





8 内存结构
这篇文章讨论了oracle 实例的内存的体系结构
这章主要包含下面的内容:
*oracle内存结构的引入
*系统全局域的概述
*程序全局域的概述
*专用的和共享的服务
*软件代码域
Oracle内存结构的引入
Oracle用内存来存储如下的信息:
*程序代码
*关于一个连接的信息,尽管这个连接当前不是处于活动状态
*在程序执行期间需要的信息(例如:正在被获取行记录的一个查询的当前状态)
*在oracle进程之间的被共享的和被交流的信息(例如:锁信息)
*被缓存的数据,这些数据也被永久地存储在外围的存储设备中(例如:数据块和重做日志入口)
与oracle相关的基本的存储结构包括:
*系统全局域(SGA):SGA被所有的服务器和后台的进程所共享;
*程序全局域(PGA):PGA对于每个服务器和后台进程来说是私有的,每个进程有一个PGA;
图8-1说明在这些内存结构之间的关系
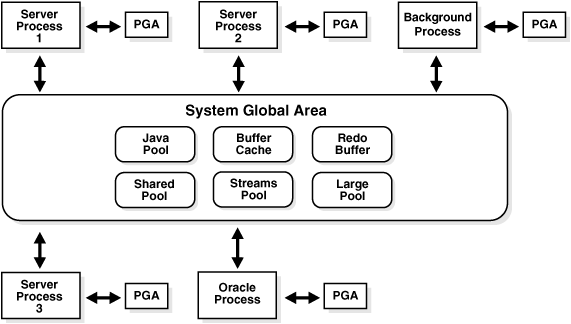
软件代码域是另一个基本的存储结构。
系统全局域的概述
一个系统全局域(SGA)是一组包含一个oracle数据库实例的数据和控制信息的共享内存结构。如果多个用户是并发地连接到同一个实例,然后在这个实例的系统全局域(SGA)中的数据在这些用户之间共享。同时,SGA有时候也被叫作共享全局域。
一个SGA和oracle进程构成一个oracle实例。当你启动一个实例时,oracle自动地为一个SGA分配内存,然后当你使实例关闭,操作系统要求归还内存。每个实例拥有属于自己的SGA。
SGA可读可写。所有连接到多线程的数据库实例的用户能够读取包含 SGA中的信息,并且几个进程在oracle在执行的期间将信息写进SGA中。
SGA包含下面的数据结构:
*数据库缓存
*重做日志缓存
*共享池
*JAVA池
*容量大的池
*流池
*数据字典缓存
*其他的混杂的信息
SGA的部分包含了关于数据库和实例的全面的信息,这些信息后台的进程是需要访问的;这个部分叫做固定的SGA。没有用户的数据存储在这个固定的SGA中。SGA也包含了进程之间交流的信息,比如:锁信息。
如果系统使用共享服务架构,然后请求和响应队列和一些PGA的内容存放在SGA中。
SGA_MAX_SIZE初始参数
SGA是由许多存储器组件组成的,这些存储器组件是一些存储池,这些存储池主要是为了满足特定类的存储分配请求。比如存储器组件是由共享池(用来分配SQL或者PL/SQL执行需要的内存),JAVA池(用来为JAVA对象和其他JAVA分配执行需要的空间)和缓存(用来缓存磁盘数据块)。所有的SGA组件是以粒度为单位分配和回收空间的。Oracle数据库为每个SGA组件是以内部的粒度的个数拉跟踪SGA的存储的。
粒度的大小是由整个SGA的大小所决定。在大多数平台上,如果整个SGA的大小小于1G,那么粒度的大小为4MB,如果整个SGA的大小大于1G,则粒度的大小为16MB。有些由于平台的因素也会有一些依赖发生。例如:在32位的windows系统,对于整个SGA的大小大于1G的其粒度的大小设置为8MB了。
Oracle数据库可以对有多少数据库的虚拟内存用于SGA的设置限制。数据库可以用最少的内存启动实例并且允许实例将更多的内存用于扩展SGA组件的内存分配,直到一个最大值,这个最大址由SGA_MAX_SIZE初始参数所决定。如果在初始参数文件或者在服务参数文件中的SGA_MAX_SIZE参数在数据库实例被初始化的时候或者在参数文件中明确地指定或者是默认的值,如果这个SGA_MAX_SIZE参数值小于为所有组件的存储大小之和,则数据库将忽视这个SGA_MAX_SIZE参数值的设置。
在大多数系统中为了理想的性能,整个的SGA的设置必须在真正的内存中是恰当的。如果SGA设置得不恰当,并且虚拟的内存也用来存储SGA中的一部分内容,那么整个数据库系统的性能会显著地下降。性能下降的原因是SGA一部分内容被操作系统分页了,操作系统将SGA的一部分内容写入到磁盘中并且SGA读取数据也要从磁盘中读取。在SGA中专用于共享域的内存的大小数量也会有性能影响。
SGA的大小被几个初始参数所决定。下面的参数对于SGA的大小有很大的影响:
参数 描述
DB_CACHE_SIZE 由标准数据块构成的缓冲存储器的大小
LOG_BUFFER 分配给重做日志的缓存的字节数
SHARE_POOL_SIZE 用于存储共享SQL和PL/SQL语句的区域的字节大小
