






Clickhouse知识介绍
简介
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
数据库分类
应用的用途不一样,要求也不一样,侧重点也不一样,我们需要根据实际情况选择适合自己的数据库, 没有万能的数据库,只有综合考虑后适合自己的数据库。
行式数据库
典型的有mysql,oracle,sqlserver, posgreesql
这类数据库适用于OLTP 类应用场景:
对数据一致性要求高,需要严格支持ACID 数据库特性,对数据有频繁增删改查需求
优点:根据索引在几百万数据范围内单点处理具有很高的并发性,支持事务,占用资源少,能严格保证数据一致性
缺点:聚合很影响性能,尤其大数据量下聚合可能需要几秒甚至几十秒,对分布式支持度不够,不适合集群存储(也可以通过分库读写分离达到一定的集群效果),不适合大数据量存储查询,全文索引支持度不够
这类数据的物理存储是按行存储的
我们可以认为数据库是一块一块数据存储的
假如有如下表结构:
Create table people(id int ,name varchar,age int ,des varchar)
每一块的结构大概这样:
第一块存储id1-100的所有数据(block1)
| 1 | 张三 | 22 | 学生 | Createversion | Deleteversion | 2 | 李四 | 24 | 学生 | Createversion | Deleteversion | ………. |
第二块存储101-200的所有数据(block2)
| 101 | 张三 | 22 | 学生 | Createversion | Deleteversion | 102 | 李四 | 24 | 学生 | Createversion | Deleteversion | ………. |
另外数据库还有一个索引文件类似
| 1 =table1-0 | 2=block1 -7 | 2=block1 -7 | ……….. | 101=block2-0 | 102=block2-7 | …….. |
实际索引文件不是线性的,而是由于物理存储的局限,最大化利用磁盘,一般采用的树状结构(类似B+tree)结构
列式数据库
典型的有clickhouse sysbase Hbase(半列式数据库和其他数据库有些区别) 等
这类数据库一般为了OLAP应用系统服务的
优点: 一般为OLAP应用系统服务的,适合聚合类数据分析,聚合速度较快。支持分布式,能支撑较大的数据量,适合宽表设计,不用遵守范式规约,获取宽表中的少量字段速度比较快,一般支持副本设计。
缺点:对单条记录的全部字段查询低于常用的mysql关系型数据库。一般都是通过版本号修改数据,修改性能较差,一般不支持事务。
这类数据的物理存储是按行存储的
我们可以认为数据库是一块一块数据存储的
假如有如下表结构:
Create table people(id int ,name varchar,age int ,des varchar)
每一块的结构大概这样:
第一块(block1)
