







整理 | 郑丽媛
出品 | CSDN(ID:CSDNnews)
在这场旷日持久的百模大战中,不仅各家大模型在极致内卷,大模型排行榜的评测标准也在不断迭代。
目前,Hugging Face 的开源大模型排行榜(Open LLM Leaderboard)是大模型领域最具权威性的榜单,它收录了全球上百个开源大模型——本周三,Hugging Face 宣布推出新版开源大模型排行榜(Open LLM Leaderboard):“成绩已趋于平稳,那就让排行榜再次陡峭起来吧!”
在这个更具挑战性的排行榜中,昨日 Hugging Face 的联合创始人兼首席执行官 Clem 在 X 上宣布:阿里最新开源的 Qwen2-72B 指令微调版(Qwen2-72B-Instruct),力压科技巨头 Meta 的 Llama-3 和法国著名大模型平台 Mistralai 的 Mixtral,成为新版开源模型排行榜第一名。
很高兴宣布全新的开源大模型排行榜。我们烧掉了 300 个 H100,重新对所有主流开源 LLM 进行了新的评估,如 MMLU-pro!
我们发现:
- Qwen 72B 仍是王者,中国的开源模型在整体上占主导地位;
- 以前的评估对最近的模型来说太容易了,就像用初中问题给高中生打分一样;
- 有迹象表明,AI 构建者开始过于关注主要评估,而忽略了模型在其他评估上的表现;
- 更大并不一定更聪明。

“彻底改变评估方式”,推出开源大模型排行榜 v2!
开源大模型排行榜诞生之前,Hugging Face 的 RLHF 团队经历了很艰难的一段时间:想要重现和比较几个已发布模型的结果,但发现这几乎是一项不可能完成的任务——很多论文和营销文中对模型的评分,都是在没有任何可重现代码的情况下给出的,难以复现。
因此,RLHF 团队决定以完全相同的设置(相同的问题、相同的提问顺序等)对参考模型进行评估,以收集完全可重复和可比较的结果——这就是 Hugging Face 开源大模型排行榜的诞生过程。
据 Hugging Face 统计,在过去 10 个月中超过 200 万人访问过这个榜单,每月有近 30 万人以不同方式在使用它,主要是为了:
(1)寻找最先进的开源模型。因为排行榜提供了可复现的分数,可以把市场宣传与实际表现区分开来。
(2)评估自己的工作。无论是预训练还是微调,用公开的方法与现有的最佳模型进行比较,以此赢得公众的认可。
但近一年时间下来,Hugging Face 发现随着模型性能不断提高,原来那套评测基准有点不够用了。首先这套基准已被过度使用,对许多模型来说没有太大难度,其次有部分模型就是用这套基准数据或与其非常相似的数据上训练出来的,评测结果可能不公平,最后有一些评测基准还存在错误需要纠正。
基于以上原因,Hugging Face 决定“彻底改变评估方式”,推出开源大模型排行榜 v2!

