







作者 | CV君
来源 | 我爱计算机视觉(ID:aicvml)
在计算机视觉领域,深度学习方法已全方位在各个方向获得突破,这从近几年CVPR 的论文即可看出。
但这往往需要大量的标注数据,比如最著明的ImageNet数据集,人工标注了100多万幅图像,尽管只是每幅图像打个标签,但也耗费了大量的人力物力。
说到标注这件事,打个标签其实还好,如果是针对图像分割任务,要对图像进行像素级标注,那标注的成本就太高了。跟专业的标注公司打过交道的朋友都知道,打标签、标关键点和标像素区域,所要付出的成本可大不同。
在医学影像领域,图像数据往往难以获取,而这又是一个对标注精度要求极高的领域。
最近几年,以GAN为代表的生成模型经常见诸报端,那能否用GAN破解标注数据不足的问题呢?
最近发现一篇论文Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation,来自德国国家肿瘤疾病中心等单位的几位作者,提出通过GAN对计算机合成的人体腹腔镜图像进行转换的方法,能够大批量得到与真实图像相似的合成图像,并在器官分割实验中,大大改进了真实图像的分割精度。非常值得一读。
下面是作者信息:

下图即为作者用计算机图形学方法合成的腹腔镜图像(A,下图第一列),和转换后的具有真实感的合成图像(Bsyn,下图第二列和第三列)。

CV君不是专业的医务人员,不过也可以看出转换后的图像的确比之前更具真实感。
方法介绍
作者使用Nvidia发布的MUNIT库进行图像转换,并进行了改进。
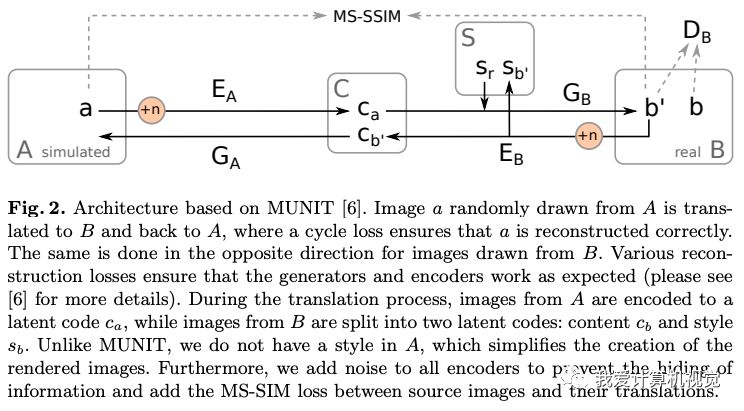
这是一个非成对数据的图像转换问题,作者使用一种循环loss,将A 域(模拟图)和B域(少部分真实图)进行循环的编码、生成、鉴别。
因为A 域内图像是计算机模拟出来的,所以天然的带有像素级标签。
作者的改进之处在于添加了MS-SSIM loss (Multi-Scale Structural Similarity,多尺度结构相似性损失函数),保证转换后图像结构相同。
另外,作者对编码器加入随机噪声,防止生成的纹理都完全相同。
下图为作者提供的训练数据的例子:

请注意,他们含有相似的目标,但很显然内容并不是匹配的,这样的训练数据是比较好找到的。
实验结果
作者用上述方法生成了10万幅图像,并在图像分割任务中验证了,这种合成数据对医学图像分割模型训练的价值。
下图对各种情况进行了分割结果比较:
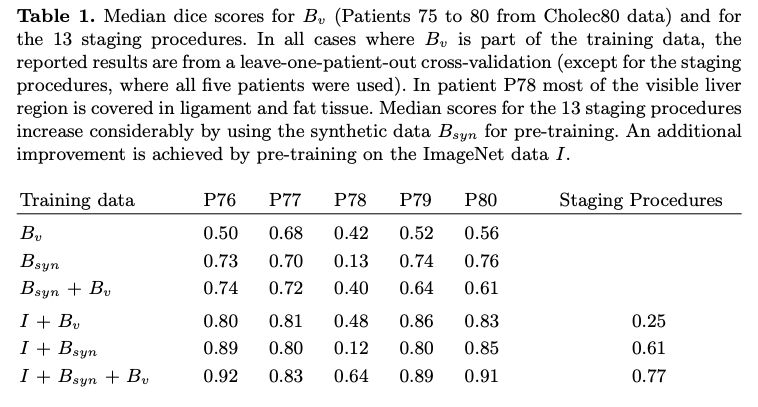
Bv是原有真实数据,Bsyn是合成数据,I代表模型在Imagenet进行了预训练。
可见,使用这种合成数据大幅改进了分割精度。而在Imagenet数据集上预训练的结果更好。这种方法对你有什么启发?欢迎留言。
(*本文为 AI科技大本营转载文章,转载请联系作者)
◆
精彩推荐
◆
“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
目前,大会盲订票限量发售中~扫码购票,领先一步!

推荐阅读
码农们的「血与泪」:新零售「全渠道中台」的前世今身
腾讯拥抱开源:首次公布开源路线图,技术研发向共享、复用和开源迈进
混合云发展之路:前景广阔,巨头混战
干货 | Python后台开发的高并发场景优化解决方案
5G 浪潮来袭!程序员在风口中有何机遇?
这次又坑多少人? 深度解析 Dash 钱包"关键"漏洞!
壕!两万多名腾讯员工获 51 万港元股票奖励
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢















 3777
3777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