LARGE_POOL_SIZE 大存储池的大小;默认为0
JAVA_POOL_SIZE JAVA池的大小
自动的共享内存管理
在先前的数据库版本中,需要一个数据库管理员(DBA)来通过设置许多初始参数来人工的定义不同的SGA组件的大小,这些需要人工设置的初始参数包括SHARE_POOL_SIZE,DB_CACHE_SIZE,JAVA_POOL_SIZE以及LARGE_POOL_SIZE参数。Oracle10g版本中使用了自动共享内存管理的特性来使SGA的内存管理简单化。在Oracle10g版本中,一个DBA能够利用SGA_TARGET初始参数来简单地定义一个实例需要的SGA的整个的数量,并且oracle数据库将为确保最有效的内存利用率自动地在各种子组件之间分配这个SGA内存。
当自动SGA内存管理被使用,不同的SGA组件的大小是灵活分配的,并且能够不需要额外的配置可以根据工作量的需要来调整SGA内存的分配,使之适应工作量的需要。数据库会根据需要在各种组件之间自动地分配可用内存,这样允许系统使SGA内存中所有可用的内存的利用最大化。
考虑一个人工的配置,这个人工配置是对于SGA来说可用的内存为1G,并且这个1G的内存被分配给下面的初始参数:
SHARE_POOL_SIZE=128M
DB_CACHE_SIZE=896M
如果一个应用软件需要试图从共享池中分配出128MB的内存,这样会报错是因为从共享池中可获取的空间的大小不足够应用软件要求分配的空间大小。尽管在缓存中是有可用空间的,但是对于共享池来说这些在缓存中的自由空间是不可访问的。你可能不得不手动重新给缓存分配大小并且这样共享池可以解决上面出现的问题从而可以正常工作。
带有自动SGA管理的oracle数据库,你可以简单的设置SGA_TARGE初始参数为1G。如果一个应用软件需要更多的共享池内存,共享池可以从缓存中的自由空间中获取些内存。
设置一个单独的参数极大地使数据库管理员的工作简单化。你只定义数据库实例可能用到的SGA内存的大小,对一些个别的SGA组件可以忽视。
自动的SGA管理可以不需要任何额外的资源或者手动的调优努力就可以增强工作量的工作性能。如果是手动设置SGA的配置,由于共享池中不足够的内存使地编译好的SQL语句会有频繁的共享池溢出的情况发生是可能的。这样会增加硬解析的频率,导致性能下降。当自动的SGA管理被使用,内部的优化算法会监控工作量的性能,当内部的算法确定需要增长共享池的大小时则会自动增长共享池的大小,这样的机制会减少需要解析的次数。
SGA_TARGET初始参数
SGA_TARGET初始参数反映SGA的总的大小并且包含下面组件的内存:
*固定的SGA以及oracle数据库实例需要的其他的内部的内存空间分配;
*日志缓存;
*共享池;
*JAVA池;
*高速缓存;
*保持缓存以及重复利用的缓存(如果定义的话);
*非标准数据块大小的高速缓存(如果定义的话);
*流池;
与早期的版本相比,早期的版本是将上面讲的第一条组件的内存加到配置的SGA内存参数的总和上,而现在的版本是将SGA_TARGET包含SGA全部的内存,新在的版本这样意义是很重大的。因此,SGA_TARGET参数可以对分配给数据库的共享池区域的大小有一个精确的控制。如果SGA_TARTGET在数据库实例启动的时候被设置为大于SGA_MAX_SIZE参数值的值,则SGA_MAX_SIZE参数值将会被抬升来适应SGA_TARGET参数的值的大小情况。
注意:不要动态的来设置SGA_TARGET参数值。因为这个值只能在数据库实例启动的时候才能被设置。
自动地管理SGA组件
当你为SGA_TARGET参数设置值时,数据库10g会自动地为最普通的需要被配置的组件设置内存大小,最普通的组件包括:
*共享池(分配给SQL和PL/SQL的执行的内存);
*JAVA池(分配给JAVA执行语句的内存);
*大池(分配给需要比较大的内存比如RMAN备份缓存);
*高速缓存;
*流池;
你不需要明确地设置这些组件中任何一个的内存大小。默认情况下上面这些组件的参数值将以0值出现。只要一个组件需要内存,这个组件可以通过申请然后数据库通过内部的优化机制的方式来将其他组件上的内存空间传输给该组件。内存的传输过程是透明的发生的,不需要用户的干涉。
