







(图片源自百度百科)
作者 | Ekaterina Nikonova,Jakub Gemrot
译者 | Tianyu
出品 | AI科技大本营(ID:rgznai100)
现在说起《愤怒的小鸟》游戏,要把人的回忆一下拉扯到差不多十年前了。
它是一款当时一经推出就广受欢迎的游戏,玩家可以用弹弓把若干只小鸟弹射出去,目标是摧毁所有绿色的猪,并获得尽可能高的分数,经常有很多猪藏在复杂的结构之中。由于顺序的决策、不确定的游戏环境、复杂的状态和动作、功能特性不同的鸟,以及最佳弹射时机等因素,都使得《愤怒的小鸟》很难拥有一款好的 AI 代理。
近日,来自研究者发布论文《Deep Q-Network for Angry Birds》称,他们采用 DDDQN(Double Dueling Deep Q-network)算法实现了一款深度强化学习应用,可以用来玩《愤怒的小鸟》。他们的目的之一是创造一个游戏智能体,可以基于之前玩家在前21关的游戏记录来进行游戏闯关。
为了实现这一目的,他们收集了游戏记录的数据集,为 DQN 游戏代理提供了多种多样的方案。游戏中需要做很多有关顺序的决策,两次弹射之间会相互影响,每一次弹射的精准度也很重要。例如,一次糟糕的决策可能会导致一只猪被若干个物体卡住。因此,为了更好地完成游戏中的任务,游戏代理要有基于决策对结果进行预测和模拟的能力。
以下为《Deep Q-Network for Angry Birds》论文的内容概述:
相关工作
2012年,首次举办了《愤怒的小鸟》 AI 大赛,随之出现了很多款游戏代理。在这里介绍两款比较优秀的代理,第一个是由来自捷克技术大学的队伍所开发的 Datalab Birds 2014,该游戏代理至今保持着第三名的位置。就像他们在论文中描述的,他们的主要思想是基于当前环境、可能的弹射轨迹和鸟的类型来制定最佳策略。第二个是由滑铁卢大学和 Zazzle 在 2017 《愤怒的小鸟》AI 大赛中共同开发的 Eagles Wings 智能玩家,他们的代理目前排在第 16 位。据称,该游戏代理基于人工调试过的结构分析,即在多个策略中做选择,开发了一项简单的多策略能力。他们使用了机器学习算法 xgboost 学习决策制定能力。
背景介绍
为了解决《愤怒的小鸟》中的顺序决策问题,我们基于每个时间步长来考虑游戏环境 ε 。在每个时间步长 t,代理都会得到观察值St,然后从可能的动作集中选择一个动作
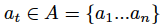 ,接下来会得到奖励项
,接下来会得到奖励项
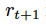 。接下来代理的目标是基于下面的公式将奖励项最大化:
。接下来代理的目标是基于下面的公式将奖励项最大化:
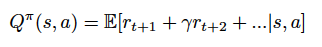
在上面的公式中,s 为当前状态,a 为所选的动作,
为奖励项,
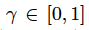 是权重系数,来决定奖励项对未来结果的重要性。现在我们定义最佳 Q 值如下:
是权重系数,来决定奖励项对未来结果的重要性。现在我们定义最佳 Q 值如下:
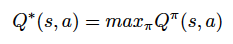
在每个状态选择最大值所对应的动作,我们就可以获得最佳策略。
DQN 算法理论基础
为了模拟最佳 action-value 函数,我们使用深度神经网络作为非线性函数逼近器,我们定义一个逼近函数:
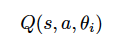
其中,
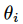 为 Q 网络进行第 i 次迭代的权重。
为 Q 网络进行第 i 次迭代的权重。
如论文中所说,将强化学习算法与非线性函数逼近器,如神经网络,结合使用会不稳定,甚至产生偏移,原因如下:a) 序列中观察值之间的关联性;b) Q 值与 target 值
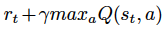 之间的关联性;c) 该方法对 Q 值的变化极其敏感。
之间的关联性;c) 该方法对 Q 值的变化极其敏感。
Deep Q-learning 试图用技术解决第一个问题,即经验回放。该技术通过将所收集的数据随机化,去除了序列中观测值之间的相关性。我们对经验的定义如下:
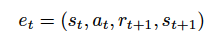
其中,
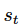 为 t 时刻的状态,
为 t 时刻的状态,
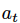 为 t 时刻采取的动作,
为 t 时刻采取的动作,
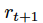 为 t+1 时刻的奖励,
为 t+1 时刻的奖励,
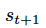 为执行
后的状态。我们将经验保存在经验集中:
为执行
后的状态。我们将经验保存在经验集中:
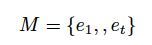
接下来,我们从经验集 M 中抽样出部分经验,在 Q 网络中对 Q 值进行更新。
为了解决第二个问题,需要用到下面的损失函数:
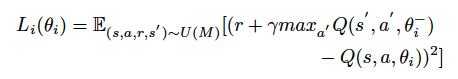
其中,i 为迭代次数,
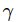 为权重系数,
为权重系数,
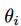 为实时网络的权重,
为实时网络的权重,
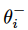 为目标网络的权重。
为目标网络的权重。
接下来,我们 DQN 的目标如下:
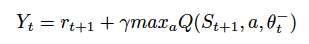
A. Double Deep Q-Networks
原始的 DQN 算法对动作选择和动作表现的评估两个步骤都采用了最大值,这很可能导致过度估计。基于这一缺陷,Double Q-learning 算法产生了。不同于传统 DQN 算法仅使用一个神经网络,如今我们使用一个网络选择动作,再使用另一个网络对所做的决策进行评估。因此,我们可以将原始的 Q-learning 目标改写为:
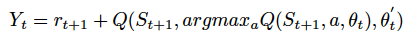
其中,
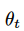 为实时权重,
为实时权重,
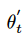 为第二个权重集,即用实时权重进行动作选择,用第二个权重对其评估。幸运的是,同样的方法也可以应用到 DQN 算法中,我们可以对更新函数进行替换,如下:
为第二个权重集,即用实时权重进行动作选择,用第二个权重对其评估。幸运的是,同样的方法也可以应用到 DQN 算法中,我们可以对更新函数进行替换,如下:
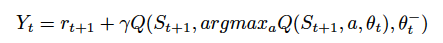
其中,
为 DQN 的实时权重,
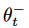 为目标 DQN 的权重。
为目标 DQN 的权重。
B. Dueling Deep Q-Networks
在某些场景中,不同动作获得的值是很接近的,没必要对每个动作进行评估。在《愤怒的小鸟》中,有时候玩家会陷入某种无解的处境,如猪被一些物体卡住了。在这种情况下,无论采取什么动作都是一样的结果,因此任何动作的得分都是几乎一样的,而我们只在意这个状态本身的分数。考虑到对这些场景的优化,Dueling 结构应运而生了。为了实现 Dueling Q-learning 结构,我们需要使用两个全连接层。将卷积层的输出分成两部分后,我们需要再把它们结合以获得 Q 函数。首先定义价值函数:
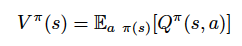
优势函数为:
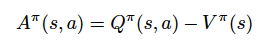
也就是说,价值函数可以告诉我们某个具体状态的好坏程度,而优势函数告诉我们每个动作的重要性。这样我们可以构造我们的第一个全连接层,得到输出
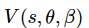 ,以及第二个全连接层,可得到输出
,以及第二个全连接层,可得到输出
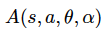 ,此处的 α 和 β 都是全连接层的权重,θ 为卷积层的权重。为了将两个值结合并获得 Q 值,我们定义网络的最后一个模块如下:
,此处的 α 和 β 都是全连接层的权重,θ 为卷积层的权重。为了将两个值结合并获得 Q 值,我们定义网络的最后一个模块如下:
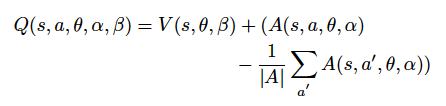
这样我们就得到了价值估计函数和优势估计函数,将其与之前定义好的 Deep Q-network 和 Double Q-learning 结合使用,就可以用在《愤怒的小鸟》这款游戏中了。
将 DQN 应用于 AIBIRDS
为了将 DQN 应用于《愤怒的小鸟》,我们首先需要定义:a) 状态,b) 动作,c) Q-network 结构,d) 奖励函数。AIBirds 竞赛组织方提供了可以对游戏进行截图的软件,可以得到 840x480 像素的图片。图1为逐步处理图片的过程。