| 1 | 2 | 3 | 4 | ……… | 500 |
第二块(block2)
| 张三 | 李四 | 王五 | 张杰 | ……… |
第三块(block3)
| 23 | 25 | 28 | 35 | ……… |
………
一般这种索引都是稀疏索引,当然关系型数据库也是稀疏索引,只是没有这么稀疏
像clickhouse 必须指定一个自增键,然后像如下方式:
| 1-500(id block1) | 501 -1000(id block2) |
其他数据库
类似es MongoDB 之类的文档数据库
Es 主要优势是倒排索引(当然也有正排索引)
一把的搜索引擎都有至少三个文件
1.文档id(docid) 到文档(doc)的映射
2.单词termid 到term 的映射
3,termid 到 docid 映射
优点: 适合全文索引,由于有二级索引所以有快速的搜索能力,支持分布式,可以处理几千万-10几亿的中等规模数据,支持副本分片,
缺点:不支持事务,插入性能偏低,对海量数据聚合有性能压力,比较消耗资源,比较占用磁盘空间,对修改也是覆盖版本号。
Key -value 数据库
一般只内存数据库,比如reids Memcached
优势,并发能力特别高,,由于完全使用内存,,支持分布式
缺点: 大部分情况支持按点的单点查询,数据容量有限,一般对于热点数据查询,一般不提供强一致性
Clickhouse 主要文件
![]()
以看到clickhouse分区实现很简单,只是简单通过目录名字区分分区

可以看到clickhouse 主要有以下文件组成
Columns.txt 这个主要放表里的所有字段
Count.txt 记录该分区总的记录数
Checksum.text 文件校验码检查文件是否完整
default_compression_codec.txt 数据文件采用的压缩算法
id.bin id列的数据文件,由于clickhouse是列式数据库,所以每个字段都有对应的bin文件
id.mrk2 标记文件,一般一个bin有多个block ,mark就是标记每个块的压缩数据便宜量和解压数据偏移量,每个字段都对应一个mark文件
minmax_collectDate idk 主要是索引文件,一般建表指定的主键,标志每个快的最大最小值,方便可以对块进行过滤,不读取不在范围内的块。
Clickhouse 优缺点
优点:
1.Clickhouse 是一款典型的列式数据库所以具有列式数据的的优点
2. clickhouse对数据有压缩,可以有效减少磁盘存储。可以在相同数据量下读取更少的磁盘完成查询
3.clickhouse的文件结构简单,有很强的插入性能
4. clickhouse 可以有效利用现代cpu的SSE4 指令达到并行计算的目的
5.clickhouse是按块处理的,可以多线程多个块进行处理,符合现在mpp架构的主流
6.自动分区合并,有效减少文件数量
7.支持大部分的sql语法
缺点:
1.对一条记录查询所有字段并不是其擅长的
2.索引都是块级别的索引,属于稀疏索引
3.分布式部署需要依赖zookeeper
4.修改也是通过类似版本号处理的,
5.不支持事务,join 支持也有限