每个被自动地设置大小的组件的性能被数据库实例所监控。实例采用内部的视图和统计来决定在SGA组件之间如何理想地分配内存。当工作量变化时,内存又重新分配来确保最优的性能。为了计算最优的内存分配情况,数据库用一个算法,这个算法将长期的和短期的组件需求内存大小的趋势考虑进去。
手动管理SGA组件。
SGA的一些组件它们的大小是不能够被自动地调整的。管理员这些组件如果被应用程序需要,那么数据库管理员需要明确的定义这些组件的大小。这些组件包括如下:
*保持/可重复、利用的高速缓存(被DB_KEEP_CACHE_SIZE和DB_RECYCLE_CACHE_SIZE参数所控制);
*对于非标准数据块的额外的高速缓存(被DB_nK_CACHE_SIZE,n=(2,3,8,16,32)所控制);
上面组件的大小通过数据库管理员设置相应的参数值来决定。这些值当然能够在任何时间被修改,可以通过企业管理器或者通过采用alter system语句的命令来设置。
手动设置组件的大小所消耗的内存空间减少了自动SGA调整时可利用的内存的大小。例如:在下面的配置中,
SGA_TARGET=256M
DB_8K_CACAHE_SIZE=32M
这样数据库实例只有剩下的224MB自由空间的大小用于自动SGA管理的内存自由空间的分配。
自动地优化值的持久性
如果你采用一个服务参数文件,oracle数据库将会记住实例的自动优化组件的内存大小。结果,系统在每次实例启动的时候不需要不再获悉工作量的特征。这个服务参数文件以在上一次实例的信息开始并且继续评估上次在关闭时留下的工作量。
增加粒度并且跟踪组件的大小
数据库管理员用alter system语句来修改与各个组件有关的初始参数值的方法来拓展SGA一个组件的利用。数据库将一个最新定义的大小设置为向约等于16MB的倍数靠拢,并且增加和删除粒度来满足目标的大小。数据库必须有足够的粒度来满足需求。只要当前SGA内存的数量小于SGA_MAX_SIZE参数值,数据库能够分配更多的粒度来使得SGA的大小达到SGA_MAX_SIZE参数值的大小。
当前被SGA的每个组件所用的粒度的大小可以在视图V$SGAINFO中可以查到。每个组件的大小和执行在每个组件之上的重新设置大小的操作的时间和类型可以查看V$SGA_DYNAMIC_COMPONENTS视图。数据库维护对SGA组件所做的重新设置大小的最近400次操作的一个循环的缓冲器。你可以查看在V$SGA_RESIZE_OPS视图上的循环的缓冲器。
注意:如果你定义一个组的大小不是粒度大小的倍数,则oracle将定义的这个值约等于最接近粒度的倍数。例如:如果粒度的大小是4MB,并且你定义DB_CACHE_SIZE为10MB,你实际将分配12MB给DB_CACHE_SIZE。
数据库高速缓存
数据库高速缓存是SGA的一部分,这部分主要存储了从数据文件中读取的数据块的复制品。所有并发的连接到该数据库实例的用户将共享访问数据库高速缓存区。
数据高速缓存区和共享的SQL缓冲器被逻辑地分割成为多个集合。这个分割为多个集合的组织减少了在多处理器系统的资源竞争。
数据库高速缓存的组织
在高速缓存器上的缓冲器是以两种列表的方式组织的:写列表和最近最少使用(LRU)的列表。写列表存放的是脏数据,脏数据即是指已经被修改的数据但是还没有写进磁盘的数据。LRU列表存放了自由缓冲器,被牵制的缓冲器以及还没有移动到写列表的脏缓冲器。自由
缓冲器不包含任何有用的数据并且是可用的缓冲器。被牵制的缓冲器是当前正被访问的。
当一个数据库的进程访问一个缓冲器时,进程移动缓冲器到LRU列表的最近最多使用(MRU)端上。当越来越多的缓冲器被移动到LRU列表上的MRU端上,脏缓冲器被推移动LRU列表的LRU端上。
每次当一个oracle用户进程需要一个特定的数据,这个进程在数据库高速缓存中查询该数据。如果这个进程在高速缓存中找到需要的数据(叫缓存击中),该进程能够从内存中直接读取数据。如果该进程不能够在缓存中找到需要的数据(叫缓存未击中),该进程必须在访问数据之前将磁盘上数据文件的特定的数据块复制到高速缓存中。通过缓存击中访问数据比通过缓存不击中访问数据要快很多。
在读数据块到高速缓存中之前,进程必须要在缓存中找到一个自由的高速缓存器。当进程找到自由的缓存器时,该进程从磁盘读取特定的数据块到铪存中并且移动该缓存器到LRU列表的MRU端上。
如果一个oracle用户进程找到高速缓存的极限界限值并且没有找到一个自由的缓存器,那么该进程停止对LRU列表的查询,并且通知DBW0后台进程去写一些存放脏数据的缓存器中的脏数据到磁盘中。
