







本周的内容主要是关于目标检测。这是计算机视觉的领域之一,近几年发展迅猛。在学习目标检测之前,我们首先要学习目标定位。
3.1 Object localization目标定位
- 图像分类:算法遍历图像,然后告诉我们图像中是否有car;
- classification with localization:不光要告诉我们是否有car,还要将car框出来;
- detection:当图片中有多个目标时,就要将图像中所有的目标检测并定位出来。如果在做无人驾驶项目的话,不光要框出所有车辆,还要框出行人。
如果说图像分类和分类定位问题是针对一个目标而言的,那么,目标检测问题就是针对多个目标、甚至是多类多个目标而言。因此,学习图像分类有助于学习分类定位,而学习分类定位问题又有助于学习目标检测。

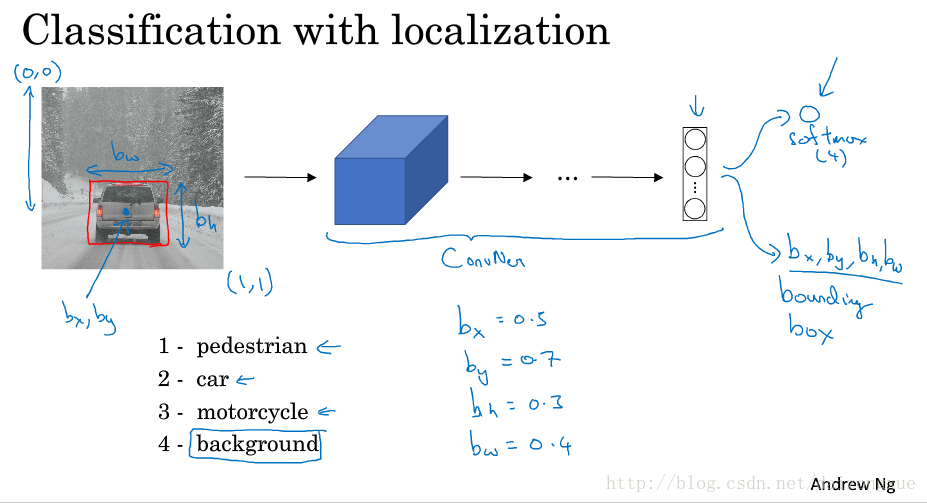
我们首先从分类定位问题讲起。如下图所示。对于图像分类问题,我们已经很熟悉了,在这个问题中,我们将图像输入ConvNet,最后的多个输出特征再接一个softmax。如果你在做无人驾驶项目,可能目标种类是行人、汽车、摩托车、背景4种。以上就是标准的分类问题的流程。如果想定位图像中的car,应该怎么办呢?为了实现这个功能,我们需要让神经网络多几个输出单元来输出一个框。特别的,在本例中,神经网络需要再多4个输出,分别称其为
bx
、
by
、
bh
、
bw
。为了方便,图像的左上角为(0,0),右下角为(1,1),
bx
、
by
分别表示方框的中心点坐标,
bh
、
bw
分别表示方框的高度和宽度。因此,训练集不仅包括目标的类别标签,还包括定位框的4个参数。本例中,定位框的4个参数的理想值分别为:0.5、0.7、0.3、0.4。
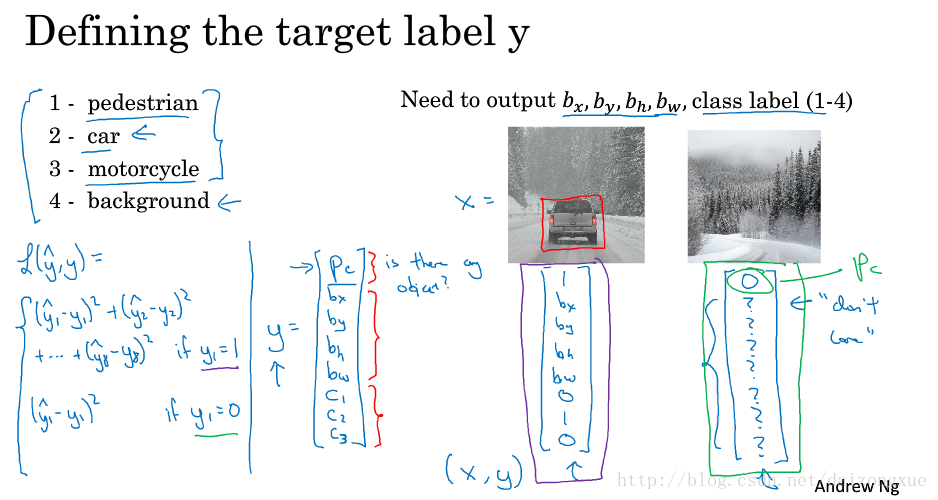
接下来详述如何为有监督学习定义目标标签y。如下图所示,我们要将图片分为行人、汽车、摩托车、背景四类,我们的输出包括定位框的4个参数和1个类别标签或类别标签出现的概率。首先,将目标标签
Y
定义如下:它是一个向量,其中,第一部分
用神经网络输出批量实数来定位图像中目标的位置是非常有用的方法。下节课讲分享另一种应用,在那里,将神经网络输出的实数集作为回归任务,这种思想在计算机视觉领域也非常常见。
3.2 Landmark detection特征点检测
上节已经学习了如何用神经网络输出目标定位方框的4个参数。更普遍的情况是,我们可以使用神经网络输出图像中重要点的x、y坐标,有时称其为landmarks。
