







本周的内容主要包括词表示,word embedding,word2vec,GloVe,情感分类,词嵌入除偏等。
2.1 word representation词表示
上周我们学习了RNN,GRU, LSTM。本周将看到怎么将它们应用到NLP领域的。NLP是AI的领域之一,因为深度学习带给了NLP一次革命。而其中的关键思想就是word embeddings,它是一种表示词的方法,可以使算法自动理解一些类比关系,比如男人相对于女人,正如国王相对于女王。通过word embeddings的这些思想,我们就可以构建起NLP应用,即便在标记训练集数据量比较小的情况下。最后,在本周内容的尾声,你将看到如何消除词嵌入的偏差(debias with word embeddings)。下面,我们先来讨论词表示的相关问题。
目前,我们都是用词汇表来表示词的。之前假定词汇表大小为10k,我们使用one-hot向量的方式表示词。比如说,man是词汇表中第5391个词语,那么用一个10k长度的向量来表示这个词语,其中第5391个位置为1,其余都为0。还可以用
O5391
来表示这个向量,O在这里表示one-hot。One-hot表示的缺点之一就是忽略了词与词之间的联系,这是因为任何两个one-hot向量的内积都为0,因此也无法度量两个向量之间的相似性或者距离。

如果将词语进行特征化表示呢?比如从性别、皇室、年龄、食品、尺寸、代价、是否活物、名词、动词等300个特征维度取评判每一个单词,那么一个词语就可以用300维度的向量进行表示了。这里我们假设特征维度是300,当然我们也可以添加其他特征,使特征维度变成其他整数。对于词汇表中第5391个单词,这个特征向量就记为
e5391
,这样表示的话,苹果和橙子就非常像了,提高了表示的泛化性。下面的几节中,我们会找到一种学习word embeddings的方法。只是结果的解释性不是很强,每个维度所指代的特征并不是很明确。尽管如此,我们将学习的特征表示方法,将允许算法学习出苹果和橙子比其他词语具有更高的相似度。

如果我们学习到300维的特征向量,比较流行的方法就是将300维的向量降维到2维空间,然后可视化的展现这些词语之间的关系。比较普遍的降维方法是t-SNE。通过这种可视化展现,我们可以看到相似的词都聚集在一起,表明word embeddings可以学到词与词之间相似的特征。
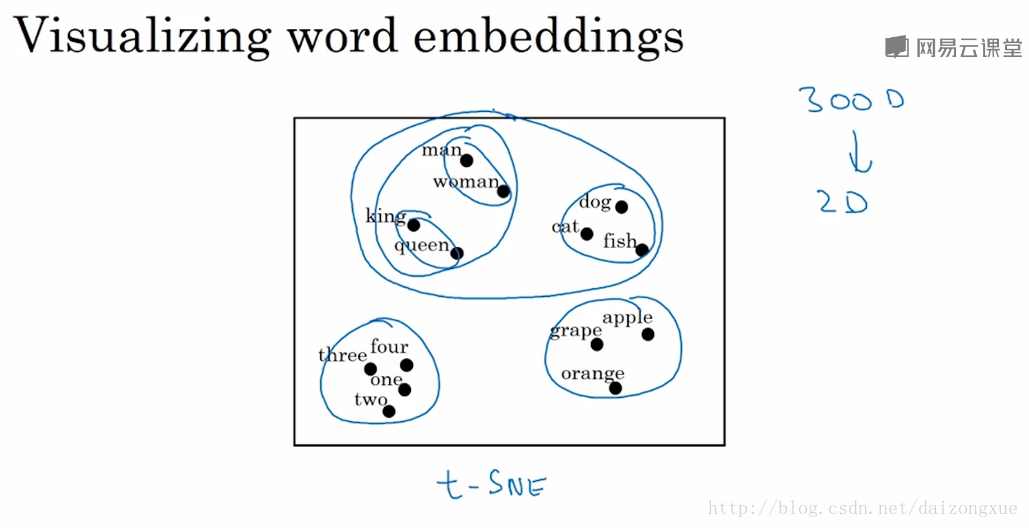