6,由于采用的布隆过滤器,有些函数只是近似值不是精确值(distinct values, medians, quantiles)
Clickhouse 数据类型
string,Int8-64,UInt8-64 ,Float32, Float64,FixedString,Date,DateTime,Enum8-16,Nested(镶嵌类型只能镶嵌一层)
Clickhouse 常用引擎
MergeTree 合并树引擎
ReplicatedMergeTree 带副本的树引擎
Distribute 分布式表引擎
Clickhouse java类库
<dependency>
<groupId>com.github.virtusai</groupId>
<artifactId>clickhouse-client-java</artifactId>
<version>-SNAPSHOT</version>
</dependency> (http 类库)
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>RELEASE</version>
</dependency>(jdbc类库)
Clickhouse 单机安装
1.下载安装包:
curl -O https://repo.clickhouse.tech/tgz/clickhouse-common-static-21.7.1.7029.tgz
curl -O https://repo.clickhouse.tech/tgz/clickhouse-common-static-dbg-21.7.1.7029.tgz
curl -O https://repo.clickhouse.tech/tgz/clickhouse-server-21.7.1.7029.tgz
curl -O https://repo.clickhouse.tech/tgz/clickhouse-client-21.7.1.7029.tgz
2.解压并安装clickhouse
tar -xzvf clickhouse-common-static-20.10.2.20.tgz
clickhouse-common-static-20.10.2.20/install/doinst.sh
tar -xzvf clickhouse-common-static-dbg-20.10.2.20.tgz
clickhouse-common-static-dbg-20.10.2.20/install/doinst.sh
tar -xzvf clickhouse-server-20.10.2.20.tgz
clickhouse-server-20.10.2.20/install/doinst.sh
tar -xzvf clickhouse-client-20.10.2.20.tgz
clickhouse-client-20.10.2.20/install/doinst.sh
3.修改配置文件
vim /etc/clickhouse-server/config.xml
修改日志存储目录

打开绑定host