假定我们在做人脸识别的项目,想让算法告诉我们眼角在哪里,这个点具有x、y坐标,因此我们需要一个神经网络在最后一层多两个输出节点
lx
和
ly
,表示x和y的坐标。如果我们想得到4个眼角的坐标呢?那么就是
l1x
和
l1y
,
l2x
和
l2y
,
l3x
和
l3y
,
l4x
和
l4y
.如果我们需要的点更多呢?比如我们需要64个点,每个点都有两个坐标,首先图像经过一个ConvNet,得到一些输出,第一个输出单元表明图像中是否有人脸,其余的128个输出单元分别表示64个landmarks的两个坐标,因此,共有129个输出单元。进行面部landmarks的检测,是进行面部特效的基础(如美颜、加皇冠等等)。
为了训练出这样一个神经网络,我们需要一个有标记的训练集,包括图像集合和标签Y,其中标签是需要人费力的标记这些landmarks的。
最后一个例子,如果对动作识别感兴趣,我们仍然可以定义一些关键位置,如胸部中间、左肩膀、胯,然后使用神经网络对这些标记数据进行训练,输出pose和关键点坐标。
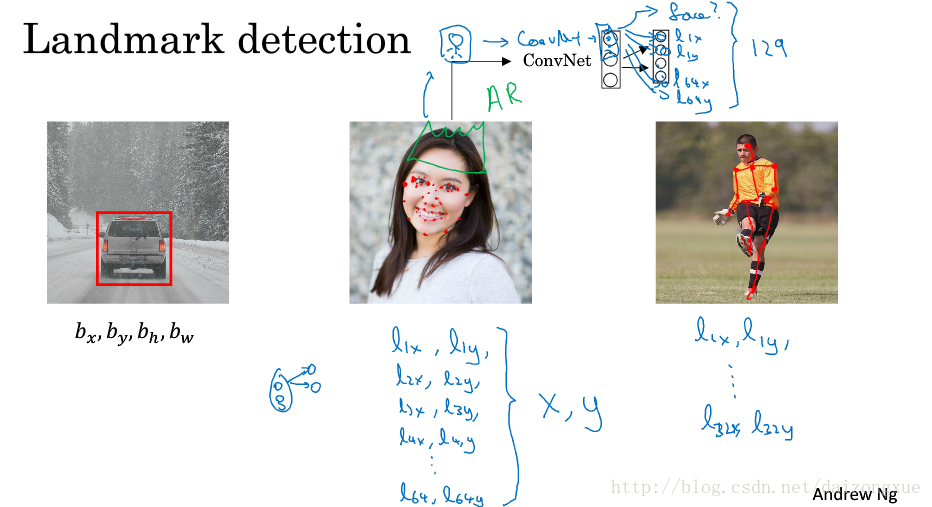
landmark detection的思想是比较简单的,只需要添加一些输出单元来输出不同landmark的坐标值。需要注意的是,landmark要在不同图像之间保持对应关系。如果人工准备好了标记的训练数据集,那么,神经网络就会输出这些landmark的坐标值,这可以帮助我们做一些表情和特效。
3.3 Object detection目标检测
我们已经学习了目标定位和landmark detection,现在我们来构建一个目标检测算法。本小节,我们将学习如何使用ConvNet来实现目标检测,使用称为滑动窗口的检测算法。
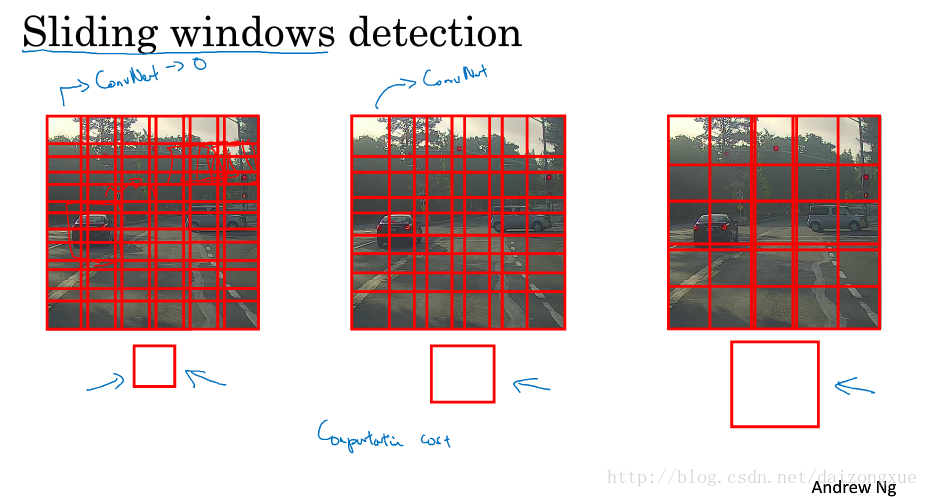
假如说,我们要构建一个车辆检测算法。我们首先创建标记的训练集,x是裁减掉其余部分只剩车辆的图像,y的值为0或1。给定了这样的标记训练集,我们就可以训练一个ConvNet,输入该训练集的是裁剪过的图像x,输出是y,值为0或1。一旦这样的模型训练好,我们可以在滑动窗检测算法中使用它。

假如测试图像如下图所示,我们选择一种size的滑动窗,我们将每次滑动窗盖住的那部分图像作为ConvNet的输入,并得到一个预测。然后,再用一个较大的滑动窗重复上述操作,第三次用一个更大的滑动窗继续进行目标检测。
