






小波卷积(Wavelet Convolution)是一种结合小波变换和卷积操作的技术,主要用于提升卷积神经网络(CNN)的性能。
我还整理出了相关的论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
标题:
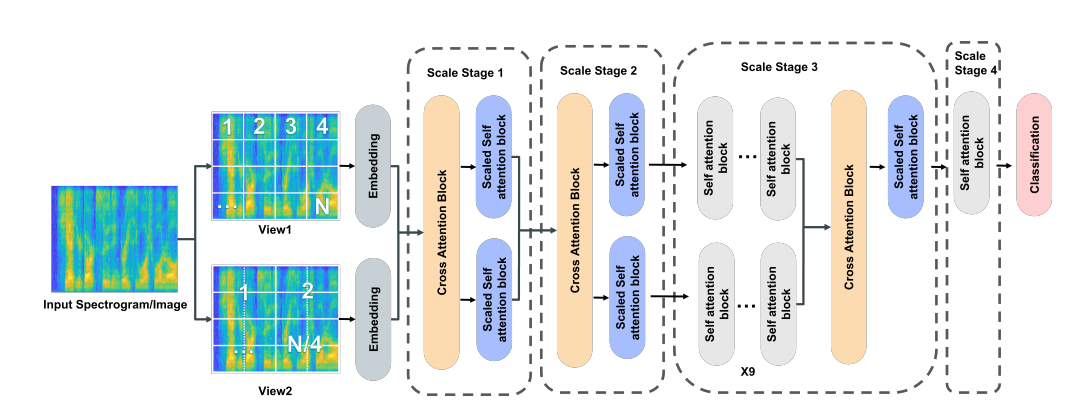
Wavelet Multiresolution Analysis Based Speech Emotion Recognition System Using 1D CNN LSTM Networks
基于小波多分辨率分析和1D CNN-LSTM网络的语音情感识别系统
方法:
-
小波特征提取:利用连续小波变换(CWT)提取语音信号的特征,选择与人类听觉相关的Morlet小波作为母小波,并在80 Hz到2000 Hz的频率范围内提取特征。
-
自编码器降维:使用自编码器对高维小波特征进行降维,减少特征维度的同时保留关键信息。
创新点:
-
小波特征的多分辨率优势:利用小波变换的多分辨率特性,能够同时在时间和频率域内提供良好的局部化,解决了传统FFT方法在时间和频率分辨率上的限制。
-
自编码器降维:通过自编码器对小波特征进行降维,有效解决了高维特征带来的过拟合问题,同时保留了特征的非线性特性。
-
性能提升:在RAVDESS数据集上,该方法实现了81.45%的未加权准确率(UA)和81.22%的加权准确率(WA),优于现有的基于MFCC、梅尔频谱等特征的方法。
-
模型鲁棒性:通过数据增强和自编码器降维,提高了模型对噪声的鲁棒性,使其在真实场景中更具实用性。
论文2
标题:
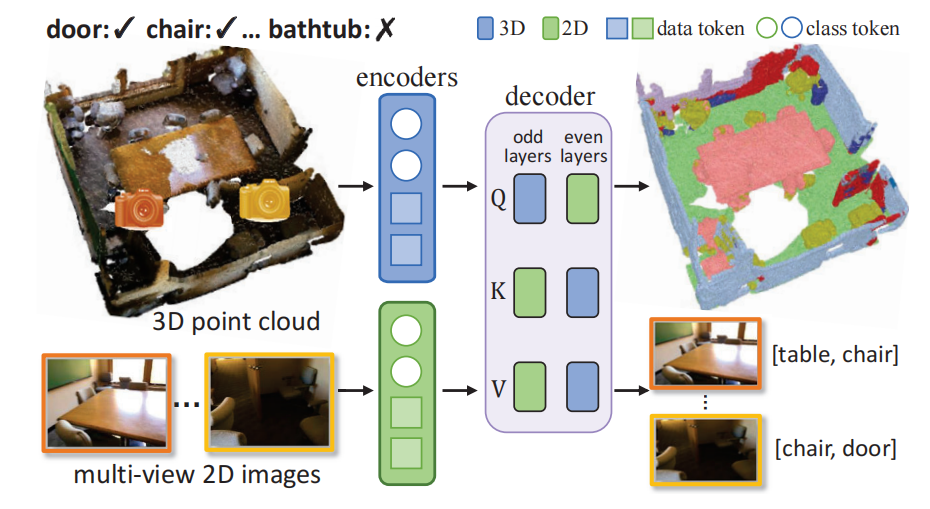
Wavelet-SRNet: A Wavelet-based CNN for Multi-scale Face Super Resolution
Wavelet-SRNet:一种基于小波的多尺度人脸超分辨率CNN
方法:
-
小波包变换(WPT):使用小波包变换将图像分解为一系列小波系数,捕捉图像的全局拓扑信息和局部纹理细节。
-
小波系数预测:通过CNN预测低分辨率图像对应的高分辨率小波系数,而不是直接生成高分辨率图像。
创新点:
-
小波系数预测:首次将单图像超分辨率问题转化为小波系数预测任务,为超分辨率问题提供了新的视角。
-
多尺度超分辨率:能够处理从16×16到128×128等不同分辨率的输入,并支持2×、4×、8×和16×等多种放大倍数。
-
性能提升:在CelebA和Helen数据集上,该方法在PSNR和SSIM指标上均优于现有的超分辨率方法,例如在16×16输入、8×放大倍数的情况下,PSNR达到26.61 dB,SSIM达到0.8949。
-