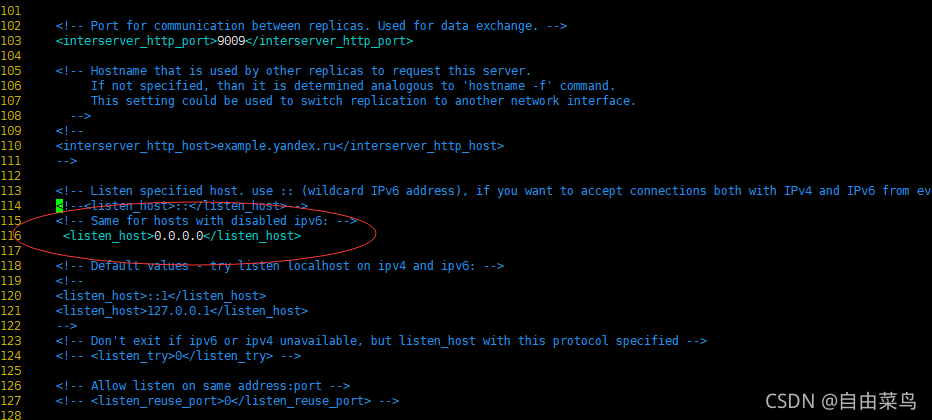
修改用户数据存储目录
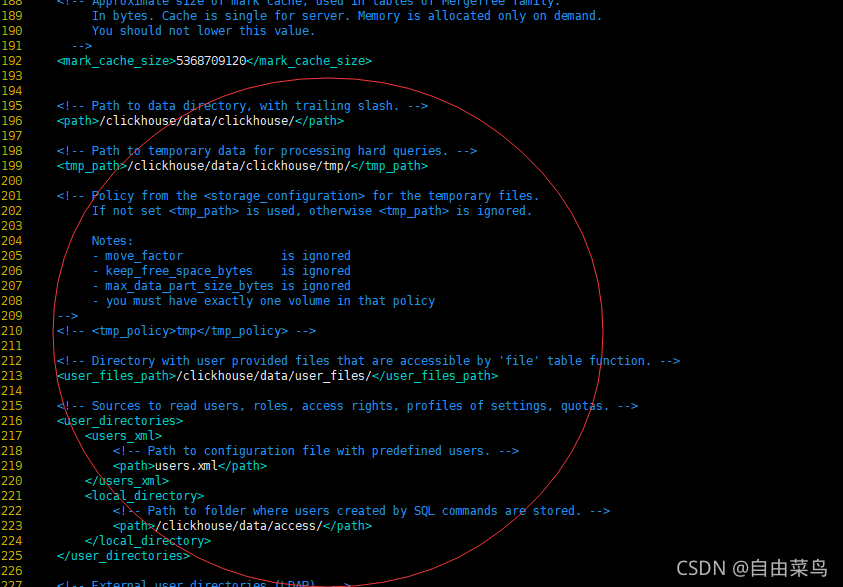
增加clikhouse用户密码
echo -n 'test123123!@#' | sha256sum | tr -d '-'
6198ca73cc6ff1b5d78287857011d9ffd70036b64d4ce8bf48af769817a6c891
vi /etc/clickhouse-server/users.xml
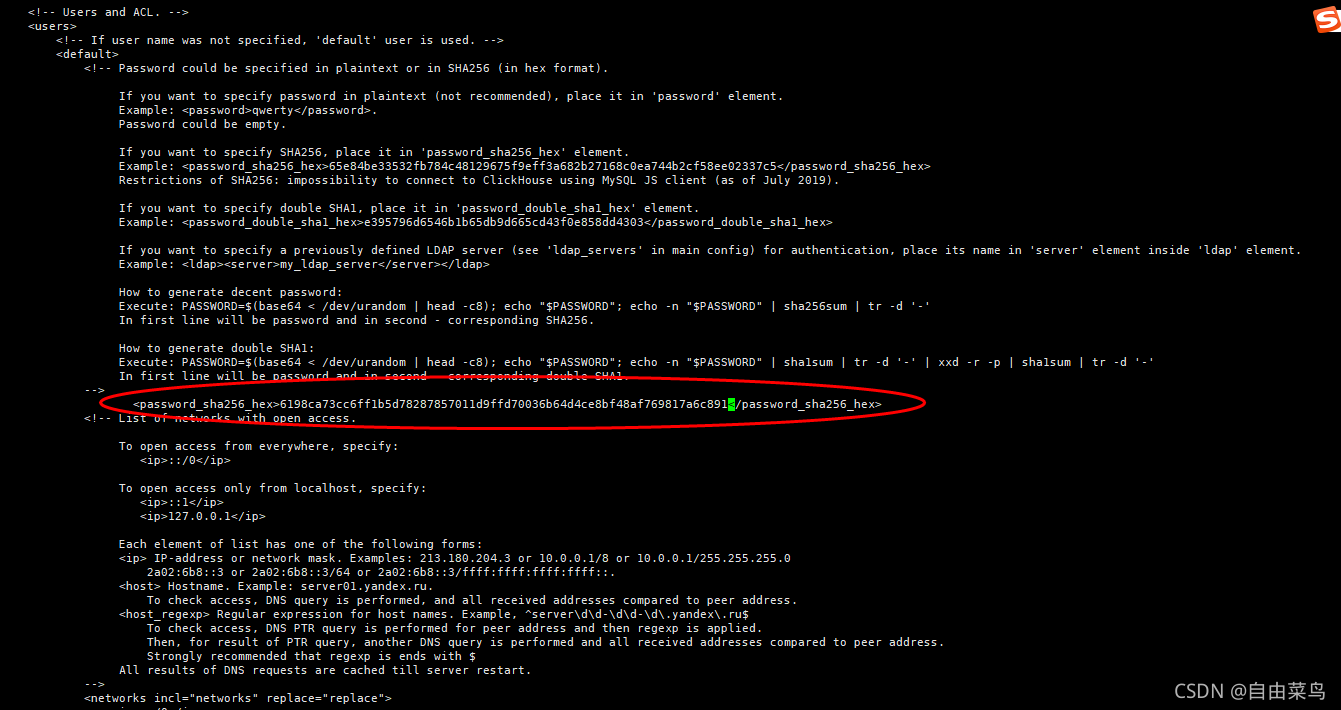
4.重启clickhouse
systemctl stop clickhouse-server
systemctl start clickhouse-server
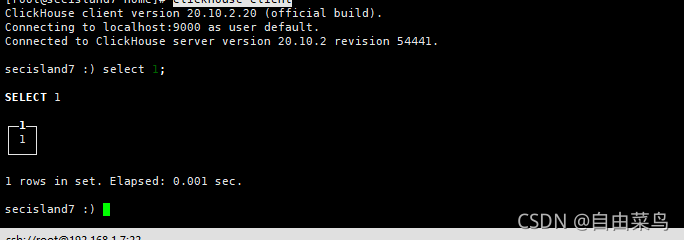
5.验证是否安装成功
clickhouse-client -h 127.0.0.1 -udefault --password
Clickhouse 集群安装
集群安装需要先在各个节点安装单节点的clickhouse(以下安装以192.168.1.9 和119.168.1.54 双节点为例)
1.安装zookper
修改hostname
vi /etc/hostname (将192.168.1.54 改为clickhouse1)
![]()
hostname clickhouse1
同理将192.168.1.9 改为clickhouse2
配置host名称:
vi /etc/hosts
添加节点名称(192.168.1.54 和192.168.1.9 都需要配置)

mkdir -p /home/zook/
cd /home/zook
将zookeeper-3.4.9.tar.gz 上传到当前目录并解压(请自行在官网下载)
cd zookeeper-3.4.9/conf
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg
vi zoo.cfg
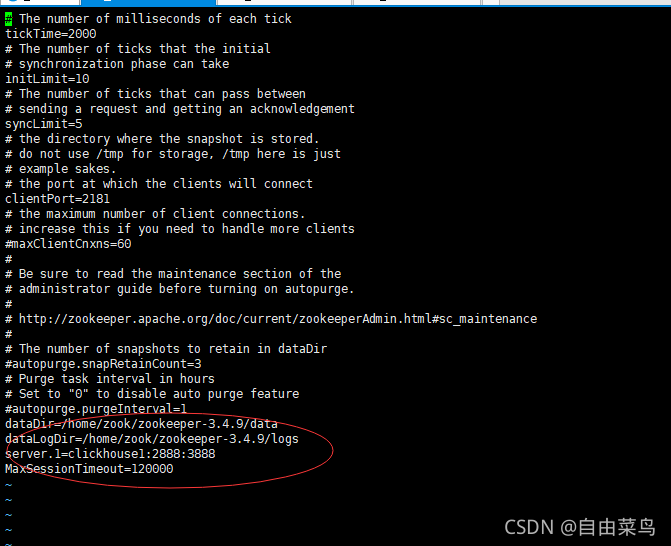
cd /home/zook/zookeeper-3.4.9/bin
./zkServer.sh 启动zookeeper
验证zookper 是否安装成功
./zkCli.sh
ls /

显示如下则说明安装成功
2.配置clickHouse集群
cd /etc/clickhouse-server/config.d
touch metrika.xml
增加zookeeper 配置信息
vi metrika.xml
内容如下
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>192.168.1.54</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
将zookeeper 配置引入clickHouse 配置属性中
cd ..