为什么要用embeddings这个词呢?对于每一个300维的向量,它们就像是嵌入在300维空间里的一个个点,因此称之为词嵌入。Word-embeddings已经成为了NLP领域中最重要的思想之一,本小节你已经了解到了我们为什么需要词嵌入(因为要学习词与词之间的相似性,以及减小词向量的长度)。下一小节,我们将深入了解如何使用这些算法来构建NLP算法。
2.2 using word embeddings使用词嵌入
上节课学习了不同单词的特征化表示,本节学习怎样在NLP中使用这些词嵌入。
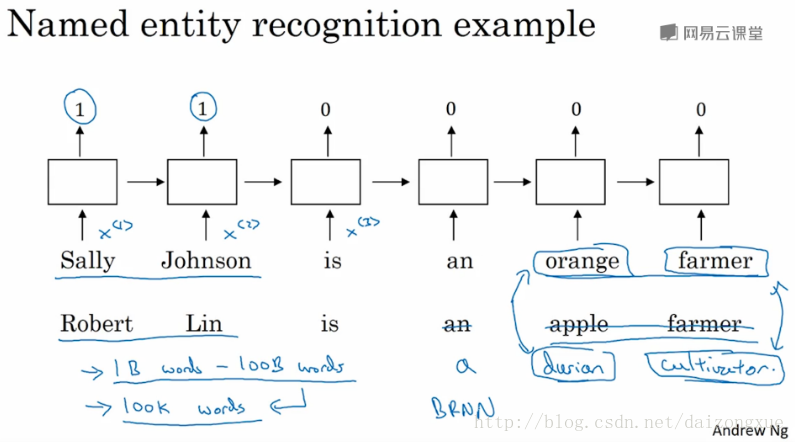
继续以NER为例子,给出下图中的句子,并进行人名检测。之前,我们是用one-hot将这些单词表示为
x<1>,x<2>,...
但是如果现在使用特征化的表示,即嵌入向量的话,在使用词嵌入作为输入,训练完模型后,如果看到一个新的输入”Robert Lin is an apple farmer.”,已知apple和orange非常相似,这会使学习算法更容易知道Robert Lin也是一个人名。但是当两句话相似的单词很少,更多的是语义上的相似时,就比较有趣了。比如说,我们有一个小的标记训练集,这里面包含的词语非常有限,如果在训练完之后,出现不在训练集里的词该怎么办?如果我们学习了词嵌入,词嵌入会告诉我们没见过的词和已知的哪个词相似,最终仍然可以做出一些推断。
词嵌入之所以能达到这种效果,是因为词嵌入的学习算法是基于大量数据文本的。我们可以在网上下载大量文本自己通过学习算法得到orange和durian的embeddings,也可以下载别人训练好的word embeddings。这样一来,我们就可以使用迁移学习了。从大量无标记的网络文本中学习出词语的embeddings,然后再将这些embeddings用于有标记的小样中进行迁移学习。这里为了简单,使用了单向的RNN,在实际应用中,我们可以使用BRNN。
以下是如何用word embeddings进行transfer learning的步骤。注意第3步可选的步骤,只有在第2步的数据足够大的时候才会进行fine tune,不然就不进行fine tune。

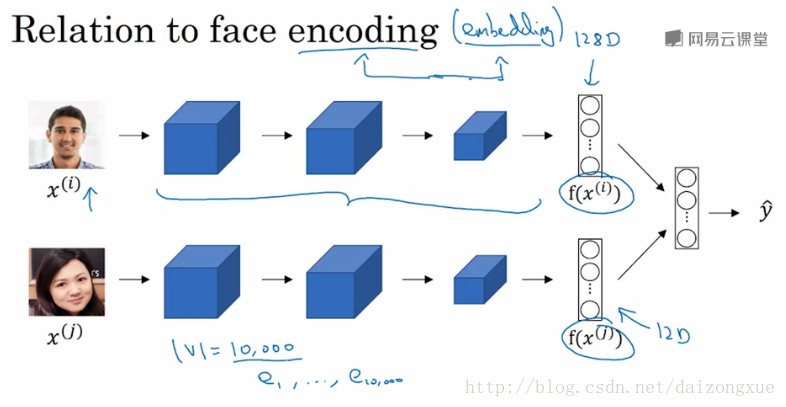