LRU算法和全表扫描
当用户进程正在执行一个全表扫描,该进程从磁盘中读取表的数据块存放到高速缓存中,并且将这些是数据块放到LRU列表的LRU端(是MRU的对立端)。这是因为全表扫描对这些读入的数据块只是暂时的需要,所以这些数据块需要被快速地从高速缓存中移走来存放被使用频繁的数据块。
你可以控制基于表紧挨着表的表扫描所包含的数据块的默认行为。为了在全表扫描时指定该表的数据块被放置在LRU列表的MRU端,所以在当创建表和修改表或者簇时用cache语句。你可以为小的查询表或者大的静态历史表指定这种行为来避免对表的并发访问的冲突。
数据库高速缓存的大小
Oracle在数据库中支持多样的数据块。对于系统表空间是采用的是标准的数据块。你可以通过设置DB_BLOCK_SIZE初始参数来指定标准的数据块的大小。合理的值的范围是2K到32K。
随意的,你也可以为两个额外的缓存池的设置大小,通过设置DB_KEEP_CACHE_SIZE和DB_RECYCLE_CACHE_SIZE。上面的三个参数是相互独立的。
非标准的数据块的大小被定义通过下面的参数:
DB_2K_CACHE_SIZE
DB_4K_CACHE_SIZE
DB_8K_CACHE_SIZE
DB_16K_CACHE_SIZE
DB_32K_CACHE_SIZE
每个参数为缓存器的大小设置相应的数据块大小。
设置数据块和缓存器大小的例子
DB_BLOCK_SIZE=4096
DB_CACHE_SIZE=1024M
DB_2K_CACHE_SIZE=256M
DB_8K_CACHE_SIZE=512M
在前面的例子中,参数DB_BLOCK_SIZE设置了数据库标准数据块的大小为4K。标准数据块的缓存器的大小为1024M。除此之外,2K和8K缓存器也被用参数DB_2K_CACHE_SIZE和参数DB_8K_CACHE_SIZE设置了并且值各自为256M和512M。
注意:DB_nK_CACHE_SIZE参数不能够被用来设置标准数据块的缓存器的大小。DB_BLOCK_SIZE的值是nK,这样设置DB_nK_CACHE_SIZE的值是非法的。标准数据块的缓存器的大小总是由DB_BLOCK_SIZE参数值来决定的。
缓存器有大小限制,所有并不是磁盘上的所有数据都能够适合存放在缓存器中。当缓存已经满的时候,紧接着的缓存不击中使得oracle将已经存放在该缓存中的脏数据写到磁盘中来为新的数据留有存放的空间。(如果一个缓存器存放的不是脏数据,则在一个新的数据块能够被读进缓存中之前这个缓存器不需要将脏数据写进磁盘。)紧接着对那些已经被写进磁盘的任何数据的访问导致额外的缓存不击中情况的发生。
缓存器的大影响数据申请导致缓存击中情况发生的可能性。如果缓存很大,那么该缓存存放那些被申请的数据的可能性比较的大。增长缓存的大小将增长数据申请缓存击中的比例。
你可以在数据库实例启动的时候改变缓存器的大小,不需要关闭数据库。设置缓存的大小可以通过alter system语句。获取更多的信息,见“SGA的内存的控制“。
用固定的视图v$buffer_pool及任何未完成的重新设置大小的操作。
多缓存池
你可以采用单独的高速缓存池,这些缓存池或者是存放数据的高速缓存器或者是这些缓存器在利用数据块之后立即为新数据分配缓存器的缓存器,采用这些缓存池来配置数据库的高速缓存。特定的对象(表,簇,索引和分区)能够被分配给适当的缓存池来控制这些对象的数据块的溢出缓存的方式。
*KEEP缓存池保留对象的数据在内存中;
*RECYCLE缓存池是排除一些在内存中不用的数据块;
*DEFAULT缓存池包含那些没有分配给任何缓存池的对象的数据块以及那些明确分配给DEFAULT缓存池的对象。
那些配置KEEP和RECYCLE缓存池的初始参数是DB_KEEP_CACHE_SIZE和DB_RECYCLE_CACHE_SIZE。
注意:多缓存池是对于标准的数据块大小是可用的。非标准数据块大小的缓存有单独的DEFAULT池。
重做日志缓存
重做日志缓存是一个SGA中可循环利用的缓存,这个缓存用来记录对数据库所做的一些变化信息。这些信息被存储在重做项中。重做项包含一些必要的重构,重做以及通过insert,update,delete,create,alter或者drop操作的对数据库所做的的变化的信息。有必要的话,重做项也被用来数据库恢复。