滑动窗口检测算法有个很大的缺点就是,计算代价问题,因为每滑动一下都要用ConvNet计算一次。在神经网络兴起之前,分类都用的比较简单的分类器,因为它简单,所以计算代价也不高。但是对于ConvNets,这样的计算代价就很高了。幸运的是,这种计算代价问题可以得到解决,下节将进行详述。

3.4 Convolutional implementation of sliding windows滑动窗的卷积实现
上一节学习了使用滑动窗口检测算法和ConvNet进行目标检测,但这样太慢了。本节我们将学习如何卷积化这个操作。
首先,来看下我们是如何将全连接层转化为卷积层的。如下图所示。假设目标检测算法的输入是一个14*14*3大小的图像,然后用16个5*5大小filters进行卷积,得到10*10*16的结果,再用2*2的max pooling,得到5*5*16的结果,然后再经过两个全连接层和一个softmax得到最后结果。怎样将后面三层转化为卷积层呢?如图中下方网络所示,我们用400个5*5*16大小filters进行卷积,得到1*1*400的输出。与上面的网络相比,我们得到的不再是一个400个节点的集合,而是一个1*1*400的输出层,输出层中的每个节点都是前一层的输出经过某种非线性变换得到的。从数学上来说,这与全连接是一样的。
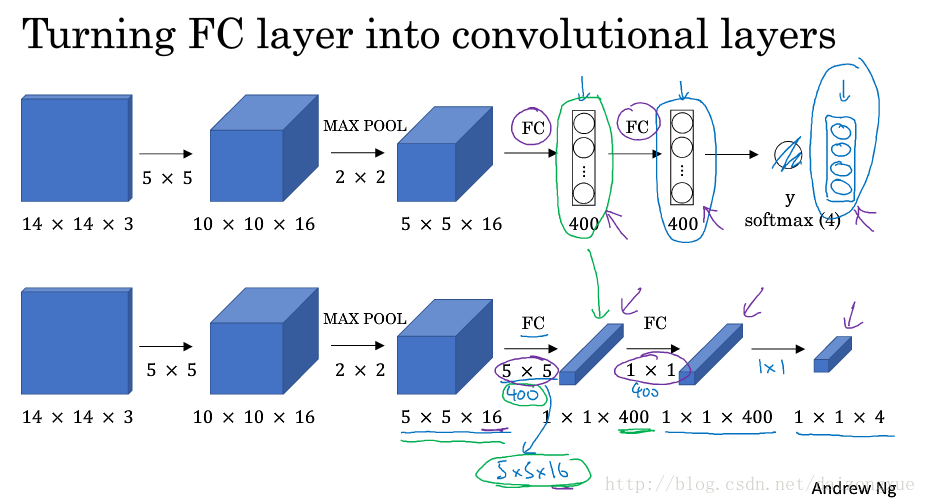
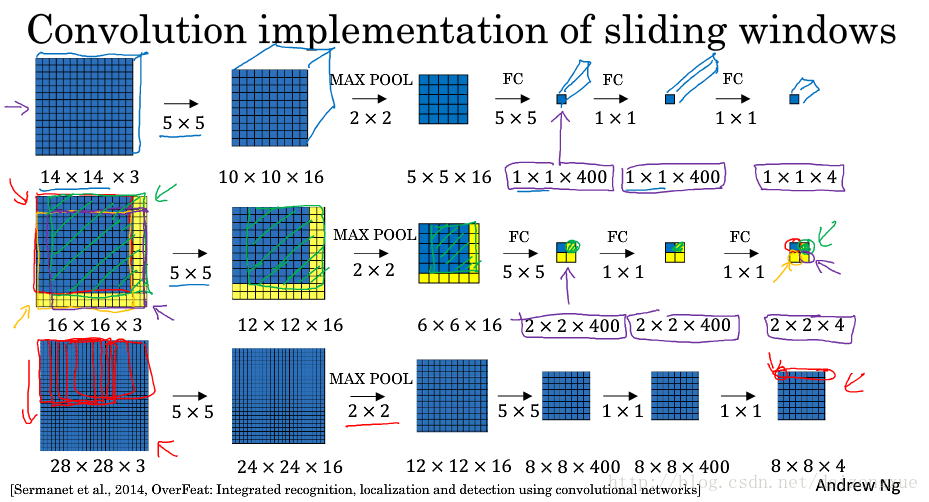
拥有了上述转化,我们来看看怎样用卷积实现滑动窗。如下图所示,假设滑动窗ConvNet的输入是14*14*3大小的图像(即,窗口大小为14*14)。测试集的图像是16*16*3大小的完整图像,通过添加黄色部分的边界。在最初的滑动窗口算法中,我们的输入只有蓝色区域,运行一次卷积网络后,得到分类结果0或者1。假设stride=2,然后分别将绿框区域、黄框区域和紫框区域输入卷积神经网络,我们可以得到4个结果。
因此,滑动窗口的卷积化实现所做的工作就是允许这4次卷积神经网络的计算共享参数。其思想是:与其将输入图像强制划分为四个子区域并独立的在卷积神经网络中运行,不如将四个图像结合成一个输入,给卷积神经网络进行计算,从而可以共享公共区域中的计算结果。
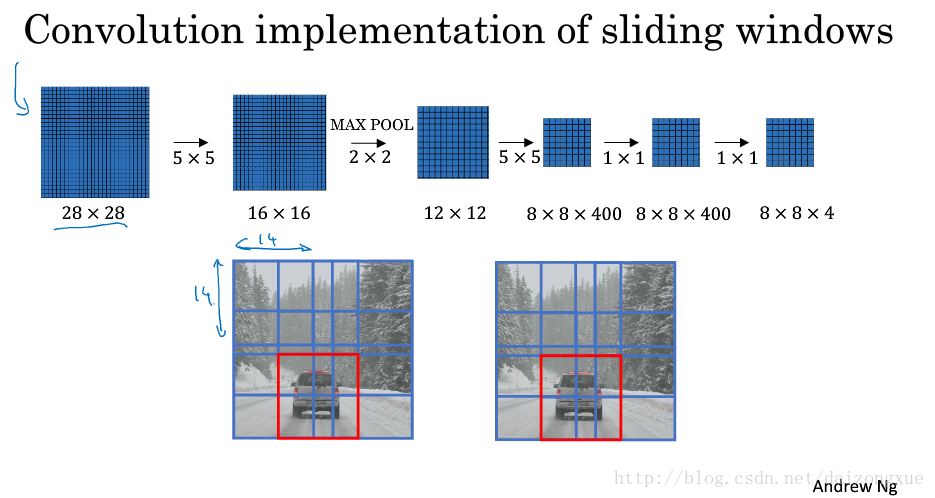
最后,又举了一个更大一点的例子。图像大小为28*28*3,滑动窗的大小仍然是14*14,经过同样的卷积神经网络,得到大小为8*8*4的输出。
