






在上一篇讲述CEP的文章里,直接使用了自定义Source和Sink,我翻阅了一下以前的文章,似乎没有对这部分进行一个梳理,那么今天我们来就这上次的代码,来说说 Data Source 和 Data Sink吧。
从宏观上讲,flink的编程模型就可以概况成接入data source,然后进行数据转换操作,再讲处理结果sink出来。如下图所示。
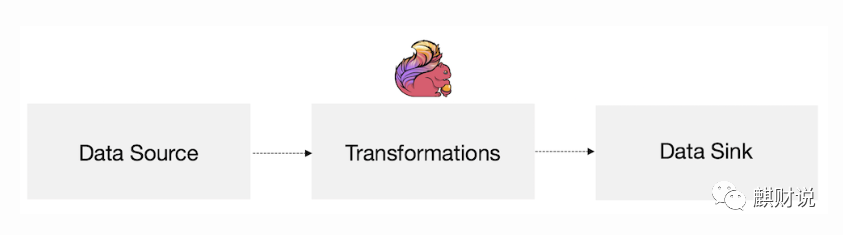
其实这可以形成一个完美的闭环,将处理结果sink到另外一个流里的时候,那么这个sink就又可以变成下一个flink job的source了。当然也可以选择sink到一个csv文件里,或是通过jdbc写到数据库里。
Data Source
我们还是以上一篇文章的空气质量例子为例,我们制造一个发生器,来向制造数据,然后将数据写入kafka。
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import wang.datahub.cep.event.AirQualityRecoder;
//import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer09;
import java.io.*;
import java.util.HashMap;
import java.util.Map;
public class WriteIntoKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Map prop = new HashMap();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("topic", "test1");
ParameterTool parameterTool = ParameterTool.fromMap(prop);
DataStream<AirQualityRecoder> messageStream = env.addSource(new SimpleGenerator());
DataStreamSink<AirQualityRecoder> airQualityVODataStreamSink = messageStream.addSink(new FlinkKafkaProducer010<>(parameterTool.getRequired("bootstrap.servers"),
parameterTool.getRequired("topic"),
new SimpleAirQualityRecoderSchema()));
messageStream.print();
env.execute("write to kafka !!!");
}
public static class SimpleGenerator implements SourceFunction<AirQualityRecoder>{
private static final long serialVersionUID = 1L;
boolean running = true;
@Override
public void run(SourceContext<AirQualityRecoder> ctx) throws Exception {
while(running) {
ctx.collect(AirQualityRecoder.createOne());
}
}
@Override
public void cancel() {
running = false;
}
}
public static class SimpleAirQualityRecoderSchema implements DeserializationSchema<AirQualityRecoder>, SerializationSchema<AirQualityRecoder>{
@Override
public AirQualityRecoder deserialize(byte[] message) throws IOException {
//System.out.println(new String(message));
ByteArrayInputStream bi = new ByteArrayInputStream(message);
ObjectInputStream oi = new ObjectInputStream(bi);
AirQualityRecoder obj = null;
try {
obj = (AirQualityRecoder)oi.readObject();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
bi.close();
oi.close();
return obj;
}
@Override
public boolean isEndOfStream(AirQualityRecoder nextElement) {
return false;
}
@Override
public byte[] serialize(AirQualityRecoder element) {
byte[] bytes = null;
try {
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream oo = new ObjectOutputStream(bo);
oo.writeObject(element);
bytes = bo.toByteArray();
bo.close();
oo.close();
} catch (IOException e) {
e.printStackTrace();
}
return bytes;
// return element.toCsvRec().getBytes();
}
@Override
public TypeInformation<AirQualityRecoder> getProducedType() {
return TypeInformation.of(new TypeHint<AirQualityRecoder>(){});
}
}
}
这里是完整代码,我们需要实现一个类,实现SourceFunction接口,重写run和cancel两个方法,run方法用于告诉上下文如何添加数据,而cancel方法则实现如何取消这个数据发生器。将这个类的实例addSource到当前环境实例上,就完成的数据的接入。这个例子,我们还使用了一个kafka connector提供的默认sink,将模拟数据写入kafka。
Data Sink
Sink部分会介绍两部分内容,1.Sink 到 JDBC 2.通过 Flink SQL Sink 到 CSV
Sink 到 JDBC
首先我们创建一个sink类,继承RichSinkFunction,需要实现其open,close,invoke三个方法,其中open和close用于初始化资源和释放资源,invoke用于实现具体的sink动作。
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import wang.datahub.cep.event.AirQualityRecoder;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class MySQLSink extends RichSinkFunction<AirQualityRecoder> {
PreparedStatement ps;
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = getConnection();
String sql = "insert into sinktable(id, city,airquality,emmit,et) values(?, ?, ?, ?, ?);";
ps = this.connection.prepareStatement(sql);
}
@Override
public void close() throws Exception {
super.close();
//关闭连接和释放资源