数据库进程从用户的内存空间中将重做项复制了一份到SGA中的重做日志缓存中。重做项占用了缓存中的连续的有顺序的空间。后台进程LGWR将重做日志缓存写到磁盘上的重做日志文件中。
初始参数LOG_BUFFER决定重做日志缓存的大小。一般的,该参数的值大点会减少日志文件的I/O交互,特别是如果是对一些长并且多的事务。
共享池
SGA的共享池部分包含了库缓存,字典缓存,以及存放并发执行的消息的缓存,和控制结构。
共享池的总的大小被SHARE_POOL_SIZE初始参数所决定。这个参数在32位平台上的默认值是8MB,在64位上的默认值是64MB。增长了这个参数的值即增长了为这个共享池保留的内存的的大小。
库缓存
库缓存中包括共享的SQL语句,私人的SQL区域(假设是在一个共享服务配置),PL/SQL存储过程和包,以及控制结构比如锁和库缓存句柄。
共享SQL区域对于所有的用户来说都是可访问的,所以库缓存被包含在SGA中的共享池中。
共享SQL区域和私人SQL区域
Oracle采用一个共享的SQL区域和一个私人的SQL区域展现每个执行的SQL语句。当两个用户正在执行同样的SQL语句时,oracle识别出来然后对于这些用户重用共享的SQL区域。但是,每个用户必须有对语句的私人SQL区域有一个单独的复制备份。
一个共享SQL包含所给的SQL语句的解析树和执行计划。Oracle通过对一些执行多次的语句采用一个共享SQL区域来节省内存,这种情况经常发生在当许多用户执行同样的应用程序。
在当一个新的SQL语句被解析时,Oracle从共享池中分配内存来存储该被解析后的语句到共享的区域中。这个内存的大小依赖于被解析的语句的复杂性。如果共享池中的空间全部被分配,oracle能够采用一个改进的LRU算法从共享池中分离已经被分配的项直到对于这个新的语句的共享区域来说有足够的空间容纳。如果oracle分离一个共享SQL区域,相关的SQL语句必须被重新解析并且在下次执行时重新分配另一个共享的SQL区域。
PL/SQL程序单元和共享池
Oracle处理PL/SQL程序单元(存储过程,函数,包,匿名块,以及数据库触发器)与处理单个的SQL语句类似。Oracle分配一个共享区域来容纳一个程序单元被解析和被编译的形式。Oracle分配一个私人的缓存来容纳对于在那些执行其程序单元连接上的特殊的值。这些特殊的值包括本地的,全局的和包的变量(也被认为是包的实例化)以及执行SQL语句的缓存器。如果执行同样的程序单元有多个用户,然后一个单独的,共享的区域被所有用户所共用,同时每个用户也维护他们自己的私人的SQL区域,他们自己的私人区域容纳他们自己的连接上的特殊的值。
每个包含在PL/SQL程序单元中的SQL语句都是像上面描述的那样进行。尽管这些SQL语句来源于PL/SQL程序单元,但是这些SQL语句采用共享的区域来容纳它们共有的被解析的称述并且也采用对每个连接特定的语句也采用一个私人的区域。
字典缓存
字典缓存是一个包含关于数据库参考信息的数据库表和视图,以及数据库结构和数据库的所有用户信息的一个集合。Oracle在SQL语句解析阶段频繁访问数据字典。这个访问对于oracle数据库的连续操作来说是基本的。
数据字典被oracle访问如此频繁以至在内存中两个特定的位置被指定来容纳数据字典。一个区域被称为数据字典缓存,也被称为行缓存是因为该数据字典缓存是将行作为数据来存储的来取代缓存存储(缓存存储是容纳整个的数据块)。在内存中的另一个容纳字典数据的区域是库缓存。所有的oracle用户进程为了访问数据字典信息共享这两个缓存。
在共享池中内存的分配和重用
一般,在共享池中的任何一项(共享的SQL区域或者字典行)保留着直到共享池根据一个改进的LRU算法被刷新。如果新的项在共享池中需要被分配一些空间,那么共享池中的那些不被用于经常用的项的内存将被释放。一个改进的LRU算法允许那些被许多连接所使用的共享项只要它们有用就被保留在内存中,尽管最初创建这个共享池中的项的进程已经终止结束。结果,与多用户oracle系统相关的该SQL语句的处理和消耗被降为最小。
当一个SQL语句因为执行被提交给oracle数据库,oracle自动地执行下面的内存分配步骤:
oracle首先需要检查共享池中是否已经有一个共享SQL区域中已经存在一个相同的语句。如果已经存在,那么那个共享SQL区域被用来执行后来的新的语句的实例。相反的话,如果没有该语句的共享SQL区域,oracle然后在共享池中分配一个新的共享区域。在任意一中情况,用户的私人SQL区域是和那个包含该语句的共享的SQL区域是有联系的。
