







文 / Google AI 软件工程师 James Wexler
构建有效的机器学习 (ML) 系统需要提出许多问题。仅仅训练一个模型,然后放任不管,是远远不够的。而优秀的开发者就像侦探一样,总是不断探索,试图更好地理解自己的模型:数据点的变化对模型的预测结果有何影响?对于不同的群体,例如在历史上被边缘化的人群,模型的表现是否有所不同?用于测试模型的数据集的多样化程度如何?
要回答这些类型的问题并不容易。探索 “What-If” 场景通常意味着编写一次性的自定义代码来分析特定模型。此过程不仅效率低下,而且非编程人员很难参与塑造和改进 ML 模型的过程。Google AI PAIR 计划的一个重点就是让广大用户能够更轻松地检查、评估和调试 ML 系统。
我们发布了 What-If 工具(https://pair-code.github.io/what-if-tool/),这是开源 TensorBoard 网络应用的一个新功能,可以让用户在无需编写代码的情况下分析 ML 模型。在给定 TensorFlow 模型和数据集指针的前提下,What-If 工具可为模型结果探索提供交互式可视界面。
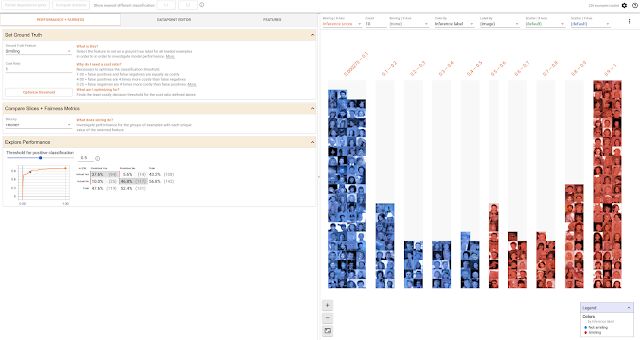
What-If 工具:展示了一组面部图片(共 250 张),以及微笑检测模型得出的结果
What-If 工具拥有各种功能,包括使用 Facets 自动可视化数据集、手动编辑数据集示例并查看相关更改的影响,以及自动生成局部依赖图(显示模型的预测结果如何随任何单个功能的更改而变化)。下面详细探索其中两项功能。

