







最近在研究Python,想用Python写一个爬虫来爬数据。
爬虫有几个关键的地方,一个是防止如何递归地重复爬一个网址,一个就是页面信息的解析。
那么这里主要介绍一下如何通过bloom filter达到判断一个网址是否被爬过。
bloom filter的介绍refer:http://blog.csdn.net/jiaomeng/article/details/1495500
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
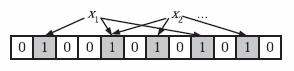
这个图我看的不是很明白,所以我自己画了一个图。

如果在Python下面使用bloom filter,可以导入一个包来使用。
http://sourceforge.net/projects/pybloom/















 2216
2216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