鲁棒性:对未知高斯模糊、姿态变化和遮挡具有一定的鲁棒性,能够生成高质量的人脸超分辨率图像。
论文3
标题:
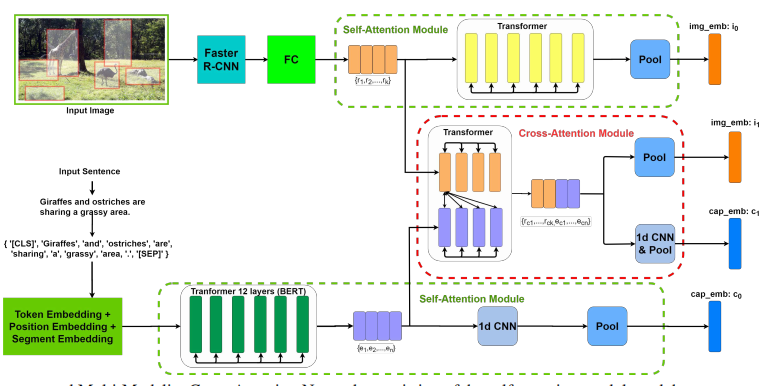
Recognition of Muscle Fatigue Status Based on Improved Wavelet Threshold and CNN-SVM
基于改进小波阈值和CNN-SVM的肌肉疲劳状态识别
方法:
-
改进的小波阈值去噪方法:提出了一种改进的小波阈值方法,用于去除表面肌电(sEMG)信号中的噪声,同时保留信号细节。
-
特征提取:从去噪后的sEMG信号中提取时域和频域特征,包括均方根(RMS)、积分肌电图(IEMG)、中值频率(MF)、平均功率频率(MPF)和带谱熵(BSE)。
创新点:
-
改进的小波阈值方法:提出的改进小波阈值方法在去噪效果上优于传统方法,信噪比(SNR)更高,均方根误差(RMSE)更小。
-
CNN-SVM分类性能提升:CNN-SVM模型在肌肉疲劳状态分类中表现出色,分类准确率比SVM、PSO-SVM和CNN分别提高了7.48%、7.33%和7.01%。
-
特征融合:通过结合传统时频域特征和带谱熵(BSE),进一步提高了肌肉疲劳分类的准确性。
-
鲁棒性提升:改进的小波阈值方法提高了分类算法对不同去噪算法的鲁棒性,平均准确率比半阈值算法提高了8.36%–11.35%,比新阈值算法提高了1.75%–5.51%。
论文4
标题:
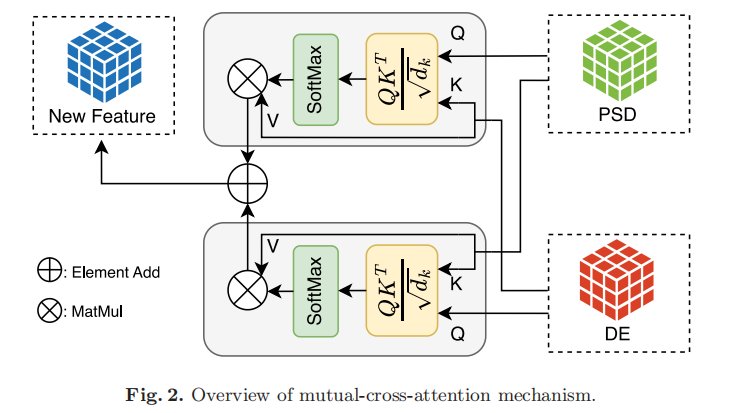
Wavelet Convolutions for Large Receptive Fields
用于大感受野的小波卷积
方法:
-
小波卷积(WTConv):提出了一种基于小波变换(WT)的卷积层WTConv,通过级联小波分解和小卷积核实现大感受野。
-
多频率响应:WTConv通过在不同频率带上进行卷积,实现对输入信号的多频率响应,特别强调低频成分。
创新点:
-
性能提升:在图像分类任务中,WTConvNeXt-T模型的Top-1准确率比ConvNeXt-T提高了0.7%,同时参数数量仅增加了约3%。
-
鲁棒性增强:WTConv增强了CNN对图像干扰的鲁棒性,在ImageNet-C等基准测试中,WTConvNeXt模型的平均干扰误差比ConvNeXt降低了约1.5%。
-
形状偏差提升:WTConv使网络更倾向于基于形状而非纹理进行分类,形状偏差比例比ConvNeXt提高了8%–12%,更接近人类视觉感知方式。
-
有效感受野扩展:WTConv显著扩展了CNN的有效感受野,即使在使用较小卷积核的情况下,也能实现接近全局的感受野覆盖。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