vi config.xml
引入zookeeper 配置:
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
修改optional 配置为false
<zookeeper incl="zookeeper-servers" optional="false" />
增加宏变量(宏变量为了分布式建表时可以用占位符在各个节点一条语句建立多个本地表从而形成分布式表)
<macros>
<shard>01</shard>
<replica>192.168.1.54</replica>
</macros>
注意宏变量每个节点都不一样,请根据实际情况配置。
效果如下:

增加集群配置:
Vi /etc/clickhouse-server/config.xml
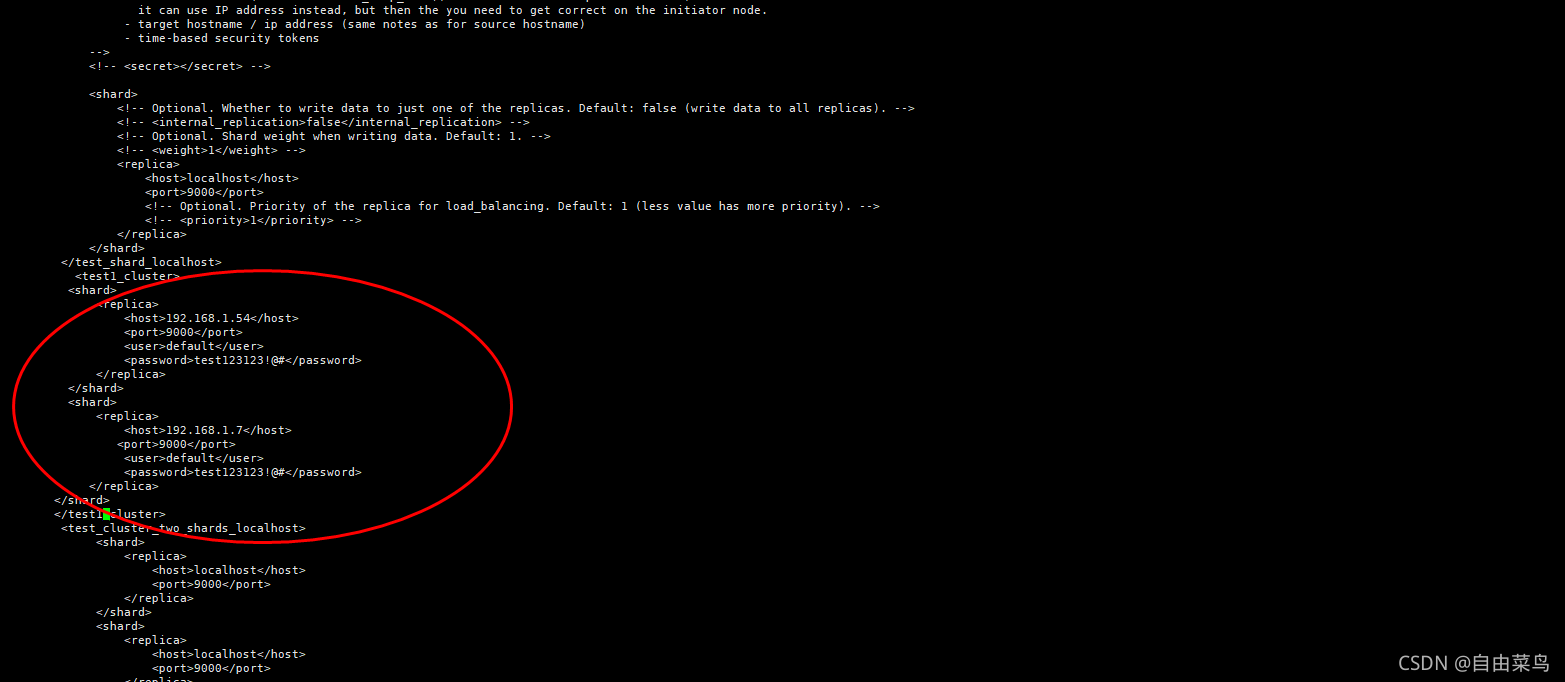
192.168.1.54 和192.168.1.9 都需要配置
详情如下:
<test1_cluster>
<shard>
<replica>
<host>192.168.1.54</host>
<port>9000</port>
<user>default</user>
<password>test123123!@#</password>
</replica>
</shard>
<shard>
<replica>
<host>192.168.1.9</host>
<port>9000</port>
<user>default</user>
<password>test123123!@#</password>
</replica>
</shard>
</test1_cluster>
建立2个分片demo
重新启动每个节点上的clickhouse
systemctl stop clickhouse-server
systemctl start clickhouse-server
建立数据库和数据库表
CREATE database test1 ON CLUSTER 'test1_cluster';
CREATE TABLE test1.secislog ON CLUSTER 'test1_cluster'(`id` UInt64,`collectIp` String,`collectType` String,`collectDate` DateTime,`eventDate` DateTime,`content` String,`serviceType` String,`eventType` String,`softwareName` String, `eventDetailType` String,`eventCode` String,`object` String,`eventName` String,`eventCount` UInt32,`result` String,`level` UInt8,`protocol` String, `date` String,`time` Int32,`sourceIp` String,`sourcePort` UInt16,`sourceHostname` String,`sourceProcess` String,`sourceUser` String,`sourceOrgname` String,`sourceGeo` String,`sourceCountry` String,`sourceProvince` String,`sourceCity` String,`targetIp` String,`targetPort` Int32,`targetHostname` String,`targetProcess` String,`targetUser` String,`hostIp` String