总结一下,滑动窗的卷积化实现大概意思就是说,以前我的输入是经过裁剪的,大小是我滑动窗的大小,每次输入一张图,输出也就一个标记,0或1。但现在我不这样干了,我直接把未经裁剪的整个图像输入进来,比如28*28*3,通过和之前一样的ConvNet,最后得到8*8*4的结果。这其中的8*8表示按照我滑动窗的步长,比如stride=2,在原始图上滑动得到的结果
(28−142+1)∗(28−142+1)
,4代表每个窗口位置上的预测结果(因为是4类,行人、车辆、摩托车、背景)。这样,我只要经过一次ConvNet,就可以得到我之前要经过64次ConvNet才能得到的计算结果,计算效率就得到了提升。
Q:如何训练这样的网络呢?当我的滑动窗有
n
种scales时,应该就有
但是这样做,仍有一个缺点,那就是方框的位置不是很准确。下一节将集中解决这个问题。
3.5 Bounding box predictions
上节学了如何实现滑动窗口的卷积化,这样做计算更有效,但就输出方框的准确性来说,还有问题。本节我们来看看如何使方框预测更准确。
使用滑动窗口时,我们以一定的步长获取一些离散的位置集合,并在这些图像集合上运行分类器。如下图所示,当我们使用蓝色的正方形滑动窗时,在图中并没有特别匹配的区域。但如果我们将滑动窗的调整成矩形,就有一个匹配的好的区域了如红色方框所示,那么,存在一种方法使之输出一个更加准确的方框吗?

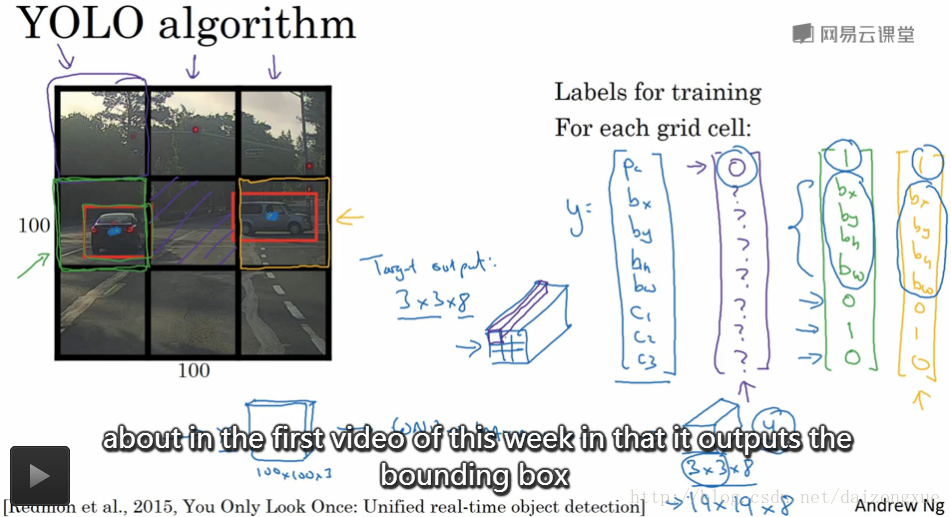
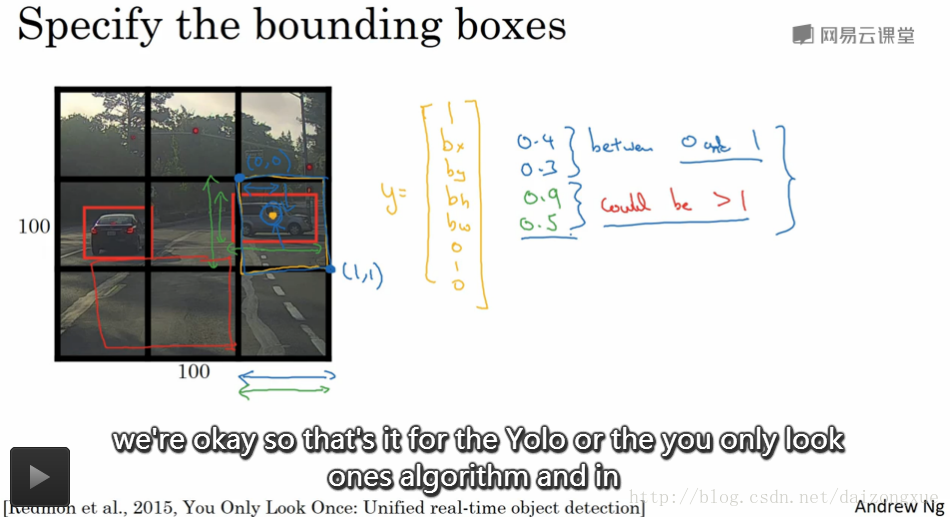
一个好的方法称为YOLO(You Only Look Once)算法。假设我们的输入图像是100*100,我们在图上划上网格,如下图所示的3*3的网格。需要注意的是,这里只是为了说明简单,使用了3*3的网格,实际中,我们使用的是更精细的网格(可能是19*19)。基本想法是,我们在每个网格里使用3.1节介绍的图像分类和定位算法。那么,我们该如何定义训练集的标签呢?对于每个网格,我们都定义一个标签y,y的各维度定义和之前介绍的相同,如下图所示,是一个8维向量。
说的更详细一点,图像中共有两个目标,YOLO算法所做的就是获取目标的中点(怎么获取?),并将目标分配给中点所在的grid。所以,左边的汽车就分配给绿框框起来的那个grid,右边的汽车就分配给黄框框起来的那个grid。尽管中心位置的grid含有两个目标的一部分,但仍然标记为无目标。绿框的标签如绿色字迹所示,黄框的标签如黄色字迹所示。对于每个grid,我们都有一个长度为8的标签y,于是我们的输出大小就是3*3*8。