最后,词嵌入和人脸编码有些有意思的关系。在人脸编码中,我们也是通过一个网络,将人脸图像转化为一个128维的向量,通过比较向量的相似性,得出是否是同一个人脸。此处,embedding和encoding这两个单词的意思差不多。因此,在人脸识别领域,人们主要使用encoding这个词来表示向量。不同之处在于,人脸编码的图像可以是任何图像,但是word embeddings的词汇表大小是固定的,词汇表以外的词是unk。
2.3 properties of word embeddings词嵌入的性质
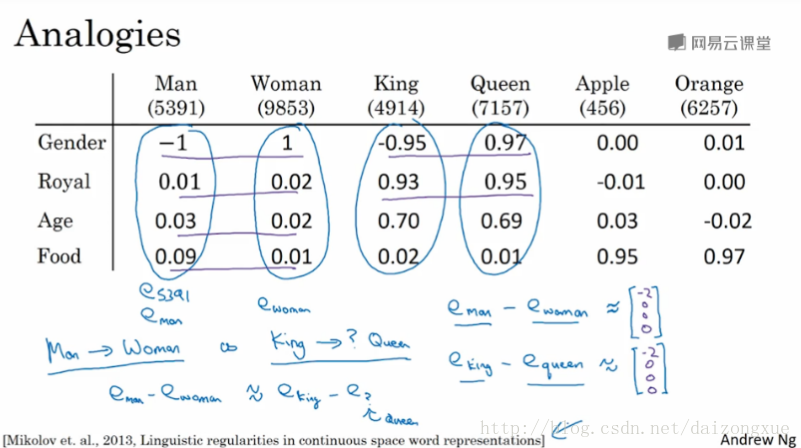
现在,我们应该了解了word embeddings是如何帮助我们构建NLP应用的。word embeddings迷人的性质之一就是它对类比推理有一定的帮助,这有助于我们更好的理解词嵌入。
以下图为例。如果man对应woman,那么king对应什么?以图中的4维向量为例,实际中word embeddings维数的典型值维50-1000。
下面正式的讨论一下,如何将这一思想转化为算法。假设word embeddings是300维的向量。
在原空间平行的向量,经过t-SNE之后通常都不再平行,因为t-SNE是一个复杂的非线性映射。
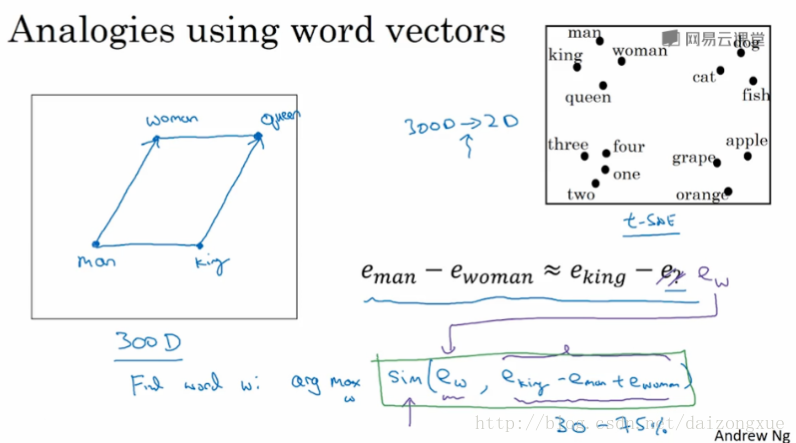
继续之前,再来快速说明下常用的相似性函数。最常用的就是余弦相似性,还有欧几里得距离。还有要提的一点是,只要文本足够大,就可以学到很多。

我们已经讨论了很多关于word embeddings的性质,下面将讨论如何学习word embeddings。
2.4 embedding matrix嵌入矩阵
本节讨论如何学习一个好的word embedding。当我们实现一个算法来学习word embedding时,我们最后学到的实际上是一个embedding matrix。详解如下。
我们像往常一样使用含有10k个单词的词汇表。词汇表包含的词如下图所示。我们要做的,就是学习一个embedding matrix
E
,该矩阵的型是
embedding matrix E乘以一个one-hot向量,就得到该one-hot向量对应的embedding vector。下图中,我们要记住的就是:我们的目标是学习嵌入矩阵
E
。下节课我们要学习的就是,随机初始化嵌入矩阵
但是在具体应用中,我们不使用矩阵乘法,因为计算效率太低,我们通常会用特定的函数,比如在keras里就有专门Embedding layer来高效的做这件事。
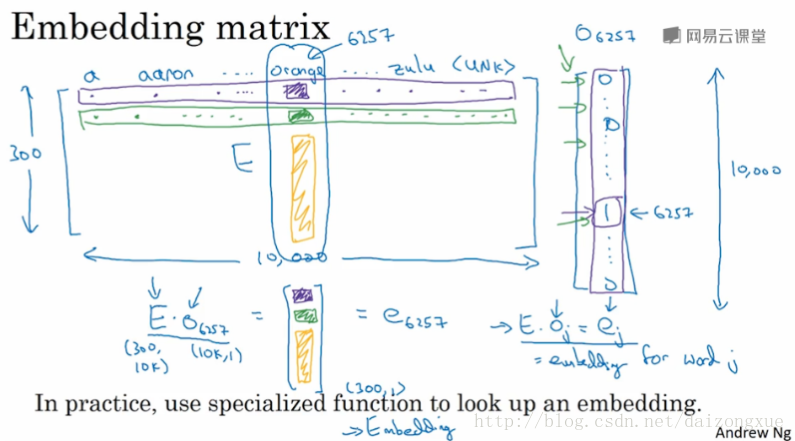
下节课我们将学习嵌入矩阵
2.5 learning word embeddings学习词嵌入
