







作者 | Jiaxu Miao、Yu Wu、Ping Liu、Yuhang Ding、Yi Yang
译者 | 刘畅
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】在以人搜人的场景中,行人会经常被各种物体遮挡。之前的行人再识别(re-id)方法要么忽略了此问题,要么是基于极端假设来解决该问题。为了解决遮挡问题,作者提出检测遮挡区域,并在特征生成和匹配过程中去排除那些遮挡区域。
在本文中,作者介绍了一种称为姿态引导特征对齐(PGFA)的新方法,该方法利用姿势界标从带遮挡的图片中分离出有用的信息。在特征构建阶段,作者利用人的关键点信息去生成注意力图。生成的注意力图会表明指定的身体部位是否被遮挡,并引导模型去关注非遮挡区域。在匹配过程中,作者将全局特征明确划分为多个部分,并使用姿态关键点信息来得到哪些部分特征属于目标。仅将可见区域用于检索。
此外,作者为遮挡行人重识别问题构建了一个大规模数据集,即OccludedDukeMTMC,这是迄今为止针对遮挡行人重识别问题最大的数据集。作者在本文构造的遮挡Re-id数据集,两个partial Reid数据集和两个常用的无遮挡Re-id数据集上进行了实验。实验结果电视,作者的方法在三个遮挡数据集上的性能大大优于现有的行人再识别方法,而在两个无遮挡的数据集上仍保持优异的性能。

论文地址:
https://yu-wu.net/pdf/ICCV2019_Occluded-reID.pdf
引言
行人再识别的任务是从图像集合中检索待查询行人图像,它在近年来取得了快速的发展。之前的行人再识别方法是从整个图像中提取特征,并将这些特征用作视觉表征,再整个图像集里面去匹配。为了构建有效的表示,已有的方法要么直接利用全局人物特征,要么结合身体部位的局部特征。
但是,这些已有工作中提出的方法并未考虑到目标人被各种物体(例如汽车,树木或其他人)遮挡的情况。
当一个人被部分遮挡时,从整个图像中提取的特征表达可能会分散目标信息。
如果模型无法区分遮挡区域和行人区域,则可能导致错误的检索结果。
例如,如图1所示,在给定的查询图像中,行人被白色汽车挡住,已有的方法可能会错误地检索具有相似汽车的人的图像。