为了训练神经网络,输入是100*100*3的图像,通过一个ConvNet,最后得到3*3*8的输出volume,然后使用后向传播来训练神经网络。该算法的优点是:它能输出准确的方框。测试时,输入图像X,经过前向传播,得到结果Y,从Y中的第1个channel可以得到9个网格中哪些有目标,如果有目标还能进一步得到,是哪一类目标以及边框的位置信息。只要每个grid中的目标数目不超过一个,该算法就都OK(万一超过了咋办?缩小grid?Ng说后面再讨论)。实际操作时,可能将图像划分为19*19的网格,这样一来将多个目标的中点分到一个grid的机会就小的多了,算法性能也会好。
最后说明两点:YOLO算法的输出和我们之前介绍的图像分类和定位的输出很像;其次这是个卷积化的实现,很有效。YOLO算法还有个好处就是非常流行,因为它是卷积化实现,因此几乎是实时的。
还有一个细节要与大家分享,那就是我们怎样对定位框编码?我们以下图中右边的车辆为例,它的标签如黄字所示。我们如何确定方框呢?YOLO算法以该grid左上角为(0,0),右下角为(1,1),这些
bx
、
by
、
bh
、
bw
都是相对于grid来度量的,因此,
bx
和
by
应该是0-1之间的值,但是
bh
和
bw
可以大于1。指定方框的方法很多,但这种是比较习惯性的。
下节将给出一些ideas使它工作的更好。
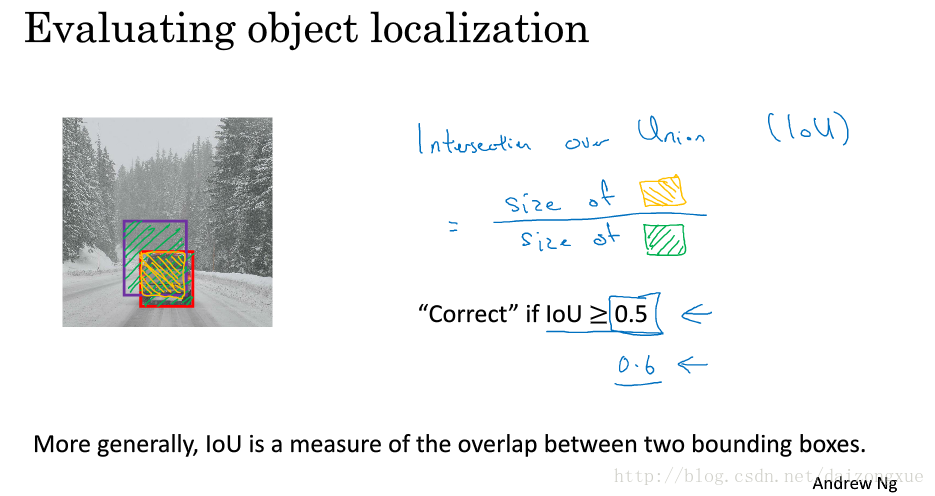
3.6 Intersection over union交并比
我们怎样才能说明目标检测算法工作的好呢?本节我们将学习一个称为交并比的函数,我们可以用它来评价目标检测算法,也可以通过添加其他部分使目标检测算法工作的更好(此部分将在下节介绍)。
在目标检测任务中,我们还希望能定位目标。如图中所示,如果红色的方框是ground truth方框,算法输出的方框是紫色的,这样的结果是好是坏呢?Intersection over union(iou)交并比函数所做的就是计算两个方框所在区域的交并比,其中并集是绿色阴影部分,交集是黄色阴影部分。一般将IoU的阈值设为0.5,如果结果大于0.5,则认为结果正确,反正则认为有误。如果要求更严格,可以将阈值设为0.6或者更高的值,阈值越高,得出的结果越精确。因此,这是衡量定位准确性的一种方式。
3.7 Non-max suppression
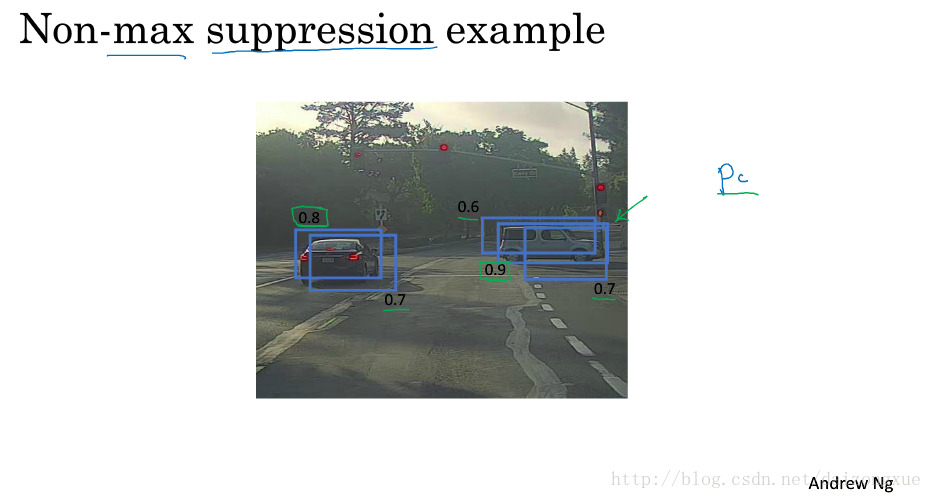