本节将学习一些具体的算法来学习word embeddings。由于最开始的时候,人们学习词嵌入都是比较复杂的方法,随后方法才变得越来越简单。因此,我们按照词嵌入技术发展的时间顺序,对相关方法进行由远至近的介绍。
如下图所示。假设我们在用神经网络来构建一个语言模型。在训练的时候,我们希望神经网络可以预测出空白位置上的词。同时,还在每个单词的下面给出了该单词在词汇表中对应的索引。事实证明,建立一个神经语言模型是学习词嵌入的合理方法。下面将介绍如何构建一个神经网络来预测序列中的下一个单词。与上一节所讲的一样,对于词汇表中索引为
j
的单词,我们可以得到它的one-hot vector
因此,该模型的参数就是黄色笔迹画出来的嵌入矩阵
E
、权重参数
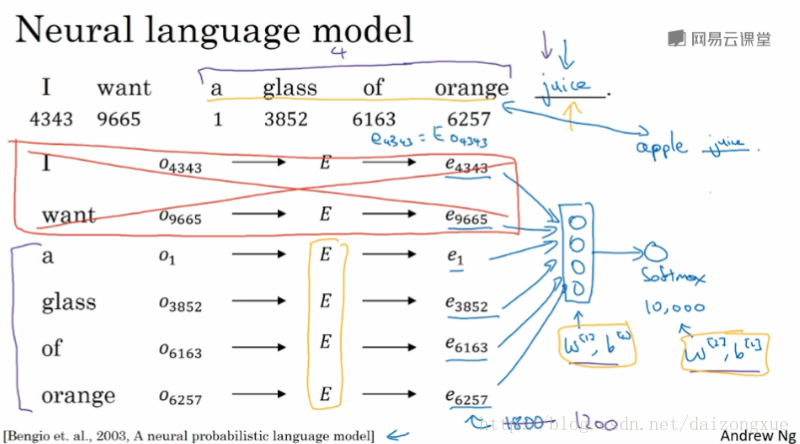
现在,我们来概括一下该算法,来看看如何能推导出更简单的算法。再解释其他算法之前,我们使用一个更复杂的句子作为例子。在上图中,算法所做的就是,在给定一些context的情况下预测target。因此,如果我们的目标是学习嵌入向量,研究人员已经试验过很多不同类型的上下文;如果我们的目标是建立语言模型,那么一般选取target词汇之前的几个单词作为context;但如果目标不是学习语言模型本身的话,那么我们可以选择其他的上下文。比如上下文是左右各4个单词,这时,我们就将这
8∗300
维的向量作为输入,喂给上图中的神经网络,进一步预测出中间位置的单词,这样也可以用来做词嵌入的学习。或者使用一种更简单的上下文,即前一个词,然后根据前一个词预测后一个词,方法也是喂入一个神经网络中。还有一个效果非常好的方法就是用附近的一个单词作为context。我们将在下一个视频中将其公式化,这就是skip-gram的思想

最后,再说明一下,如果我们的目标是构建一个语言模型,那么我们可以用target前面的n个单词作为context进行训练;但如果我们的目标是学习词嵌入,那么context就可以是target前后的词。
2.6 word2vec
上一小节中,我们已经知道了如何学习一个神经语言模型来获得好的word embeddings。本小节将学习word2vec算法,该算法是学习词嵌入更简单且计算更高效的方法。
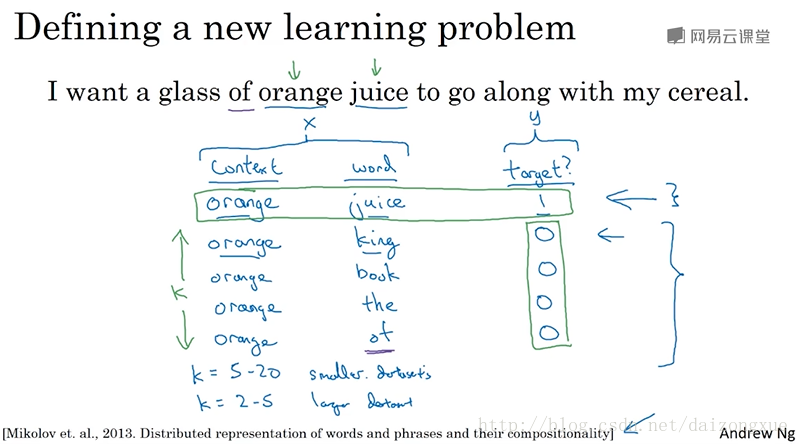
假定训练集中的一个句子如下:”I want a glass of orange juice to go along with my cereal.”