注意:
一个共享的SQL区域可以被从共享池中刷新掉,尽管这个共享的SQL区域对应一个打开的游标,这个游标有一段时间没有被使用。如果这个打开的游标后来被使用来执行它的语句,oracle重新解析这个语句,并且一个新的共享SQL区域也在共享池中重新分配。
oracle代表特定的连接分配一个私人的SQL区域。这个私人的SQL区域的位置依赖于这个会话所建立的连接的种类。
Oracle在下面的环境下也将一个共享的SQL区域从共享池中刷新掉。
*当一个ANALYZE语句被用来更新或者删除一张表,一个簇或者索引的统计信息的时候,所有的那些包含引用该被分析的用户对象的语句的共享SQL区域被从共享池中冲刷掉。在下次该被冲刷掉的语句被执行的时候,该语句在一个新的共享SQL区域中被解析来反映该对象的新的统计信息;
*如果一个对象在一个SQL语句中被引用并且那儿歌对象之后以任何的方式被修改,该共享的SQL区域被设置为非法的,并且这个语句在下次被执行的时候被重新解析;
*如果你改变一个数据库的全局数据名称,所有的信息将被从共享池中刷新掉;
*管理员能够手动的刷新在共享池中的所有信息来评定性能(考虑共享池,而不是数据缓存器),这个评定性能可以不通过关闭数据库实例而是在数据库实例启动之后被期待有的性能效果。手动的刷新可以用语句alter system flush shared_pool。
大池
数据库管理员可以配置一个可选择的区域叫大池来为下面的几种情况分配内存:
*共享服务器和oracle的XA接口(用于一个或者多个是数据库之间的事务);
*I/O服务进程;
*oracle备份和恢复操作;
通过为共享服务器,oracle的XA接口,并行查询缓存器从大池中分配会话内存,oracle可以共享池主要来缓存共享SQL语句这样避免了由于共享池的减少所引起的性能消耗。
另外,为oracle数据库备份和恢复,I/O服务进程以及为并行缓存分配的内存是以上百千的字节来分配内存的。这个大池能够比共享池更好的满足如此大的内存分配需求。
大池没有一个LRU列表,它不同于共享池中的保留空间,共享池的保留空间是和共享池中的内存分配一样采用相同的LRU列表来分配内存的。
JAVA池
JAVA池是用在服务器内存中专门用在JAVA虚拟机上的所有会话中特定的JAVA代码和数据。JAVA池的内存以不同的方式来使用,依赖于oracle是以哪种运行模式在运行。
JAVA池顾问统计提供关于为JAVA所用的库缓存的信息,并且预知JAVA池的大小方面的变化是如何影响解析比率的。JAVA池顾问在当statistics_level参数被设置为typical或者更高时被内部启动。这些统计在当顾问被关闭时会重新设置。
流池
在单独的数据库,将SGA中的一个池分配给流池的内存被定义为流的内存。为了配置流池,通过初始参数STREAMS_POOL_SIZE的大小来设置。如果一个流池没有被定义,oracle会在当流被第一次使用的时候自动的创建流池。
如果SGA_TARGET被设置,然后流池的SGA内存来源于SGA的全局池。如果SGA_TARGET没有被设置,然后流池的SGA内存的分配是从高速缓存中调动过来使用。这种调动只发生在流被第一次使用之后。调动的空间数量是共享池的10%的比率。
SGA内存使用的控制
动态的SGA提供对oracle对物理内存的的使用的增加和减少的外部控制。和动态的缓存高速缓存,共享池和大池一起,SGA允许下面的情况发生:
*SGA可以依据数据库管理员的陈述增长,直到操作系统定义的最大值和SGA_MAX_SIZE参数定义的值。
*SGA可以依据数据库管理员的陈述要求减少,直到oracle所描述的最小值,通常是操作系统的限制是首选的限制。
*高速缓存和SGA池可以根据一些内部的,oracle操纵的原则来增长和减少。
SGA的其他初始参数
你可以用一些初始参数来控制SGA是如何用内存的。
物理内存
LOCK_SGA参数将SGA的内存锁在物理内存中
SGA起始地址
SHARED_MEMORY_ADDRESS和HI_SHARED_MEMORY_ADDRESS参数定义的启动时的SGA初始地址。这些参数很少使用。64围平台,HI_SHARED_MEMORY_ADDRESS参数定义了64位地址的高32位。
可扩展的高速缓存机制
USE_INDIRECT_DATA_BUFFERS参数使得32位平台的高速缓存机制可支持超过4G物理内存.