到目前为止,目标检测的一个问题是,算法可能针对一个目标找到多个方框。non-max suppression,非最大抑制就是一种能确保对目标只找到一个检测结果的算法。我们来举例说明。
比如说,我们要在下图中检测行人、车辆和摩托车。

我们可以在图上加很多网格,如下图所示,这是19*19的网格。技术上来说,图中的车辆只有一个中点,那么这个车辆就会被分配到中点所在的grid中,并且来预测车辆是否存在,右边的车辆预测方法同理。所以,理论上应该只有一个gird作出有车的预测。但是,实践中,运行目标分类和定位算法时,由于每个grid都要跑一边,因此,与真实中点所在的grid邻近的几个grids都认为中点在自己的网格中,它们也包括车辆的区域,因此,检测目标可能就会有多个。

现在,我们来看看非最大抑制是如何工作的。因为我们在每个grid cell中运行分类和定位算法,因此,很多grid cell都会说它的
pc
为较大,即含有目标,而不仅仅是2个grid cells。因此,在运行算法时,如下图所示,我们可能会得到多个检测结果。而non max suppression所做的就是对于一个目标,清除掉多个检测结果,只保留一个检测结果。具体的,以下图为例,它首先将图中所有目标检测结果中
pc
最大的值找出来,即图中的
pc=0.9
,并将其作为最可信的检测结果,然后non max suppression算法抑制掉与这个定位框具有高IoU的检测框,即图中与其重叠的
pc
为0.6和0.7的检测框。然后,在剩下的检测结果中,继续寻找
pc
值最大的检测框,并删除与
pc
值最大的检测框具有高IoU的检测框。不断循环,直至图中没有检测框。换句话说就是,non max suppression算法将同一个目标的检测结果中,
pc
最大的那个检测结果保留下来了,其余非最大的都删掉了。
现在,我们详细过一遍算法的细节。如下图所示。如果我们和之前一样,要检测行人、车辆、摩托车和背景的话,我们的输出大小就是19*19*8。但本例中,为了简化,我们只做车辆检测,输出的大小变为19*19*5。为了实现no max suppression,首先摒弃所有
pc<=threshold
的方框,比如是0.6。接下来,对于留下来的任何方框,找到
pc
值最大的方框,并将其作为输出。(当有多个目标时,先找出一个
pc
值最大的方框,将其作为输出,删掉那些和这个方框iou大于0.5的检测结果;然后继续在剩下的值检测结果中寻找最大的
pc
值,同样删掉那些和这个方框iou大于0.5的检测结果;不断重复该过程,直到没有方框。)