在skip-gram 模型中,我们用context到target的词汇对来创建我们的有监督学习问题。不再使用target单词前面的n个单词组成的上下文,而是随机挑选一个单词作为上下文。比如选择了单词orange,那么我们在一定的窗口大小下随机选择一个单词作为目标单词(target word),比如前后五个或十个上下文单词中。因此,有一定几率选择juice作为目标单词,这是orange后面的第一个单词,或者也可能选择前面的第二个单词glass作为目标单词,或者也有可能选择单词my作为目标单词。这样,我们就构建了一个有监督学习问题:给定context单词,预测前后一定距离内的随机选择的target单词。显然,这不是一个非常容易的学习问题,因为在设定的上下文距离中有很多不同的选择。但是,设置该问题的目标并不是要将这个有监督问题本身做的多好,而是希望通过这个学习算法获得好的词嵌入。

以下是模型的细节。词汇表大小仍然是10k,有些应用的词汇表大小已经超过100w。但是我们将要解决的基本的监督学习问题是,学习从上下文
c
到目标
总结一下,图中绿线框出来的就是模型的主体部分。模型的参数主要就是
E
和
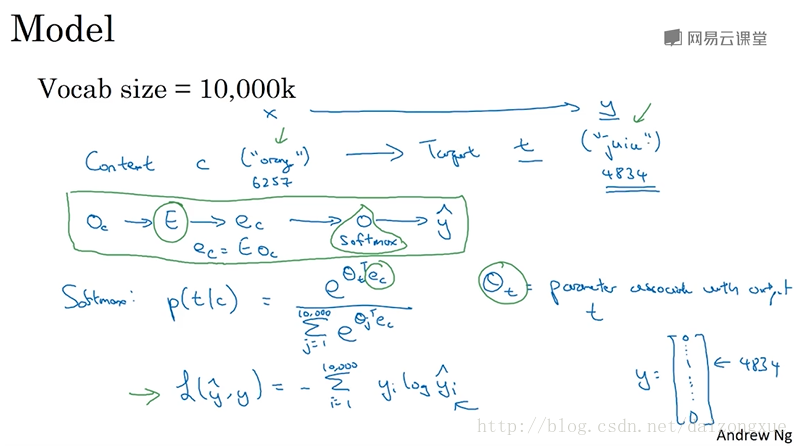
但实际上,使用skip-gram算法也有一些问题。首要的问题就是计算速度的问题,特别的,对于softmax模型,每次在估算概率的时候,都要对词汇表中的所有词计算并求和,当词汇表变大的时候,计算就会变得非常慢。解决方法之一就是使用分层的softmax分类器。意思就是,不再一下分出某个输入是10k类中的哪一类,而是先判断它是在词汇表中的前5k个单词中还是在后5k个单词中?比如这个二分类分类器告诉我们这个词在前5k个单词中,那么再用一个二分类器告诉我们,是在前2.5k个单词中还是在后2.5k个单词中?不断二分,直到最后判断出这个词的位置,即达到叶子节点。根据这个思想,我们可以画出一个二叉树,树中的叶子节点就是一个个单词,树中的内部节点都是二分类器,比如logistic classifier。这样就不必在单个分类器中将10k个计算结果加起来了,这种结构的计算代价与词汇表大小的对数成正比。以上就是分层的softmax分类器。但实际中层次softmax分类器并不会被设计为一棵完美对称的二叉树。通常,会将使用频率高的单词放在上面,而把使用频率低的单词放得更深一点。因为越常见到的单词,给它越少的检索路径的话,效率会高很多。因此,针对不同的用途,在构建这个分层softmax的时候,会有不同的经验准则。下节课将会介绍一个更简单和有效的方法,成为negative sampling。
