







作者 | Evan Harris
译者 | Monanfei
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】这篇文章为大家介绍了一个开源项目——sk-dist。在一台没有并行化的单机上进行超参数调优,需要 7.2 分钟,而在一百多个核心的 Spark 群集上用它进行超参数调优,只需要 3.4 秒,把训练 sk-learn 的速度提升了 100 倍。
sk-dist 简介
sk-dist 是一个开源项目,它使用 Spark 来分发 scikit-learn 元估计器。常见的元估计器有决策树(随机森林和其他的随机树),超参数调优器(格网搜索和随机搜索),以及多类别处理技术(一对多和一对一)。
sk-dist 的主要动机是填补传统机器学习在模型分布式训练上的空白。除去神经网络和深度学习,我们发现在单个数据集上训练单个模型并不怎么花时间,反而当我们使用元估计器(例如网格搜索或集合等),在数据集的多次迭代上训练模型的多次迭代花费了大量时间。

使用 sk-dist 的例子
以手写数字数据集为例,我们事先对图像进行了编码,以便于进行适当的分类。我们可以在一台机器上飞速的训练一个支持向量机,数据集有1797 条记录,整个训练过程不到 1 秒钟。但是,超参数调整却需要在训练集的不同子集上进行大量的训练工作。
如下图所示,我们构建了一个参数网格,本次超参数调优总共需要 1050 个训练任务。在具有一百多个核心的 Spark 群集上使用 sk-dist 进行超参数调优,我们只需要 3.4 秒,而在一台没有并行化的单机上进行超参数调优,却需要 7.2 分钟。
import time
from sklearn import datasets, svm
from skdist.distribute.search import DistGridSearchCV
from pyspark.sql import SparkSession
# instantiate spark session
spark = (
SparkSession
.builder
.getOrCreate()
)
sc = spark.sparkContext
# the digits dataset
digits = datasets.load_digits()
X = digits["data"]
y = digits["target"]
# create a classifier: a support vector classifier
classifier = svm.SVC()
param_grid = {
"C": [0.01, 0.01, 0.1, 1.0, 10.0, 20.0, 50.0],
"gamma": ["scale", "auto", 0.001, 0.01, 0.1],
"kernel": ["rbf", "poly", "sigmoid"]
}
scoring = "f1_weighted"
cv = 10
# hyperparameter optimization
start = time.time()
model = DistGridSearchCV(
classifier, param_grid,
sc=sc, cv=cv, scoring=scoring,
verbose=True
)
model.fit(X,y)
print("Train time: {0}".format(time.time() - start))
