









在线编辑器
链接如下:
截图如下:
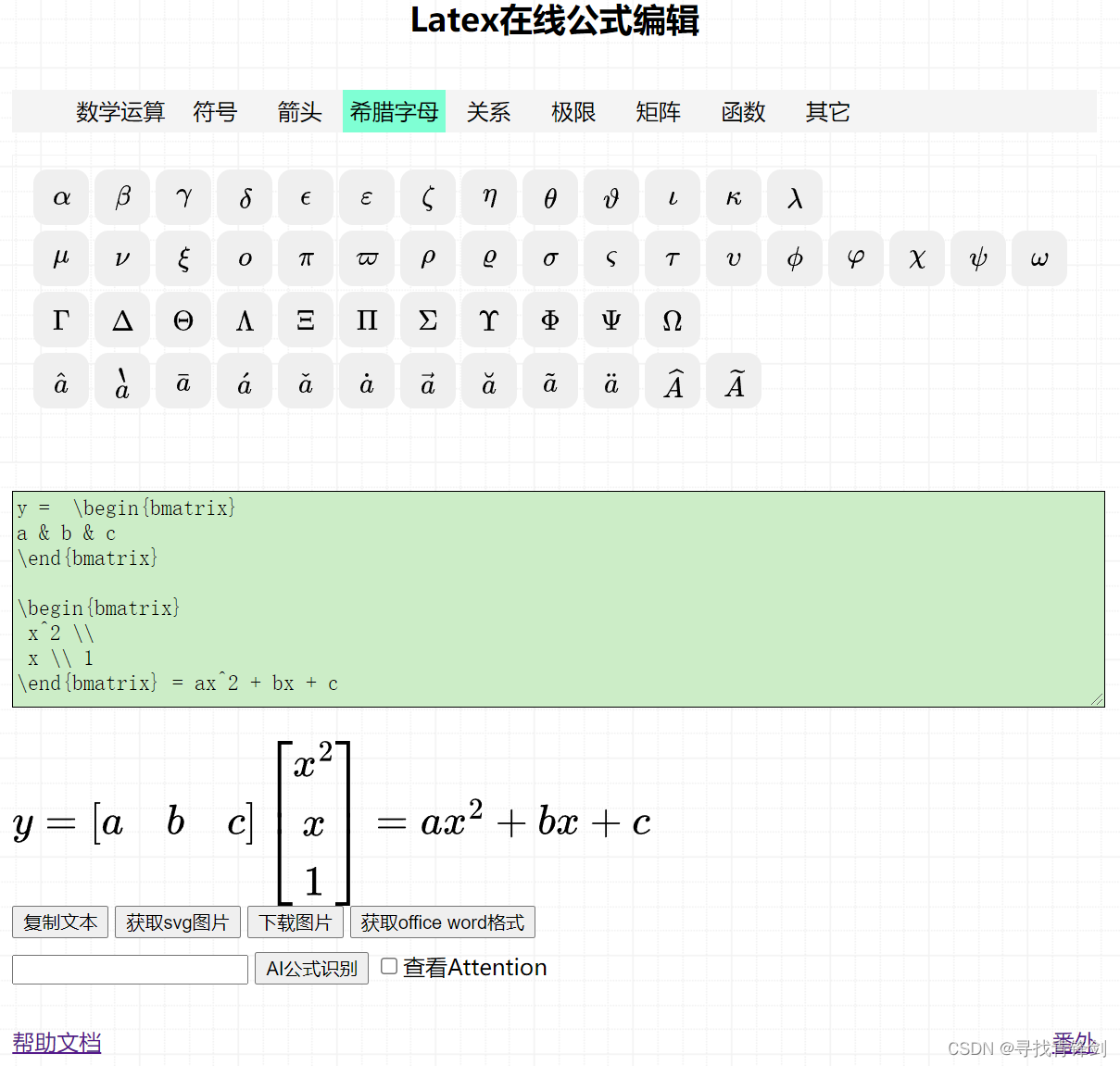
所有图标全是svg图片渲染,可以任意放大界面而不失真。
Flag
既然简单的界面已经做出来了,而且起的名字带有AI,想着怎么也不能对不起这两个字母,就个自己立了个flag,列了一个计划,真正用起AI,来帮助后来者,计划如下:
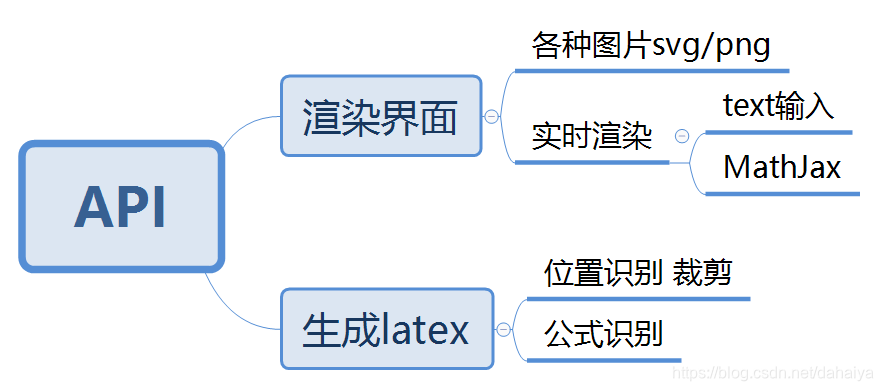
后期目标是,上传图片,然后识别返回生成的latex表达式;
但是能不能做到不太好说,由于资金有限,尤其最近显卡都炒到3倍了,本人现在自己台式机的显卡是GTX1060 6G,希望能支撑起模型的训练。
目标检测
初步计划用3个月的零碎时间,进行模型训练:1个月用于目标检测训练,2个月用于公式识别模型训练。
基本思路
-
要识别图片中的内容,第一步先要找到目标在哪里?因此准备从目标检测入手,采用yolo5方法。
yolo5的简介可以看这篇文章:YOLOv5学习总结(持续更新) -
训练模型需要数据,需要标记label等;
用人标记,耗时耗力耗费,故准备采用代码自动数据,这种方法无法解决手写之类的识别,先这么着吧。
模型调用
数据准备
图片类似这样的:

每张图片对应一个文件,文件内部是一行行的label,label的格式如下:
object_class x_center y_center width height
类别
初步定义的类别,如果不对再加:
| 类别 | Value | 例子 |
|---|---|---|
| 单行公式 | 0 | 文字 y = a x 2 + b x + c y=ax^2+bx+c y=ax2+bx+c文字 |
| 多行公式 | 1 | 文字 [ 1 2 3 4 ] \begin{bmatrix} 1 & 2\\ 3 & 4\end{bmatrix} [1324] 文字 |
初步结果
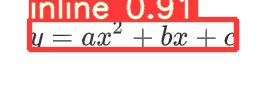


公式图片识别 生成Latex表达式
模型调用
识别模型的组成
- Encoder使用CNN模型,用于提取图片特征
- Decoder使用Sequence模型,用于将图片的Embedding转化为Latex表达式
- 需要一个Latex的字典表
- 图片处理:旋转、裁剪、翻转、模糊等
具体流程
- 数据集获取
- 从数据集中,总结字典,并在之后不断完善
- 图片加载,包括预处理(现在做)和数据增强(以后做)
- Encoder部分的代码
- Decoder部分的代码
- Loss部分
- inference部分(包括后处理)
- 服务部分
- beam search、rl(以后做)
未完,待更新…
想法来源
改用Markdown开始做笔记之后, 公式经常采用Latex书写,但是总是遇到一些公式不太会写,因此产生一个想法:
实现一个在线使用latex编辑公式的工具,工具提供帮助,不用记忆很多写法;利用端午节假期实现了一版。

















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









