







高斯混合模型(Gaussian mixture model,GMM)是单一高斯概率密度函数的延伸。GMM能够平滑地近似任意形状的密度分布。
欲了解高斯混合模型,那就先从基础的单一高斯概率密度函数讲起。(数学公式字体太难看了!!!!!!!)
注意:这一一篇致力于详细阐述过程的文章,如果你懂,可以快速跳过。
单高斯分布模型GSM
假设我们有一组在高维空间(维度为 d)的点
xi
, i=1,…,n,若这些点的分布近似椭球状,则我们可用高斯密度函数来描述产生这些点的概率密度函数(统计学记为PDF),记住这个关键公式:
其中μ代表此密度函数的中心点,Σ则代表此密度函数的协方差矩阵(Covariance Matrix),这些参数决定了此密度函数的特性,如函数形状的中心点、宽窄及走向等。在《程序员的数学2》这本书中给大家一个简单的记法。这东西就是:
前面的方框表示是多少不重要,常数而已不是0就行。(是0也没事,这样的模型我们都轻松了。。。)
在实际应用中μ通常用样本均值来代替,Σ通常用样本方差来代替。GSM单从横轴,纵轴都遵循一维高斯分布。GSM只有单中心点。如图( 图片来源):
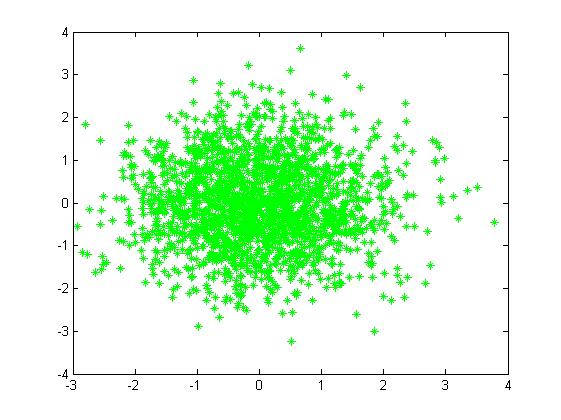
协方差矩阵简介(与主体内容无关,仅单纯介绍)
那么什么叫协方差矩阵呢?矩阵中的第(i,j)个元素是
Xi,Xj
的协方差。
Wikipedia是这么详细定义的:
假设X是以n个随机变数(其中的每个随机变数是也是一个向量,当然是一个行向量)组成的列向量,
并且 μi 是其第i个元素的期望值,即, μi=E(Xi) , 其中 Xi 是列向量中的一个标量。协方差矩阵的第i,j项(第i,j项是一个协方差)被定义为如下形式:
而协方差矩阵为:
Σ=E[(Xi−E|X|)(Xj−E|X|)⊤]=
⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢E[(X1−μ1)(X1−μ1)]E[(X2−μ2)(X1−μ1)]⋮E[(Xn−μn)(X1−μ1)]E[(X1−μ1)(X2−μ2)]E[(X2−μ2)(X2−μ2)]⋮E[(Xn−μn)(X2−μ2)]⋯⋯⋱⋯E[(X1−μ1)(Xn−μn)]E[(X2−μ2)(Xn−μn)]⋮E[(Xn−μn)(Xn−μn)]⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
最大似然估计的结果
欲求得最佳的参数来描述所观察到的资料点,可由最大似然估计法的来求得。再次之前我们必须要明确我们要求什么参数?在GSM模型中μ与Σ是两个模型参数,x是输入。
1. 在单高斯密度函数的假设下,当
x=xi
时,其密度密度为
g(xi;μ,Σ)
2. 若我们假设
xi
,i=1 ~ n 之间为互相独立的事件,则发生
X=x1,x2,...,xn
的概率密度为:
3. 然后就是取对数求导,经计算获得参数μ与Σ的估计
高斯混合模型GMM
如果我们的数据集在d维空间中的分布不是椭球状,中心点不唯一。那么就不适合以一个单一的高斯密度函数。下面是混合了三个单模型的混合高斯模型:
p(x)=α1g(x1;μ1,Σ1)+α2g(x2;μ2,Σ2)+α3g(x3;μ3,Σ3)
此概率密度函数的参数为
(α1,α2,α3,μ1,μ2,μ3,Σ1,Σ2,Σ3)
,而且要满足
α1+α2+α3=1
α是各模型的系数,这其实是一个加权单位化的思想。下面是n=2的混合高斯模型,我们发现有两个中心点。由于模型增多造成的模型参数增多,确定参数成为首要问题。(看这个图,强迫症的人肯定想聚类一下)
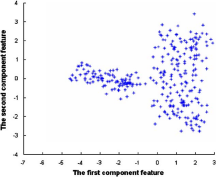
为了简化,通常将上面的协方差矩阵转化为我们常用的方式
Σi=σ2iI,i=1,2,3,...