图1:游戏截图的处理过程,从左到右:原始截图,剪裁,调整大小,标准化
我们规定动作为
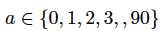 ,其中每个数字代表射出的角度。接下来,我们基于软件为每个给定角度找到最终的释放点。为了计算释放点,轨迹模块首先寻找弹弓的参考点,然后计算释放点。
,其中每个数字代表射出的角度。接下来,我们基于软件为每个给定角度找到最终的释放点。为了计算释放点,轨迹模块首先寻找弹弓的参考点,然后计算释放点。
我们的 DQN 结构是基于 Google DeepMind DQN 的,图2为我们的 DQN 结构。该模型包括4个卷积层,kernel 分别为 8x8,4x4,3x3,7x7,strides 分别为 4x4,2x2,2x2,1x1。最后一个卷积层后面连接了两个 flatten 层,最后结合生成 Q 值。
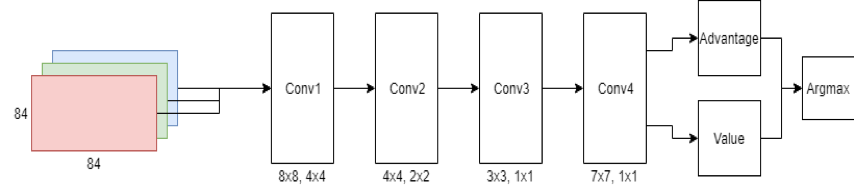 图2:Double Dueling DQN 结构
图2:Double Dueling DQN 结构
奖励函数所使用的技术通常被称为奖励修剪(reward clipping)。这种方法将很大或很小的分数修剪为1或-1分的得分,来代表一个好动作或坏动作。《愤怒的小鸟》这款游戏的主要目标除了过关,还要活得尽可能高的分数。考虑到这一点,我们需要改变奖励函数,如下:

上式中,score 为 s 状态下采用动作 a 后的分数,maximum score of current level 为当前关卡的历史最高得分。基于这个公式,我们期望游戏代理可以学习分数的重要性,并通过学习动作的奖励机制来刷新当前关卡的得分。
A. 训练集
我们的训练集包括《愤怒的小鸟》经典系列的21个关卡。在训练阶段,游戏代理基于 115000 张图进行网络的训练。在游戏截屏前,代理需要等候5秒钟。这一项小调整是必需的,为了让鸟被发射后所产生的震动得以平复下来。
B. 验证集
我们的验证集包括《愤怒的小鸟》经典系列的10个关卡。由于代理的训练集中只有红鸟、蓝鸟和黄鸟,所以我们不得不挑选没有新鸟的关卡作为验证集。从第二页和第三页挑选的关卡比第一页的难度要高一些。在玩这些关卡时,玩家必须找到一些不太明显的结构上的弱点,并提前仔细规划策略。
结果
我们对竞赛中几个参赛结果进行了对比,如图3。对不同的代理结果进行对比,可以帮助我们了解哪项 AI 技术更适用于《愤怒的小鸟》这款游戏。然而我们仍然无法搞清楚的是,和人类比起来这些游戏代理表现如何。
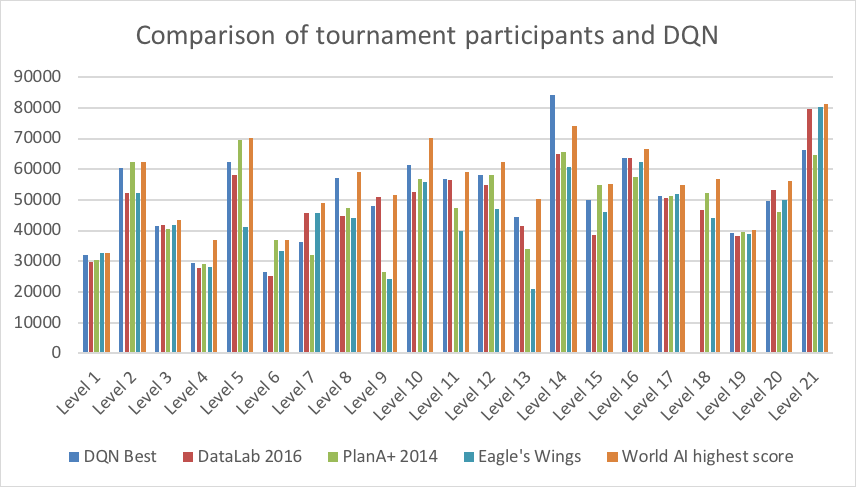
图3:几个不同的 DQN 代理对比
本篇论文中,我们还进行了 AI 和人类的对比。人类参赛者可以进行无数次尝试,直到参赛者觉得已经获得了自己的最佳分数。我们从不同水平的人中挑选参与实验者,玩家1和玩家3有玩《愤怒的小鸟》的4年游戏经验。玩家2很久之前玩过几次这款游戏,没有太多经验。玩家4过去常常玩这款游戏,但最近没怎么玩过。