Qwen2-72B 第一名的位置仍然不变
根据 Hugging Face 博文介绍,新版开源大模型排行榜具有无污染、高质量数据集的新基准,使用可靠的度量标准并测量有趣的模型功能。为此,Hugging Face 决定用以下 6 个基准来涵盖测评任务:MMLU-Pro、GPQA、MUSR、MATH、IFEval 和 BBH。
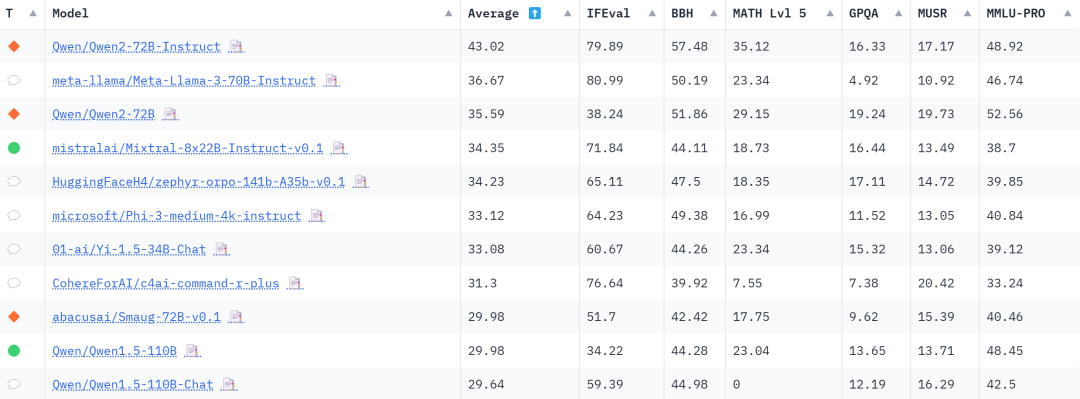
从新版开源大模型排行榜来看,尽管每个大模型的综合评分都因新评测基准有不同程度的降低,但 Qwen2-72B 第一名的位置仍然不变。
可以看到,Qwen2-72B-Instruct 这六项基准的平均分最高,其中 MATH 和 BBH 这两项评分第一:
-
MATH 是一份从多个来源收集的中高级竞赛题汇总,且 Hugging Face 只保留了最难的问题,用 Latex 来处理方程,用 Asymptote 来处理数字,要求输出必须符合非常特定的统一格式。在数学方面,得益于大规模且高质量的数据,Qwen2-72B-Instruct 的数学解题能力大幅提高,尽管测评难度提升也达到了 35.12 分,相较于 Qwen1.5-110B 提高了 12 分, 比知名开源模型 Llama3-70B 也高出了将近 12 分。
-
BBH 是 BigBench 数据集中 23 个挑战性任务的一个子集,这些任务包括:1)使用客观指标;2)难度大,因为语言模型的性能最初没有超过人类基准;3)包含足够多的样本以具有统计意义。它们包含多步骤算术和算法推理(理解布尔表达式、几何图形的 SVG 等)、语言理解(讽刺检测、名称消歧等)和一些世界知识。整体而言,BBH 上的表现与人类偏好密切相关——Qwen2-72B-Instruct 在方面达到了 57.48 的高分。
另外,在 GPQA 和 MMLU-Pro 这两项上,Qwen2-72B 也夺得第一,平均分位于总榜第三:
-
MMLU-Pro 是 MMLU 数据集的改进版,质量更高、难度更大。过去 MMLU 一直是多选知识的参考数据集,但最近研究表明该数据集既存在噪声(有些问题无法回答),又过于简单(由于模型能力的发展和污染的增加)。为此,Hugging Face 推出的 MMLU-Pro 为模型提供了 10 个选项(而不是原来的 4 个),要求对更多问题进行推理,并经过专家审核以减少噪声。Qwen2-72B 成为榜单中唯一一个 MMLU-Pro 评分超过 50 分的模型。
-
GPQA 是一个难度极高的知识数据集,其中问题由该领域的专家(生物学、物理学、化学等方面的博士级专家)设计,且经过多轮验证以确保难度和事实性,对于普通人来说很难回答。从模型普遍较低的整体得分来看,新版 GPQA 评测存在较高难度,Qwen2-72B 的 19.24 分目前已是最高分。
值得一提的是,除了 Qwen2-72B,榜单前列还有我们许多熟悉的中国模型:零一万物的 Yi-1.5-34B-Chat 处在第 7 名,Qwen1.5-110B 和 Qwen1.5-110B-Chat 也分别位于榜单第 10 名和第 11 名——正如 Hugging Face 联合创始人兼首席执行官 Clem 所说:“中国的开源模型在整体上占主导地位。”
参考链接:
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
https://huggingface.co/spaces/open-llm-leaderboard/blog

由 CSDN 和 Boolan 联合主办的「2024 全球软件研发技术大会(SDCon)」将于 7 月 4 -5 日在北京威斯汀酒店举行。
由 MIT 计算机与 AI 实验室(CSAIL)副主任、ACM Fellow Daniel Jackson 和世界著名软件架构大师、云原生和微服务领域技术先驱 Chris Richardson 领衔,华为、BAT、微软、字节跳动、京东等技术专家将齐聚一堂,共同探讨软件开发的最前沿趋势与技术实践。
大会官网:http://sdcon.com.cn/(可点击阅读原文直达)
















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