但是,动态的高速缓存器需要每个缓存器都有一个有效的虚拟地址.这是因为分配的单元-粒度,是能够被虚拟地址识别.因为这个原因,可扩展的缓存特征在当前版本中是不可用的.
程序全局域的概述
程序全局域是一个为服务进程包含数据和控制信息的内存区域.当服务进程启动时,PGA是一个被oracle所创建的一个非共享的内存区域.访问这个PGA是一个与该服务进程是相斥的,并且只能有oracle代码代表服务进程来对PGA进程读写。和一个oracle数据库实例有关的分配给每个服务进程的PGA的总的内存数量也被归诸于被数据库实例分配给聚合的PGA内存中。
PGA的内容
PGA的内容根据数据库实例是否是运行在共享的服务选项来变化。发起每个SQL语句的每个会话都有一个私人的SQL区域。提交同样的SQL语句的每个用户也拥有属于他们自己的私人SQL区域但是使用的时候是用的是一个单独的在共享区域的SQL语句.因此,许多私人的SQL区域是和在共享区域中的同样的SQL语句是有联系的.
一个游标的私人SQL区域自身被分成两个区域,这两个区域的范围是不同的:
*持久域,它包含,例如:绑定信息.只有当游标别关闭时,该持久域才会被释放;
*运行域,该域只有在执行被结束时才能被释放。
oracle在一个执行请求的第一步创建运行域。对于插入,更新以及删除语句,oracle在该语句被运行之后才释放运行域。对于查询,oracle只有当在所有查询出来的行被取完之后或者在查询被取消之后才释放运行域。
私人的SQL区域的位置上是依据对该会话所建立的连接的种类。如果会话是通过独立的服务器进行连接,那么私人的SQL区域被放置在该服务进程的PGA中。但是,如果一个会话是通过共享服务的方式连接的,那么私人的SQL语句区域的部分内容被保存在SGA中。
游标和SQL区域
一个oracle预编译程序或者OCI程序的应用开发者可以明确的打开游标或者句柄来指定私人的SQL区域,然后在该程序在执行的整个过程中用这些游标或者句柄作为一个已命名的资源。对于一些SQL语句oracle声明的隐式的递归的游标也用共享的SQL区域。
私人的SQL区域的管理是该用户进程的责任。私人SQL区域的分配和收回很大程度上依赖于你所用的是哪种应用工具,尽管一个用户进程能够分配的私人的SQL区域总是被初始参数OPEN_CURSORS的值所限制。这个参数的默认的值是50。
一个私人的SQL区域继续存在直到相应的游标被关闭或者该语句的句柄被释放,该私人的SQL区域才会被释放。尽管oracle在该语句被执行完成之后释放了执行区域,但是持久区域仍然在保持等待状态。应用开发者关闭所有不再会被用的游标来释放持久区域,这样减少了应用软件的使用者对内存的数量。
会话内存
会话内存是一个分配给容纳一个会话中的变量和一些和会话相关的信息的内存。对于共享服务器来说,会话内存是共享的而不是私人的。
SQL工作区域
对于复杂的查询(例如:决定支持的查询),执行区域的大部分是专门分配给那些消耗内存比较厉害的操作的工作区域。比如下面的情况:
*基于排序的操作;
*哈希连表;
*bitmap合并;
*bitmap创建;
例如:一个排序操作利用一个工作区域来执行行记录集合的内存排序操作。同样,一个哈希连表操作利用一个工作区域(也叫哈希区域)并依据左边的输入来创建哈希表。如果被这两个操作符处理的数据量不适合放在工作区域,然后这些输入的数据将被更小点的一块一块的数据块。这样就可以允许一些数据块放在内存中处理同时其他的数据块被溢出存放到临时的磁盘中等之后再做处理。尽管bitmap操作符当相关的工作区域是很小而不能放下bitmap操作符时,bitmap操作符并不会溢出到磁盘里面。bitmap操作符的复杂性是相反地是与他们的工作区域的大小是有比例的。因此,这些操作符如果它们的工作区域大的话将执行的更快。
工作区域的大小能够被控制和调优。一般地,大点的数据库区域能够以更高的内存消耗成本来改进一个特殊的操作执行性能。理想情况下,一个工作区域的大小能够足够的大以至能够容纳输入的数据和该工作区域相关的SQL操作符分配的辅助内存结构。如果不能,响应时间将会增加,因为输入数据的部分必须被溢出到临时的磁盘中。在后一个情况下,工作区域的大小如果与输入数据的大小相比较远远的很小,多次数据块的传递必须要执行。这样的话就动态地增加了该操作的响应时间。
独立模式下的PGA的内存管理