其中,I为单位矩阵。其实求参数可以也用极大似然估计法,然后,你就慢慢玩吧。。。。。看我这态度就知道基本没人用极大似然估计单个搞的话就太乱。于是EM算法被请出来了,虽然核心也在用极大似然估计。
EM算法在高斯混合模型的应用
下面主要摘自李航《统计学习方法》,以及自己的笔记。周志华的《机器学习》书中没有详细介绍。
那么什么是EM算法。说白了,就是每次迭代由两步组成:先E一下,再M一下。E步,求期望(Expectation);M步,求极大值(Maximization)。
为什么这么搞?关键全在一个能收敛的Q函数。E步就是求这个Q函数的期望。M步就是极大化参数。不断地EMEMEMEM...操作逐步近似极大化参数这就是EM算法。
关于EM算法的正确性,喜欢了解的就看下书《统计学习方法》9.1.2。下面仅仅说怎么使用。
while()\\不接受误差就循环
{
Expectation();
Maximization();
}假设观测数据为
x1,x2,...,xN
由高斯混合模型生成。
- 明确隐变量,写出完全数据的对数似然函数
我们现在先切换到上帝视角。可以设想观测数据 xi,i=1,2,...,N 是这样产生的:首先依据各单一模型的系数 αk 选择高斯分布分模型 ϕ(x|θk) ; 然后依据这个分模型的概率分布生成观测数据 xi 。从上图n=2的角度讲就是,选个圈,生成点。
我们从上帝视角回来,事实是我们手上只有不知从哪里冒出来的X数据集,它是已知的,但反应X中的某 xi 是来自哪个分模型是未知的。这TM就很尴尬了。
像这种有结论没原因的事例。我们最简单的方法就是设置一个隐变量。这一步就体现了数学家的高明。这里习惯用隐变量 γ来表征,其定义如下:
γik={10第i个观测来自第k个分模型否则
其中i=1,2,…,N;k=1,2,…,K, γik 就是分模型k对观测数据 xi 的响应度 。
这样写出完全数据的似然函数(后验概率的感觉出现了):
P(y,γ|θ)=∏j=1NP(xi,γi1,γi2,...,γik|θ)=∏k=1Kαnkk∏i=1N[12π−−√σkexp(−(yi−μk)22σ2k)]γik
其中nk=∑i=1Nγik - EM算法中的E步,确定Q函数,求它的期望
插入知识点:Q函数与EM
Q函数:完全数据的对数似然函数
logP(Y,Z|θ)
关于在给定观测数据Y和当前参数
θ(i)
下对未观测数据Z的条件概率分布
P(Z|Y,θ(i))
的期望称为Q函数。即:
这样的Q函数可以作递推,上面公式中,Z是未观测数据,Y是观测数据,Q函数中第一个变元代表极大化参数,第二个表示参数当前估计值。
在EM算法的E步中,每次迭代是在求Q函数及其极大。EM算法中的这种Q函数有严格的收敛性证明。李航《统计学习方法》9.2
这里的Q函数为:
这样 E(γjk|x,θ) (记为 γjk^ )就需要单独计算。(注意这里的 θ 应该有上角标,但是在E步中不涉及上角标操作,为了避免与角标冲突故省去, 同时加将 γ 的角标换成j。)
下面我们计算出分模型k对观测数据x的响应度 γ。因为是0-1分布所以可以这算:
3. EM中的M步
迭代的M步是求使函数取极大值的θ,并赋值给下一次迭代:
这里就可以用最大似然估计了。对 μk,σ2k 分别求偏导并等于0。求α时要注意隐藏条件
知道这些值变化不再明显为止。这里有必要说一下 nk 。这是什么?
我们回到第一步 nk=∑Nj=1γjk ,因为γ除了0就是1,求最大似然法时0就不用了。那么α这个公式就是(这个分模型的数)/(分模型总数)。
个人总结
个人认为:高斯混合模型GMM对于多中心点集合的建模。这种点集合最好是一堆一堆聚集在一起的,逼强迫症数据分析师想求聚类的。如下图。(数据集特性与k-means差不多,数据集别散得太厉害)。都属于原型聚类。
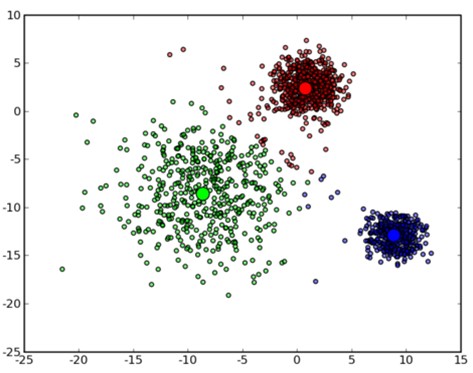
K-means的第一步开始是明确要聚几类(即K等于几),GMM第一步开始的明确是混合几个高斯模型(即N等于几)。
我翻阅很多论文,发现高斯混合隐马尔科夫链模型(GMM-HMM)在工业预测方面有很大的应用,后面讲述GMM-HMM。















 2745
2745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}