print("Best score: {0}".format(model.best_score_))
------------------------------
Spark context found; running with spark
Fitting 10 folds for each of 105 candidates, totalling 1050 fits
Train time: 3.380601406097412
Best score: 0.981450024203508
上例展示了一个常见的超参数调优场景:首先将数据拟合到内存中,然后再去训练单个分类器。但是,超参数调优所需的拟合任务数很快就会增加。下图展示了使用 sk-dist 运行格网搜索的流程:
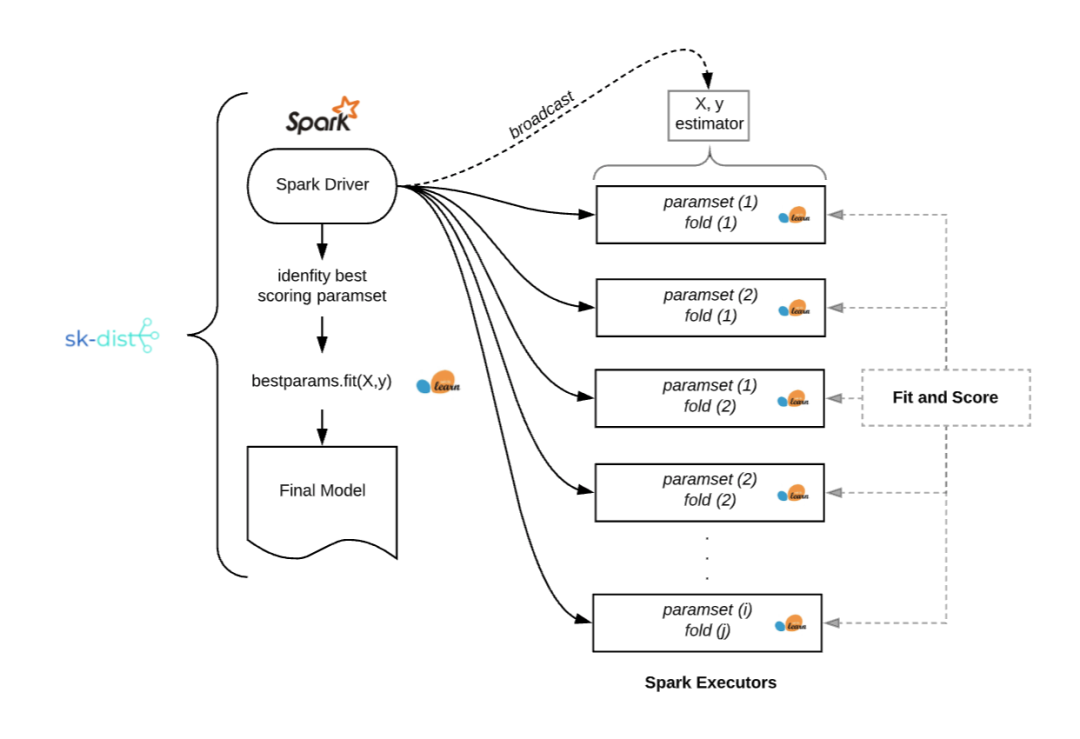
对于 Ibotta 传统机器学习的实际应用,我们经常发现自己处于以下类似情况:使用多个简单的分类器对中小型数据(100k~1M)进行多次迭代,企图解决超参数调优、集合模型和多类别问题。
目前的解决方案
现在,分布式的传统机器学习元估计训练有两个主流解决方案。第一个,也是最简单的一个:使用 joblib 实现 scikit-learn 内置元估计器的并行化。这和 sk-dist 非常相似,但是该方法却存在一个很大的限因素:处理性能受到单机资源的限制。即使在一台具有数百个内核的机器上实行并行化,它的性能与使用 spark 的 sk-dist 相比,也要逊色许多。这是因为 Spark 具有执行器的精细内存规范,优秀的容错能力,以及成本控制选项,例如为工作节点使用专门的实例。
另一个现存的解决方案是 Spark ML。它是Spark的本地机器学习库,支持许多与 scikit-learn 相同的算法,用于分类和回归问题。它还具有树集合和网格搜索等元估计,以及对多类别问题的支持。虽然这听起来很完美,似乎能够解决分布式 scikit-learn 机器学习问题,但是它并不能用我们感兴趣的并行方式进行训练。
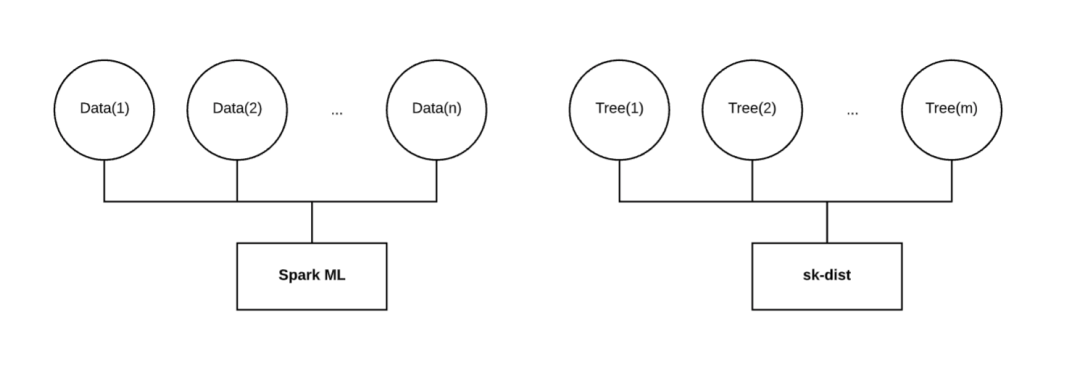
如上图所示,Spark ML 将针对分布在许多执行程序上的数据训练单个模型。当数据量很大,并且不适合单机内存时,该方法很有效。但是,当数据很小时,scikit-learn 可能在单机上表现欠佳。此外,当训练随机森林模型时,Spark ML 会按顺序训练每个决策树。无论分配给任务的资源有多大,该任务的挂起时间都将与决策树的数量成线性比例。
对于网格搜索,Spark ML 采用了并行参数,该参数将并行训练单个模型。但是,每个单独的模型仍在跨执行器的分布数据上进行训练。如果纯粹沿着模型的维度而不是数据的分布,那么任务的总并行性能只能发挥一小部分。
因此,我们希望有一个新的解决方案,将我们的数据分布在与 Spark ML不同的维度上。当我们使用小型或中型数据时,将数据拟合到内存中将不再是问题。在随机森林的例子中,我们希望将训练数据完整地派送给每个执行器,在每个执行器上拟合一个独立的决策树,并将那些拟合好的决策树收回,从而集成随机森林。通过沿着该维度实行并行化,执行速度可以比串行分发数据和训练决策树快几个数量级。网格搜索和多类别等其他元估计技术也应该采用这种类似的并行方式。
sk-dist 的特点
鉴于这些现有解决方案的局限性,sk-dist 应时而生。sk-dist 最重要的是分发模型,而不是数据。