如图4所示,我们的游戏代理在总分上超过了一个人类玩家,而输给了其他玩家。产生这一结果的主要原因是,代理无法通过第18关。在其他关卡中,代理可以在某些关卡上超过一些玩家。总的来说,我们的 DQN 代理在前21关获得了 1007189 分,它败给了四位人类玩家中的三位。因此我们的代理还存在非常大的提升空间。
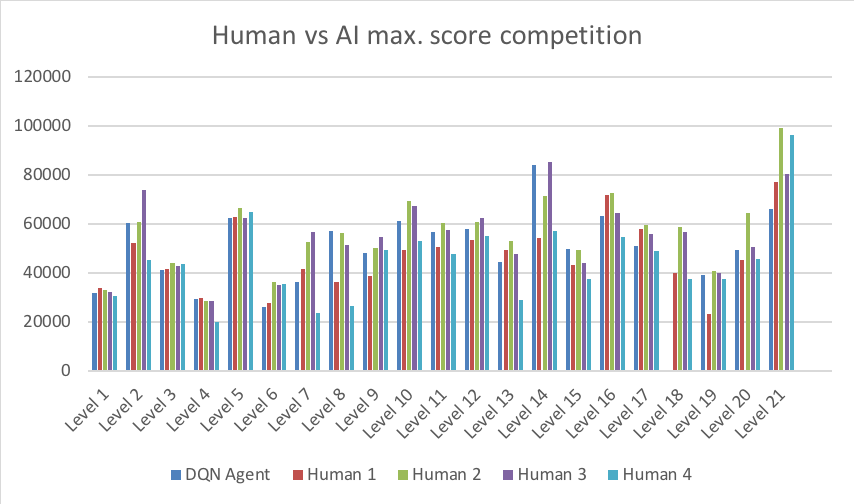
图5位代理在验证集上的表现。如我们所料,对于代理之前没有见过的关卡,大都无法通过。
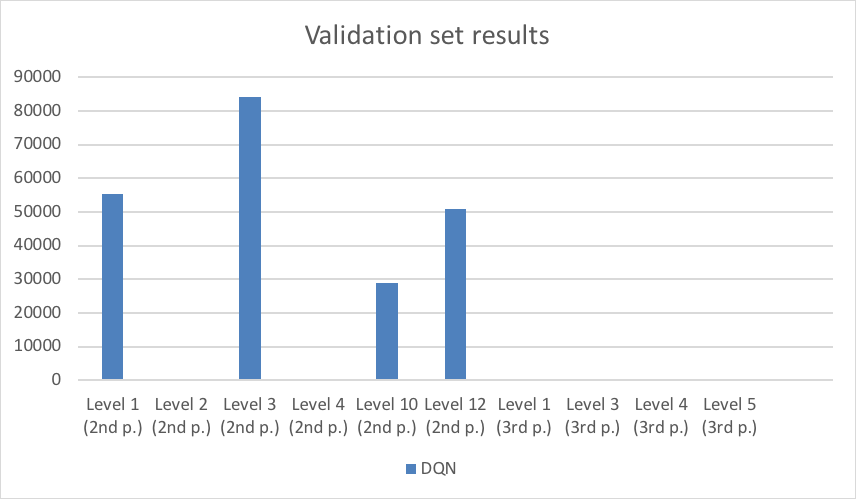
图5:DQN 代理在验证集上的结果
《愤怒的小鸟》 AI 大赛结果
除了将我们的代理与人类玩家进行对比以外,我们在 IJCAI-2018 大会上做了展示,参加了《愤怒的小鸟》 AI 大赛。该竞赛本身包括三轮:四分之一决赛、半决赛和总决赛。每一轮中,参赛的游戏代理要面对 8 个之前未见过的关卡。
表1展示了四分之一赛中全部游戏代理的总分数,在全部基于神经网络的代理中,我们的 DQ-Birds 表现最好,通过了 8 个关卡中的 3 个。MYTBirds 也使用了神经网络,但只通过了一个关卡。其它代理均使用了除神经网络以外的方法。
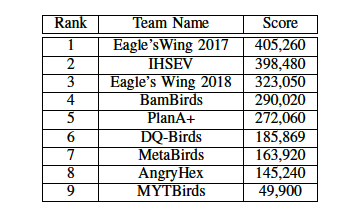
表1
结论
对于 AI 代理来说,《愤怒的小鸟》这款游戏始终是一项艰巨的任务。我们提出了一种基于 Double Dueling DQN 的游戏代理来试图解决游戏中的顺序决策问题。在目前的研究工作中,我们没有达成的目标是在这款游戏中超越人类玩家。但好的一点是,我们的代理只需要一次机会就可以通关。另外有趣的是,在大多数情况下,它只用了一次精准的弹射就击中了关键点,通过了关卡。
总之,尽管我们的代理超过了部分之前的玩家,并在 AIBirds 比赛中超过了部分参赛者,但仍存在很大的进步空间。例如,我们可以尝试在奖励函数中加入超参数。我们还可以尝试如今已公开的全部深度强化学习优化技术。下一步,我们计划基于更多的游戏关卡对游戏代理进行训练。
(*本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
早鸟票倒计时
最后1天
,扫码购票
立减2600元
!
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。

推荐阅读
简单粗暴上手TensorFlow 2.0,北大学霸力作,必须人手一册
分析Booking的150种机器学习模型,我总结了6条教训
微软也爱Python:VS Code Python全新发布!Jupyter Notebook原生支持终于来了
罗永浩向老同事道歉;三星漏洞已波及四千万用户;Clojure 1.11 即将发布 | 极客头条
真·上天!NASA招聘区块链"多功能复合型"人才, 欲保护飞行数据安全……
10 月全国程序员工资统计,一半以上的职位 5 个月没招到人
【光说不练假把式】今天说一说Kubernetes 在有赞的实践

你点的每个“在看”,我都认真当成了喜欢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