探索数据点上的 What-If 场景
▌反事实
只需点击一下按钮,即可将某个数据点与模型预测不同结果的最相似点进行比较。我们将这些点称为 “反事实”,它们可以清楚显示出模型的决策边界。或者,您也可以手动编辑一个数据点,然后探索模型预测的变化情况。在下方的屏幕截图中,我们将该工具用于二进制分类模型。此模型根据 UCI 人口普查数据集的公开人口普查数据来预测某个人的收入是否超过 5 万美元。这是 ML 研究人员常用的基准预测任务,特别适用于分析算法公平性的情况,我们很快会谈及这个话题。在这个案例中,对于选定的数据点,模型预测此人收入超过 5 万美元的置信度为 73%。该工具自动找出数据集中与此最相似的人(模型预测其收入少于 5 万美元),并将二者进行并排比较。在此案例中,只需对年龄和职业作出微小的改变,模型的预测就会出现大幅变化。
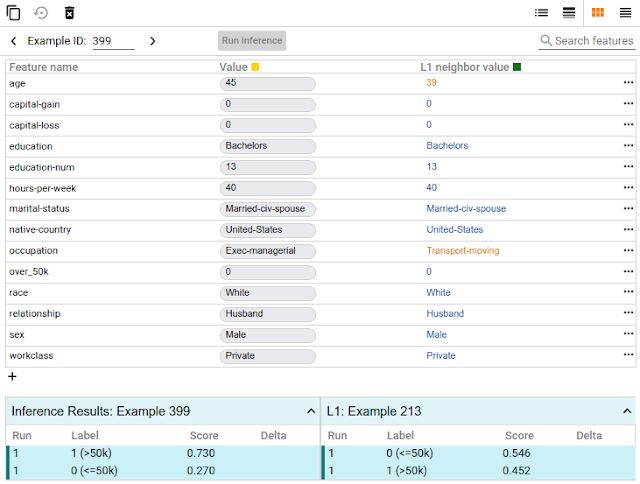
反事实对比
▌表现和算法公平性分析
您也可以探索不同分类阈值的影响,并考虑不同数值公平性标准等限制条件。下方的屏幕截图展示了微笑检测模型的结果,该模型使用开源 CelebA 数据集(由带注解的名人面部图像组成)进行训练。在下图中,我们根据头发是否为棕色,将数据集中的面部图像分成两组,并为其中每组绘制一条 ROC 曲线和预测结果的混淆矩阵,同时提供滑块,设定模型必须在达到一定的置信度,才会判定是否为微笑的面部图像。在此案例中,该工具自动为两组设置了置信度阈值,以优化模型,从而实现机会均等。
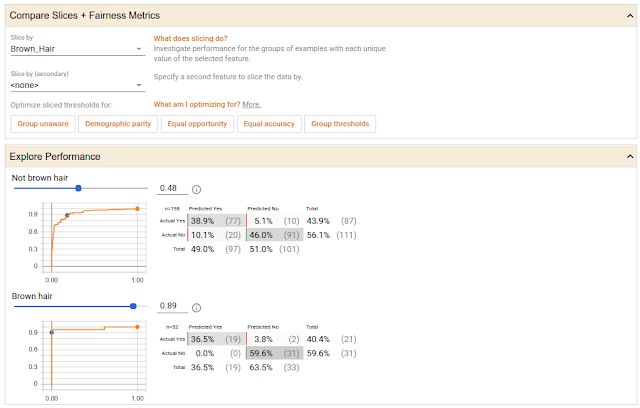
比较两组数据在微笑检测模型上的表现,并将其分类阈值设置为满足 “机会均等” 限制条件
▌演示
为了说明 What-If 工具的功能,我们发布了一组使用预训练模型的演示:
-
检测错误分类:这是一种多分类模型,通过对植物花朵的四次测量来预测植物种类。该工具有助于显示模型的决策边界和导致错误分类的原因。该模型使用 UCI 鸢尾花数据集进行训练。
-
评估二进制分类模型的公平性:这是上文提及的微笑检测图像分类模型。该工具有助于评估不同子组的算法公平性。在训练模型的过程中,为了展示该工具如何帮助揭示模型中的此类偏见,我们特意没有提供来自特定人群子集的任何示例。评估公平性需要谨慎考虑整体环境,但这是很有用的量化起点。
-
研究不同子组的模型表现:这是根据人口普查信息预测对象年龄的回归模型。该工具有助于展示模型在不同子组的相对表现,以及不同特点如何分别影响预测结果。该模型使用 UCI 人口普查数据集进行训练。
▌What-If 的实际应用
我们与 Google 内部团队一起测试了 What-If 工具的表现,从中看到这个工具的直接价值。有一个团队很快发现,他们的模型错误地忽略了数据集的一个整体特点,进而修复了之前并未发现的代码错误。另一个团队使用该工具将其示例按表现最佳到最差进行直观排列,进而发现表现不佳的模型示例类型有何模式。
我们希望 Google 内部和外部的人士都能使用此工具,以更好地理解 ML 模型,并开始评估其公平性。此外,由于此代码是开源的,我们欢迎大家为该工具的发展添砖加瓦。
▌致谢
What-If 是众人合作的成果,其成功离不开 Mahima Pushkarna 设计的用户体验,Jimbo Wilson 对 Facets 作出的更新,还有许多其他人提供的意见。我们想感谢测试此工具并提供宝贵反馈的 Google 团队,还要感谢 TensorBoard 团队的一切帮助。
【完】
2018 AI开发者大会
2018 AI开发者大会是一场由中美人工智能技术高手联袂打造的AI技术与产业的年度盛会!是一场以技术落地为导向的干货会议!大会设置了10场技术专题论坛,力邀15+硅谷实力讲师团和80+AI领军企业技术核心人物,多位一线经验大咖带你将AI从云端落地。
点击大会官网,查看嘉宾以及大会议题详细信息
















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