如果我们要检测多类目标时,比如3类,那我们需要对独立地进行non max suppression 3次,每次都只针对其中的1类。实现细节作为本周的编程作业。

3.8 Anchor boxes
目前为止,目标检测的问题之一是,每个grid cell都只能检测一种目标,如果想在同一个方框中检测多种目标,应该怎么办呢?anchor box就是来解决这个问题的。
如下图所示。图中有行人和车辆,并且两个目标的中点基本重合,都在同一个grid中,对于这个grid cell的输出,是不能预测两个目标的。anchor boxes所做的就是预定义两个不同的形状,称为anchor boxes。现在,我们将两个预测和两个anchor boxes联系起来。实际操作中,我么可能使用更多的anchor boxes,但在此例中,我们只用两个anchor boxes。因此,该grid cell的输出标签可定义为下图右边所示,长度为16,前半部分表示anchor box 1,后半部分表示anchor box 2。
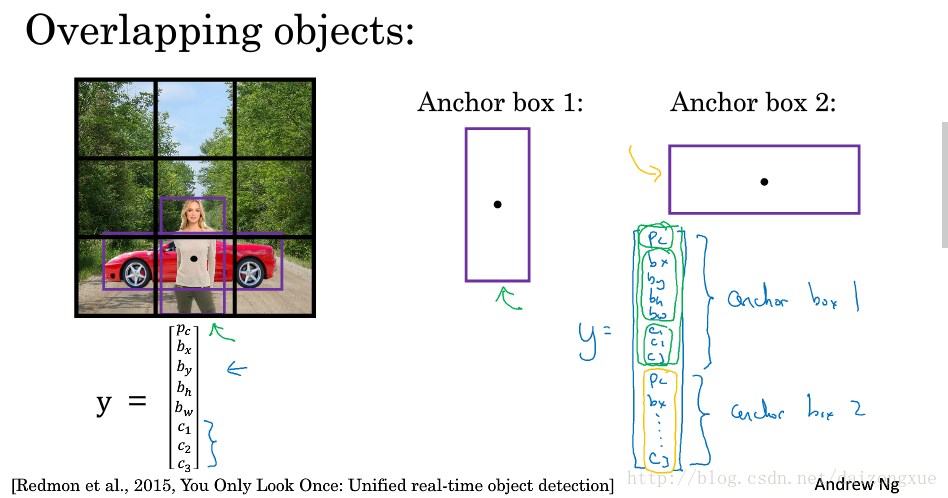
下面,我们总结一下。之前的做法,我们得到的输出大小是3*3*8;如果我们使用两个anchor boxes,那么我们的输出大小就是3*3*16,使用的anchor boxes越多,最后一维就越大。(我们可以设置anchor boxes的形状,并且每个grid cell 都有相同的一些anchor boxes,我们要把目标分配给那些和ground truth 有最大IOU的anchor box。因此,要确定一个目标,不光要找到对应的grid cell,还要找到对应的anchor box。如图中所示,它是由(grid cell,anchor box)值对确定的)。

下图给出了一个anchor box的实例。如果一个grid中既有行人又有车辆,那么输出Y就如第一个手写向量所示;如果一个grid中只有车辆没有行人,那么输出Y就如第二个手写向量所示;如果我们有3个目标,2个anchor boxes,那么算法就处理不了了;当2个目标都与同一个anchor box关联时,也无法处理。
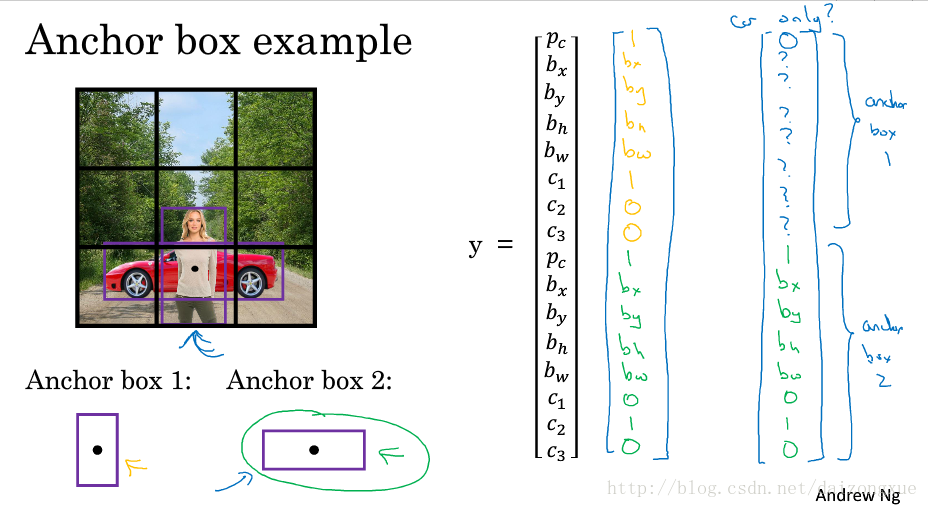
现实中,当我们把图像划分为19*19的网格时,多个目标中点处于同一个grid的情况是非常少见的。怎么选择anchor boxes呢?人们通常都是手工选择的,可以选择5-10种anchor boxes的形状来涵盖要检测的对象
3.9 YOLO algorithm