if (connection != null) {
connection.close();
}
if (ps != null) {
ps.close();
}
}
@Override
public void invoke(AirQualityRecoder value, Context context) throws Exception {
//组装数据,执行插入操作
ps.setString(1, value.getId());
ps.setString(2, value.getCity());
ps.setInt(3, value.getAirQuality());
ps.setDate(4,new java.sql.Date(value.getEmmit().getTime()));
ps.setDate(5,new java.sql.Date(value.getEt()));
ps.executeUpdate();
}
private static Connection getConnection() {
Connection con = null;
try {
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/flinksink?useUnicode=true&characterEncoding=UTF-8", "dafei1288", "dafei1288");
} catch (Exception e) {
e.printStackTrace();
}
return con;
}
}
构建一个测试类,直接读取kafka输入的数据,然后将其sink出来。
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import wang.datahub.cep.WriteIntoKafka;
import wang.datahub.cep.event.AirQualityRecoder;
import java.util.HashMap;
import java.util.Map;
public class SinkToMySQLApp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Map properties= new HashMap();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "test");
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
// properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("topic", "test1");
ParameterTool parameterTool = ParameterTool.fromMap(properties);
FlinkKafkaConsumer010 consumer010 = new FlinkKafkaConsumer010(
parameterTool.getRequired("topic"), new WriteIntoKafka.SimpleAirQualityRecoderSchema(), parameterTool.getProperties());
DataStream<AirQualityRecoder> aqrStream = env
.addSource(consumer010);
MySQLSink mSink = new MySQLSink();
aqrStream.addSink(mSink);
env.execute("write to mysql");
}
}
执行成功。
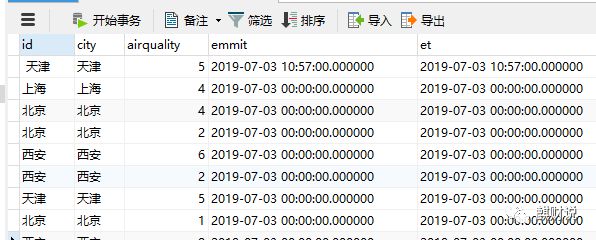
通过 Flink SQL Sink 到 CSV
这个sink比较特殊,是通过flink sql执行DML来,最终达到sink的目的,我们这个案例,使用了API提供的CsvTableSink。
这里我们将输入流的数据,注册成了AirQualityRecoder表,然后sink table ss以及其包含的字段名称和类型,,最后通过SQL语句
INSERT INTO ss SELECT id,city,airQuality,emmit,et FROM AirQualityRecoder
将数据写入csv文件中
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.table.api.StreamTableEnvironment;
import org.apache.flink.table.sinks.CsvTableSink;
import org.apache.flink.table.sinks.TableSink;
import wang.datahub.cep.WriteIntoKafka;
import wang.datahub.cep.event.AirQualityRecoder;
import java.util.HashMap;
import java.util.Map;
public class FlinkSQLSinkToMySQLApp {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.getTableEnvironment(env);
Map properties= new HashMap();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "test");
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
// properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("topic", "test1");
ParameterTool parameterTool = ParameterTool.fromMap(properties);
FlinkKafkaConsumer010 consumer010 = new FlinkKafkaConsumer010(
parameterTool.getRequired("topic"), new WriteIntoKafka.SimpleAirQualityRecoderSchema(), parameterTool.getProperties());
DataStream<AirQualityRecoder> aqrStream = env
.addSource(consumer010);
tableEnv.registerDataStreamInternal("AirQualityRecoder",aqrStream);
TableSink csvSink = new CsvTableSink("E:\\devlop\\sourcespace\\cept\\src\\test\\aa",",");
String[] fieldNames = {"id", "city","airQuality","emmit","et"};
TypeInformation[] fieldTypes = {Types.STRING, Types.STRING,Types.INT,Types.SQL_DATE,Types.LONG};
tableEnv.registerTableSink("ss", fieldNames, fieldTypes, csvSink);
tableEnv.sqlUpdate(
"INSERT INTO ss SELECT id,city,airQuality,emmit,et FROM AirQualityRecoder");
env.execute("write to mysql");
}
}
为了方便演示,我们将AirQualityRecoder里的emmit字段,变更为了java.sql.Date类型。下面是sink的结果。

好了,关于 Data Source 和 Data Sink 就先介绍到这里,欢迎大家和我交流。
















 2364
2364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