在继续之前,我们再讨论下怎么对context
c
采样。一旦对context

word2vec有两种计算方法,一种就是本节提到的skip-gram,另一种是CBow。关于word2vec最重要的问题就是在softmax模块中的计算量问题。下图中总所要介绍的算法,它修改了训练目标,使得word2vec可以运行的更加有效
2.7 negative sampling负采样
上节已经知道,使用softmax学习word embeddings计算量很大,本节将介绍一种修改后的学习问题,称为negative sampling。它做的事情和skip gram很像,但计算效率要高得多。
在这个学习问题中,我们要做的是,创立一个新的有监督学习问题。问题就是:给定一个单词对,比如,orange-juice,我们要预测这是否是一个context-target对?在这这个例子中,orange-juice就是一个正样本,而orange-king就是一个负样本。即,我们要做的就是采样context-target对(相当于两个单词对),来预测这是不是一个c-t对,如果是就是正例,目标值就是1;如果不是,就是负例,目标就值是0。因此,我们所做的就是采样一个上下文单词和目标单词。其中,正样本就像上节所示的那样,先采样一个上下文单词,然后在一个窗口采样得到目标单词。然后,负样本的生成方法是,使用相同的上下文单词,然后在词汇表中随机取出一个单词,形成负样本的c-t对。只要是随机从词汇表中取出的单词,无论是什么都是负样本,因为出现窗口中的单词的概率是很低的。通过设置参数
K
,我们可以设定正样本和负样本的比例。如果数据集比较小,
下面来说说如何学习从x到y的映射。左边是上节课的softmax,右边是上一张slice的训练集。称
c
为上下文单词,
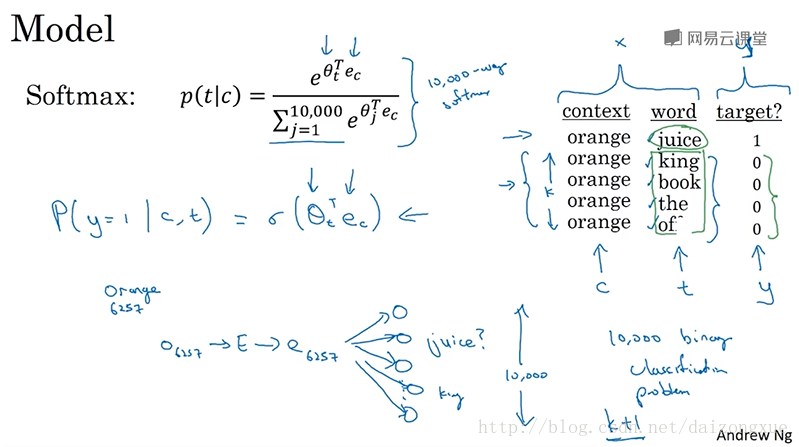
下面再来说说如何选择负样本对。我们既不按照某个单词在词汇表中的频率进行采样,也不进行均匀采样,而是按照下图中所示的式子计算出的概率进行采样。

下节课将学习一个更简单的embeddings学习方法。
2.8 GloVe word vector
我们已经学习了一些计算word embeddings的算法,另一个在NLP领域有推动作用的算法就是GloVe,它并不像word2vec或者skip-gram那样使用频繁,但也有一些爱好者,由于它很简单。现在我们来看看。