尽管 sk-dist 主要关注元估计器的分布式训练,d但它还包括使用 Spark 进行 scikit-learn 模型分布式预测的模块、几个无需使用 Spark 的前/后处理 scikit-learn 变换器、以及使用或不使用Spark 的灵活的特征编码器。
-
分布式训练:使用 Spark 分发元估计器训练。支持以下算法:使用网格搜索和随机搜索的超参数调优,使用随机森林的树集成,其他树和随机树嵌入,以及一对多、一对一的多类别问题策略。
-
分布式预测:使用 Spark DataFrames 分配拟合后的 scikit-learn 估计器进行预测。通过便携式的 scikit-learn 估计器,该方法使得大尺度的分布式预测成为可能。这些估计器可以与 Spark 一起使用,也可以不与 Spark 一起使用。
-
特征编码:使用 Encoderizer 对特征进行灵活编码。 Encoderizer 可以使用或不使用Spark 并行化。它将推断数据类型和形状,自动选择并应用最佳的默认特征变换器,对数据进行编码。作为一个完全可定制的特征联合编码器,它还具有使用 Spark 进行分布式变换的附加优势。
sk-dist 的适用情形
并非所有的机器学习问题都适合使用 sk-dist,以下是决定是否使用 sk-dist 的一些指导原则:
-
传统的机器学习: 广义线性模型,随机梯度下降,最近邻,决策树和朴素贝叶斯等方法与 sk-dist 配合良好。这些模型都已在 scikit-learn 中集成,用户可以使用 sk-dist 元估计器直接实现。
-
中小型数据:大数据无法与 sk-dist 一起使用。值得注意的是,训练分布的维度是沿着模型的轴,而不是数据。数据不仅需要适合每个执行器的内存,还要小到可以广播。根据 Spark 的配置,最大广播量可能会受到限制。
-
Spark 的使用:sk-dist 的核心功能需要运行Spark。对于个人或小型数据科学团队而言,从经济上来讲可能并不可行。此外,为了以经济有效的方式充分利用 sk-dist,需要对 Spark 进行一些调整和配置,这要求使用者具备一些 Spark 的基础知识。
值得引起注意的是,虽然神经网络和深度学习在技术上可以与 sk-dist 一起使用,但这些技术需要大量的训练数据,有时需要专门的硬件设施才能工作。深度学习不是 sk-dist 的目标,因为它违反了上面的(1)和(2)。作为替代技术, Amazon SageMaker 可以配合神经网络或深度学习进行使用。
原文:
https://medium.com/building-ibotta/train-sklearn-100x-faster-bec530fc1f45
(*本文为AI科技大本营原创文章,转载请联系微信 1092722531)
推荐阅读
六大主题报告,四大技术专题,AI开发者大会首日精华内容全回顾
AI ProCon圆满落幕,五大技术专场精彩瞬间不容错过
CSDN“2019 优秀AI、IoT应用案例TOP 30+”正式发布
如何打造高质量的机器学习数据集?
从模型到应用,一文读懂因子分解机
用Python爬取淘宝2000款套套
7段代码带你玩转Python条件语句
高级软件工程师教会小白的那些事!
谁说 C++ 的强制类型转换很难懂?

你点的每个“在看”,我都认真当成了喜欢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