你可以自动并且全局的管理SQK工作区域的大小。数据库管理员简单地需要通过定义初始参数PGA_AGGREGATE_TARGET的值来定义oracle实例专门分配给PGA的内存总的大小。定义的数量是对于oracle实例的一个全局的目标(例如:2G),并且oracle努力去确保通过所有的数据库服务进程所分配的PGA内存的总的大小不能超过这个目标。
注意:在早期的版本中,数据库管理员通过设置下面的参数来控制SQL工作区域的最大的 大小:SORT_AREA_SIZE,HASH_AREA_SIZE,BITMAP_MERGE_AREA和CREATE_BITMAP_AREA_SIZE。设置这些参数上一困难的,因为最大的工作区域大小在观念上是来源于数据输入的大小和在系统中的所有的活跃的工作区域总的大小。这两个因素是随着一个工作区域到另一个工作区域或者从一个时间到另一个时间的变化而不停的变化的。因此,变化的*_AREA_SIZE参数在最佳环境下很难去优化。
采用PGA_AGGREGATE_TARGET参数,对所有的独立的会话的工作区域的大小设置是自动的并且所有的*_AREA_SIZE参数对于这些会话来说是忽略的。在任何时候,实例上对于活跃的工作区
域可用的PGA内存的总的数量是自动有参数PGA_AGGREGATE_SIZE得来的。这个数量是用PGA_AGGREGATE_SIZE的值减去系统的其他组件分配的PGA内存的的大小(例如:被会话分配的PGA的大小)。作为结果的PGA内存的大小然后根据特定的内存需求分派给单独的活跃的工作区域。
注意:初始参数WORKING_SIZE_POLICY是一个会话级的并且也是系统级的参数,这个参数可以设置为两个值:MANUAL或者AUTO。默认的是AUTO。数据库管理员可以设置PGA_AGGREGATE_TARGET参数,并且当时可以将内存管理的模式在auto或者manual管理模式之间转换。
有一些固定的视图和列提供PGA内存的使用统计信息。当PGA_AGGREGATE_TARGET被设置时,这些统计信息的大部分才被激活。
*工作区域内存的分配和使用的统计可以在下面的动态性能视图中被查看:
V$SYSSTAT
V$SESSTAT
V$PGASTAT
V$SQL_WORKAREA
V$SQL_WORKAREA_ACTIVE
*在视图V$PROCESS中的下面三列报道了被oracle数据库实例分配和使用的PGA的内存:
PGA_USED_MEM
PGA_ALLOCATED_MEM
PGA_MAX_MEM
注意:自动的PGA内存管理模式应用于被独立的和共享的oracle数据库服务器所分配的工作区域。
独立的和共享的服务器
在一些特定环境下,内存分配依赖系统是否采用独立的服务器结构还是共享的服务器结构。表8-1显示了两种服务器的区别:
表8-1 在独立和共享的服务器之间的分配内存的不同之处:
内存区域 独立服务器 共享服务器
会话内存的种类 私人 共享
持久区域的位置 PGA SGA
对于查询语句的部分执行区域的位置 PGA PGA
DML/DDL语句的执行区域的位置 PGA PGA
软件代码区域
软件代码区域是用来存储正在被运行的或者是能够被执行的代码的内存的一部分。oracle代码是被存储在软件代码区域但是存储位置典型地不同于用于的用户的程序,oracle代码被存放在一个更加独占的被受保护的位置。
软件区域在大小上通常是静止的,只有当软件被更新或者重新被安装时其大小才会发生改变。这些区域需求的大小会根据操作系统的不同而发生变化。
软件区域只能被读并且能够被安装为共享的或者是非共享的。当可能的话,oracle代码是共享的以便所有的oracle用户可以不需要在内存中复制多遍而可以同时访问。这样就节约在生产库上的主要的内存并且改进了整体的性能。
用户程序可以被共享或者是非共享的。一些oracle工具和效用(例如:oracle窗体和SQL*PLUS)可以被安装为共享的,但是有些不可以。oracle的多个实例可以共用不同的数据库中相同的oracle代码区域,前提是这些不同的数据库是在同一个机器上。
注意:对于所有的操作系统安装软件共享的选项是不可获取的。(例如:在PC机上的windows操作系统)。查看你的oracle操作系统指定的文档获取更多的相关信息。















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