最近,有一些工作尝试解决遮挡问题。如图2的第一行所示,在其部分ReID的问题条件中,检索图像是被物体遮挡住的,而库图像仍然是整体图像。为了抑制由遮挡引入的额外信息,这类方法首先在带检索的图像中手动裁剪被遮挡的目标,然后将未遮挡的部分用作新的查询。
但是,部分ReID问题有两个局限性:
(1)他们需要强有力的假设,即库图像里面的目标都是完整的(2)他们需要手动裁剪操作。
这样的手动过程会使裁剪结果产生人为偏见。
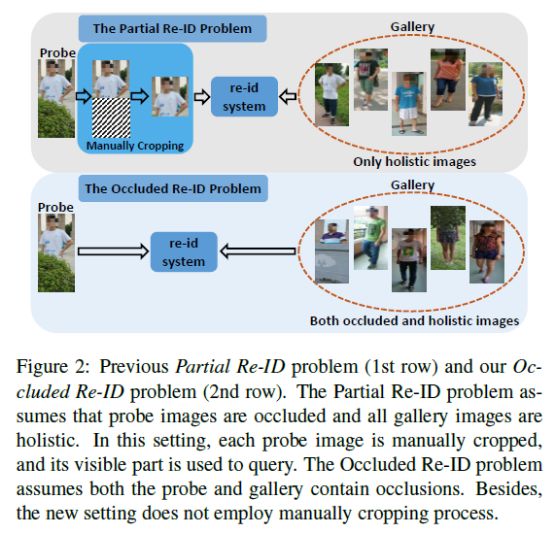
与部分Re-ID问题不同,本文提出了遮挡的Re-ID问题,在该问题中,检索图像和库图像都包含遮挡。所有待搜索图像都有遮挡,使得在检索时至少存在一个遮挡的图像。除了整体图像之外,图库集也包含被遮挡的图像,这与现实世界的场景一致。此外,考虑到效率和人为因素,遮挡的Re-ID不采用人工裁剪过程。
图2显示了部分Re-ID和被遮挡的Re-ID两个问题之间的区别。为了便于研究遮挡的Re-ID问题,我们引入了一个大数据集,名为OccludedDukeMTMC,该数据集是派生自DukeMTMC-ReID数据集。在新数据集中,所有查询图像都被各种各样的遮挡物(例如树木,汽车,其他人)遮挡,而图库图像同时包含整体图像和被遮挡的图像。
为了解决这个更具挑战性的遮挡Re-ID问题,作者提出了两种策略来区分遮挡区域中的可见区域信息:(1)在特征构建阶段,模型应更加注意非遮挡部分。(2)在匹配阶段,作者将全局特征显式划分为多个部分,并且仅考虑待检索图像和图库图像之间的共同可见区域。
受这两种策略的驱动,作者提出以姿势关键点为引导信息,在图库和待检索图像之间比对提取的特征,并将其命名为“ Pose Guided Feature Alignment(PGFA)”方法。
与已有的工作相比,作者提出的PGFA具有两大优点:
首先,
PGFA不需要任何手动裁剪操作,效率更高。其次,检测到的关键点信息可以明确地指导模型关注非遮挡人的区域,并在特征构建和匹配阶段过滤遮挡区域的信息。在Occluded-DukeMTMC数据集上进行的实验表明,本文的方法在很大程度上优于已有的方法。
在两个部分Re-ID数据集和两个常用的整体基准测试集中,本文的方法效果不差。
本文有两大贡献:
(1)本文介绍了一个具有挑战性的大规模被遮挡的re-id数据集Occluded-DukeMTMC,它是迄今为止最大的专注于带遮挡Re-ID问题的数据集。(2)本文提出了PGFA,这是一种解决遮挡的Re-ID问题的有效方法。PGFA充分利用了检测到的人体关键点信息,并将其用来引导模型,在特征构建阶段关注非遮挡区域,并在匹配阶段对齐。
方法
网络架构
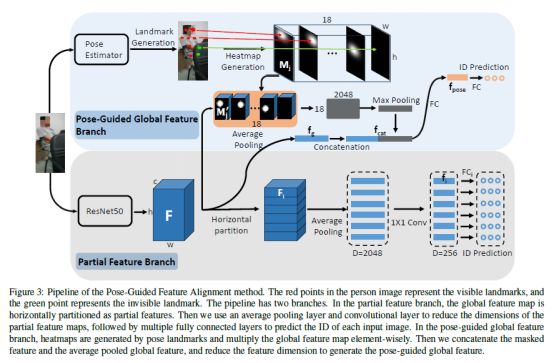
上图是作者提出的姿势引导特征对齐(PGFA)方法,该方法包括两个阶段,一个是表征构造阶段,另一个是匹配阶段。
表征构造阶段主要的结构包含两部分,一个是局部特征分支(Partial Feature Branch),另一个是姿态引导全局特征分支(Pose-Guided Global Feature Branch),这个分支是利用姿态估计去检测人体关键点并引导更健壮的表征结构。
