联系,证明了InfoNCE损失是MI的一种更紧的估计,为对比学习的理论基础提供了新的解释。
论文4
标题:
VoCo: A Simple-yet-Effective Volume Contrastive Learning Framework for 3D Medical Image Analysis
VoCo:一种用于3D医学图像分析的简单而有效的体积对比学习框架
方法:
-
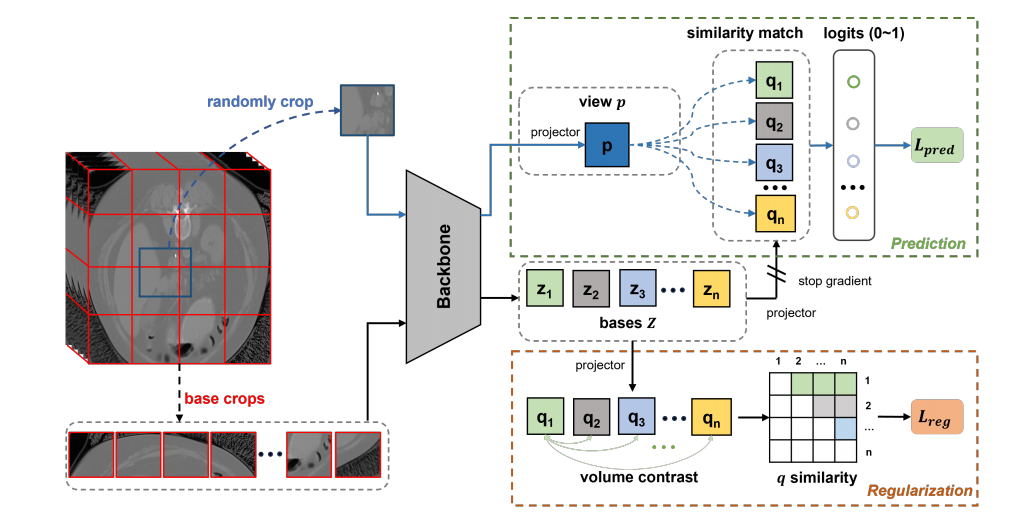
体积对比(VoCo)框架:提出了一种基于体积对比的自监督学习框架,通过预测随机裁剪子体积的上下文位置,将上下文位置先验信息编码到模型表示中。
-
上下文位置预测:通过计算随机裁剪子体积与基体积(base crops)之间的相似性,预测子体积的上下文位置,从而学习一致的语义表示。
创新点:
-
上下文位置先验:利用3D医学图像中不同器官之间相对一致的几何关系,通过上下文位置预测任务将高阶语义信息编码到模型表示中,显著提升了下游任务的性能。
-
性能提升:在BTCV数据集上,VoCo的平均Dice分数达到83.85%,比现有最佳方法(如GL-MAE)高出1.84%;在LiTs数据集上,Dice分数达到96.52%,比从头开始训练的模型高出3.10%。
-
跨模态泛化能力:在BraTS 21数据集(MRI)上验证了VoCo的跨模态泛化能力,Dice分数达到78.53%,优于现有方法。
-
简单高效:VoCo框架简单易实现,无需复杂的在线聚类或更新过程,同时在多个下游任务中表现出色,证明了其在3D医学图像分析中的有效性。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