我们已经见过大多数目标检测的组件了,本节,我们将这些组件组装,得到YOLO目标检测算法。
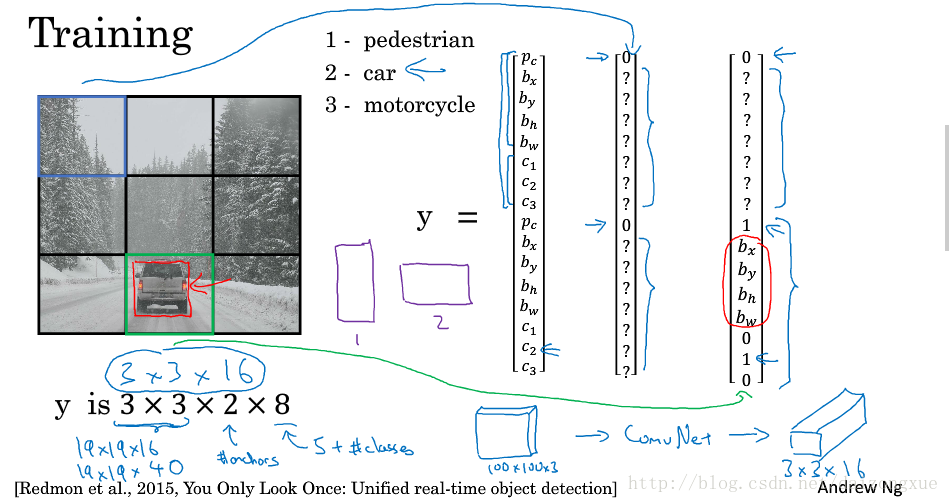
首先,我们来看看如何构造训练集。假设我们尝试训练一个算法来检测三类目标,行人、车辆、摩托车,我们还需显示指定背景类别。如果我们使用2种anchor boxes。那么我们要遍历这9个grid,对于每个grid形成它的y标签。因此,对于每个图像输出的大小为3*3*16。以左上角的grid为例,它的输出标签y如蓝色箭头所示;车辆所在的grid,它的输出标签如绿色箭头所示。如果我们将图像划分为19*19的网格,并使用5个anchor boxes,那么,输出大小就是19*19*40。以上就是训练的过程。
接下来,我们看看,对于给定的图像,算法如何做预测。如下图所示。给定一幅图像,算法会输出一个3*3*16的volume。由于左上角什么都没有,输出如蓝色向量所示,车辆所在的grid,由于里面含有车辆,输出可能如绿色向量所示。
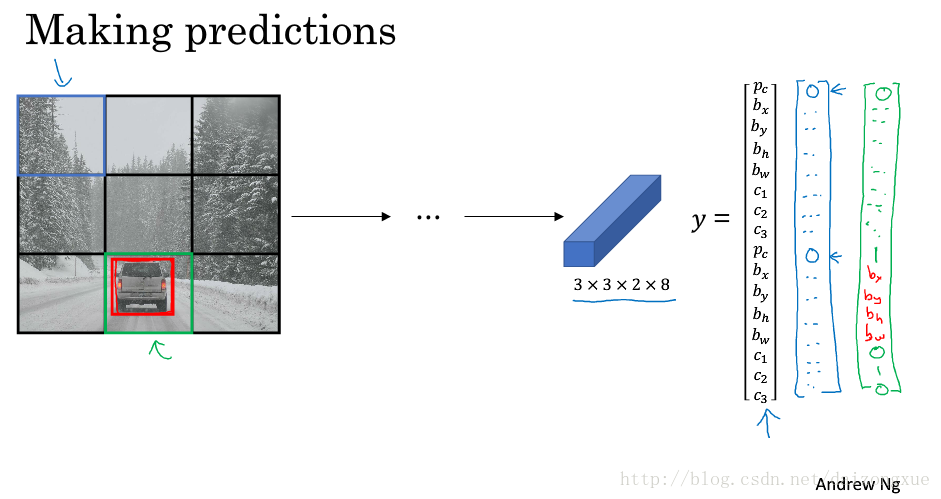
最后,我们运行non max suppression。如果我们使用2种anchor boxes,那么,对于每个grid,我们可以得到2个边框。它们中的一些可能有非常低的可能性。



3.10 Region proposals
region proposals network(RPN)
如果查看计算机视觉方向的文章,就会发现有一类region proposal的文章非常有影响力。之前,我们使用滑动窗口卷积化来进行目标检测,但是这个算法有一个缺点,那就是它要在没有目标的区域进行多次分类。针对这一问题,提出了R-CNN,其中R表示regions。它所做的事情就是挑选少量有意义的区域,并在此上运行ConvNet分类器。因此,相较于之前的所有窗口,R-CNN只运行少量感兴趣的窗口。
实现region proposal的方法是运行分割算法,分割算法的输出就像下图中最右边的图一样。为了指出什么应该是目标,我们对感兴趣的分割结果分别进行检测。

尽管这样,R-CNN还是非常慢。后来在此基础上出现了fast R-CNN、faster R-CNN。

虽然R-CNN的变种很多,但无非就是两步:1、proposed regions;2、对region进行分类。















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