,`hostName` String,`networkArea` String,`businessType` String,`baseCustomUser` String,`domain` String,`weburl` String,`requestParam` String,`httpMethod` String,`sessionId` String,`httpFlow` String,`httpReferrer` String,`httpAgent` String,`httpBrowser` String,`requestTime` Float64,`httpRobot` String)ENGINE = MergeTree() PARTITION BY toYYYYMMDD(collectDate) ORDER BY (collectDate,hostIp);
建立分布式代理表
create TABLE test1.secislog_all ON CLUSTER 'test1_cluster'
(
`id` UInt64,
`collectIp` String,
`collectType` String,
`collectDate` DateTime,
`eventDate` DateTime,
`content` String,
`serviceType` String,
`eventType` String,
`softwareName` String,
`eventDetailType` String,
`eventCode` String,
`object` String,
`eventName` String,
`eventCount` UInt32,
`result` String,
`level` UInt8,
`protocol` String,
`date` String,
`time` Int32,
`sourceIp` String,
`sourcePort` UInt16,
`sourceHostname` String,
`sourceProcess` String,
`sourceUser` String,
`sourceOrgname` String,
`sourceGeo` String,
`sourceCountry` String,
`sourceProvince` String,
`sourceCity` String,
`targetIp` String,
`targetPort` Int32,
`targetHostname` String,
`targetProcess` String,
`targetUser` String,
`hostIp` String,
`hostName` String,
`networkArea` String,
`businessType` String,
`baseCustomUser` String,
`domain` String,
`weburl` String,
`requestParam` String,
`httpMethod` String,
`sessionId` String,
`httpFlow` String,
`httpReferrer` String,
`httpAgent` String,
`httpBrowser` String,
`requestTime` Float64,
`httpRobot` String
)ENGINE=Distributed('test1_cluster','test1','secislog',rand());














 3427
3427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