匹配阶段如下图所示,待查询图像和图库图像之间的最终距离由两部分组成,一个是共享可见区域中局部特征的距离,另一个是姿态引导全局特征的距离。
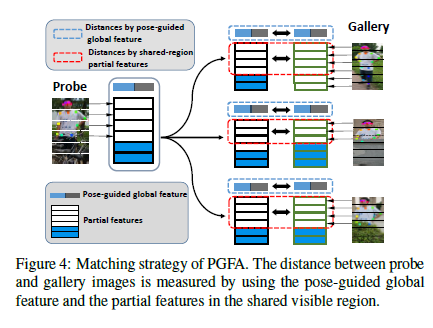
其中,每个部分具体的实现构造过程,作者在论文中有详细的叙述。
实验
实现细节
作者使用ResNet50作为骨干网络,并仅做了较小的修改:删除平均池化层和全连接层,将conv4_1的stride设置为1。并通过ImageNet预训练模型初始化模型。在实验设置中,输入图像的大小调整为384×128,并通过随机翻转和随机遮挡进行了增强。
将批次大小设置为32,将训练epoch设置为60。在Occluded-DukeMTMC,Market-1501和DukeMTMC-reID上,基本学习率初始化为0.1,并在40个epoch后衰减为0.01,衰减系数λ 为0.2。在Partial-REID和Partial-iLIDS上,基础学习速率初始化为0.02,衰减系数λ设置为0.9。
为了从遮挡的图像中检测出关键点,作者使用了在COCO数据集上经过预训练的AlphaPose。设置关键点的置信度得分大于0.2。
结果对比
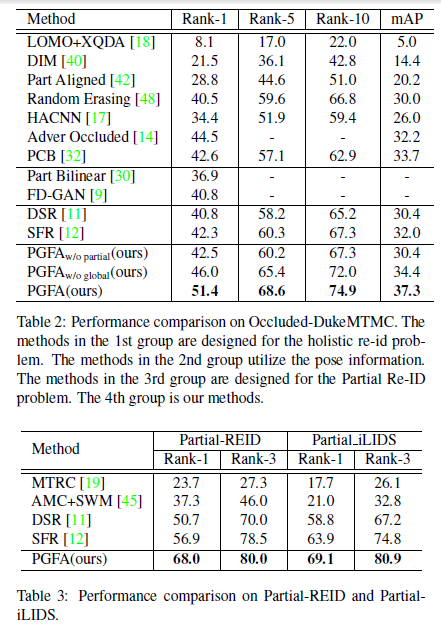
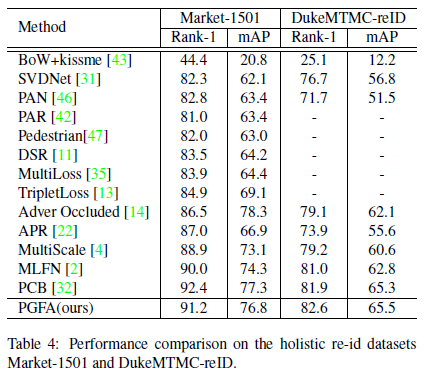
下图展示了在多个测试集上的对比效果。包括Occluded-DukeMTMC,Partial-REID,Partial-iLIDS,Market-1501,DukeMTMC-reID五个数据集。
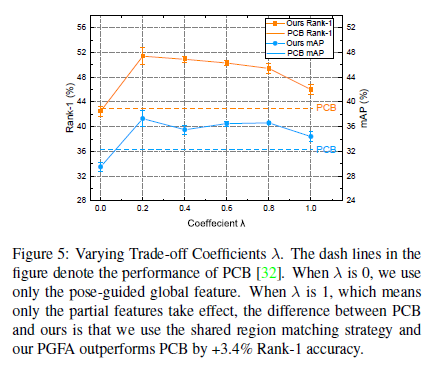
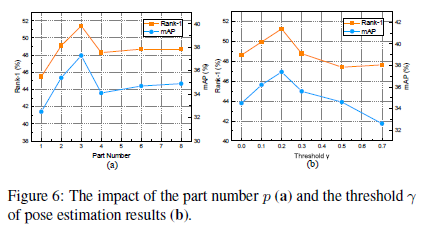
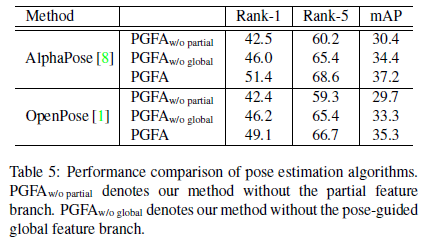
另外,作者为了验证本文提出的各个模块的有效性。做了一系列的消融实验(Ablation study)。如下所示,其中包括局部特征分支和姿态引导全局特征分支之间的平衡系数;局部特征的参数Part Number;筛选姿态关键点的阈值;以及使用不同姿态估计方法下的效果对比。
结论
在本文中,作者为解决带遮挡的ReID问题做出了贡献。首先,本文提出了PGFA方法,该方法在遮挡式Re-ID问题上优于现有方法。其次,为便于研究带遮挡的Re-ID问题,本文介绍了一个大型数据集Occluded-DukeMTMC。
(*本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
5 折票倒计时 1 天!
【END】

【进群了解最新免费公开课、技术沙龙信息】















 4738
4738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