GloVe表示Global Vector。之前我们是采样一个
c−t
单词对。在GloVe算法中
xij
表示目标单词
i
出现在上下文

因此,GloVe模型所做的事情就是优化下图中的式子。这个式子度量了单词i和j、上下文单词c和目标单词t的关系,即它们共同出现的次数、频率,这个量由
xij
反映。我们将做的就是,通过使用梯度下降法最小化目标函数解出参数
θ
和
e
。如果
最后,有关该算法一个有趣的事情是,参数
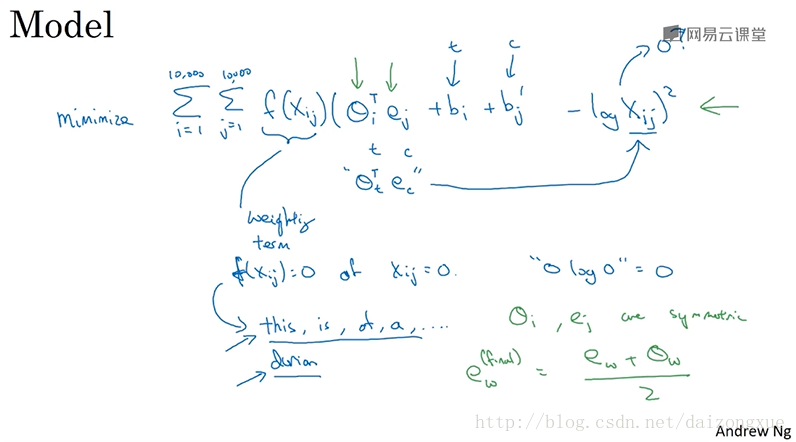
在总结词嵌入学习算法之前,有一件更优先的事情,我们需要讨论一下。word embeddings的每一维度不一定是正交的,且没有可解释性,词嵌入的每一维度可能是多个指标的线性组合。

2.9 sentiment classification情感分类
情感分类就是查看一段文本,判断某人是否喜欢它们讨论的东西。这是NLP中最重要的模块之一,应用在许多应用中。情感分类的挑战之一就是没有很多标记的训练数据。但有了word embeddings,即便标记训练集的数据量不是很大,我们也可以构建好的情感分类器。我们来看看怎么做。
下图是一个情感分类的例子。输入

下图是一个简单的情感分类的模型。同样的,我们获得每个词的词嵌入。其中,
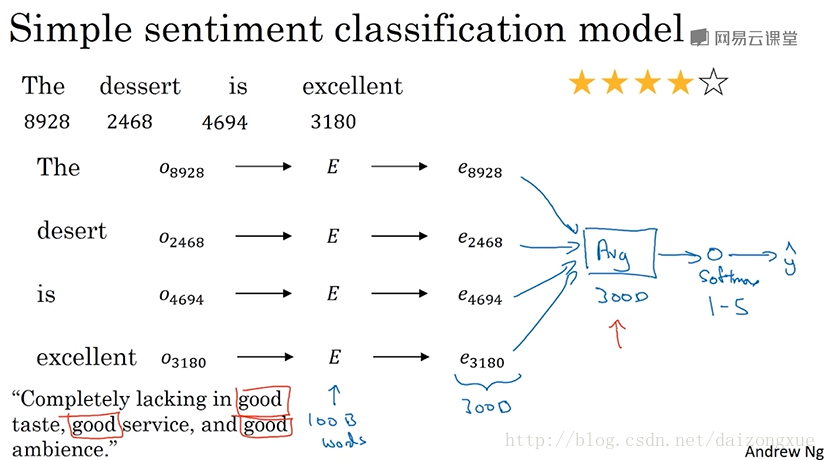
接下来是一个更好的模型,不再将embeddings加起来,而是用rnn进行情感分类。我们先获取这条评论,对评论中的每个词找出它们对应的one-hot向量,通过嵌入矩阵
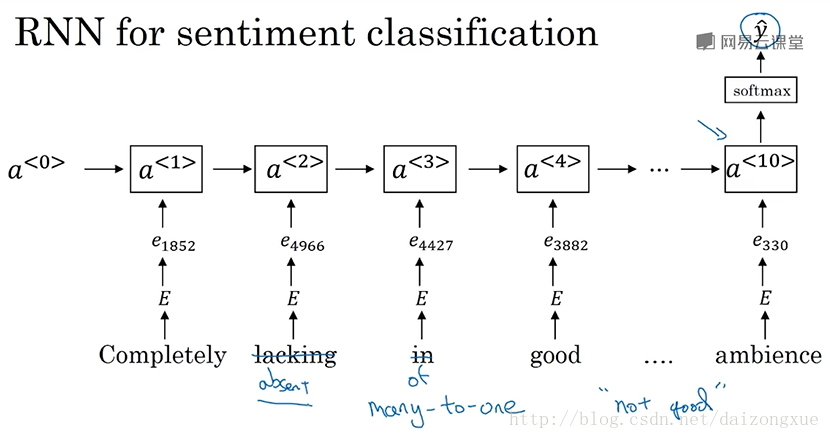
2.10 debiasing word embeddings词嵌入除偏
机器学习和AI算法越来越被广泛信任,因此,我们要确保算法不受任何形式的非预期偏差影响。比如说性别偏差、种族偏差。本小节将展示一些减少或消除word embeddings中这类偏差的方法。
我们之前讨论的大部分是词向量如何学习像man-woman类比于king-queen这样的类比。但如果被问到,man对应computer programmer相当于woman对应什么?有研究者发现了一个非常可怕的结果,就是,woman会对应homemaker!!这显然是错误的,这个结果中带有明显的性别歧视。下图中还给出了一个相关的例子。因此,根据用于训练模型的文本,词嵌入中会带有性别、种族、年龄、性取向等偏差,而这些偏差都和社会经济状态有关。而我们认为无论每个人的出身阶级,机会都是均等的。由于现在机器学习所做的决策越来越重要,从入学到贷款到法院判决等等。因此,我们要对这些学习到的偏差进行除偏,使之理想化。词嵌入可以学到训练文本中的偏差,因此,这个偏差就反映了人们在写作时的偏见。

假设在空间中,一些词嵌入的位置如图所示。我们首先要做的就是判断出我们要减少或消除偏差的方向。本例中,我们集中讨论性别偏差。但该思想对于上图中提到的其他偏差也是适用的。那么,怎样判断出这个偏差的方向呢?对于性别偏差来说,我们用
ehe−eshe
,因为它们只有性别的差异。再计算
emale−efemale
等等,并将这些差值取平均。这就使得我们能够获得性别偏差的方向,于这个方向垂直的就是无偏差方向。在本例中,假设词嵌入都是300维的,那么偏差方向只有1维,其余299维都是无偏差方向。而实际中,偏差方向可能不止1维。而相比于词嵌入差的平均值,实际上会用一个更复杂的算法,奇异值分解SVD,它与PCA很像。
然后,是中和步骤。对于那些定义不确切的词,去除其中的偏差成分。有些词天生就和性别有关,比如grandmother、grandfather、girl、boy、she、he。而有些词却没有,即便有也是人们的偏见,比如doctor、babysitter计算,我们想让这些词在性别中保持中立。我们将这些词的词嵌入在偏差轴上做移动,从而减少或消除偏差的成分,也就是说减少这些词在偏差轴上的距离。以上就是第二步所做的工作。
最后一步就是均衡化。意思是,我们可能有一些这样的词对,如grandmother-grandfather,girl-boy,对于这些,我们希望性别是它们的词嵌入向量之间的唯一差别。也就是说,doctor到这些词对中词的距离应该都一样。均衡化需要进行一些线性代数的操作,其主要目的就是把grandmother和grandfather移至距离非偏差方向等距的位置上,这样babysitter和doctor到grandmother和grandfather的距离就都一样了。
最后一个细节是,怎样决定哪些词应该是中立的呢?提出该方法的研究人员是训练一个分类器来判断的。更多的实现细节将在本周的编程练习中练习到。
















 355
355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









