










持续分享有用、有价值、精选的优质大数据面试题
致力于打造全网最全的大数据面试专题题库

71、Zookeeper的典型应用场景有哪些?
参考答案:
Zookeeper是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布和订阅。
通过对Zookeeper中丰富的数据节点进行交叉使用,配合Watcher事件通知机制,可以非常方便的构建一系列分布式应用中年都会涉及的核心功能,如:
1.数据发布/订阅
2.负载均衡
3.命名服务
4.分布式协调/通知
5.集群管理
6.Master选举
7.分布式锁
8.分布式队列
72、ZooKeeper是什么?
参考答案:
ZooKeeper是一个开放源码的分布式协调服务,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
分布式应用程序可以基于Zookeeper实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列等功能。
73、Zookeeper有哪些特性?
参考答案:
一致性、原子性、单一视图、可靠性、实时性。
74、Zookeeper集群的机制是什么?
参考答案:
半数机制:集群中半数以上机器存活,集群可用。
75、Zookeeper服务端处理Watcher实现
参考答案:
1.客户端向服务端注册watcher,服务端接收Watcher并存储。
2.Watcher触发。
3.调用process方法来触发Watcher。
76、一个hadoop集群,hdfs副本数为3,此时存入1G数据。然后修改hdfs配置文件,将副本设置为2,然后重启hadoop集群,此时再存入1G数据。请问此时hdfs集群上数据量一共有多大?
参考答案:
第一次存1G数据:1G*3=3G 第二次存入1G数据:1G*2=2G(配置修改重启后,只对后续接入的数据有效,已经存入的数据如果想改副本需要通过命令行来修改) 总数据大小:3G+2G=5G
77、HDFS元数据都会存在于NameNode的内存中,因此NameNode的内存大小直接决定了集群支持的最大容量,那么如何估算NameNode需要的内存大小?比如一个含有200个节点的集群,每个节点有24TB的磁盘,每个Block的大小为128MB,每个块有3个副本,那么请问,在这种场景下需要NameNode的内存大小为多少?
前提条件:一般1GB内存可以管理100万个block文件
参考答案:
先计算块文件的个数;200*25165824MB(24TB)/128*3=13107200 一般1GB内存可以管理100万万个block文件 参照该方法计算最终大概需要13.1072GB的内存。除此之外还要基于性万个block文件,所以在选择NameNode内存时要选择一个大于该值的一个合理的整数值
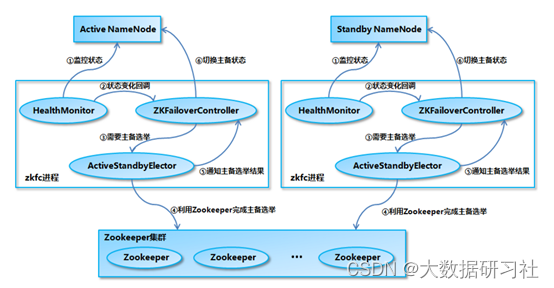
78、简述namenode的HA机制。他是如何实现故障切换的?
参考答案:
1.通过QJM解决NameNode元数据共享存储问题
NameNode记录了HDFS的目录文件等元数据,客户端每次对文件的增删改等操作,Namenode都会记录一条日志,叫做editlog,而元数据存储在fsimage中。为了保持Stadnby与active的状态一致,standby需要尽量实时获取每条editlog日志,并应用到FsImage中。这时需要一个共享存储存放editlog,standby能实时获取日志。
有两个关键点需要保证:
1)共享存储是高可用的。
2)需要防止两个NameNode同时向共享存储写数据导致数据损坏。
共享存储常用的方式是Qurom Journal Manager,QJM可以认为是包含一些JournalNode的集群,JournalNode运行在不同的机器上,每个JournalNode是一个很轻量的守护进程,所以可以部署在hadoop集群的节点上,QJM中至少要有3个JournalNode,因为edit log必须要写到JournalNodes中大部分节点中,比如运行3,5,7个JournalNode,如果你运行了N个JournalNode,那么系统可以容忍最多(N-1)/2个节点失败。

共享存储实现逻辑:
1)初始化后,Active NN把editlog写到大多数JN并返回成功(即大于等于N+1)即认定写成功。
2)Standby NN定期从JN读取一批editlog,并应用到内存中的FsImage中。
3)NameNode每次写Editlog都需要传递一个编号Epoch给JN,JN会对比Epoch,如果比自己保存的Epoch大或相同,则可以写,JN更新自己的Epoch到最新,否则拒绝操作。在切换时,Standby转换为Active时,会把Epoch+1,这样就防止即使之前的NameNode向JN写日志,即使写也会失败。
2.利用Zookeeper实现NameNode故障转移

3. HDFS2 NN的主备切换流程
79、在hive数据库当中你们的元数据信息是存储在哪里的?
参考答案:
- hive 默认内置元数据库为derby数据库。
- 生产环境中我们使用mysql 数据库。
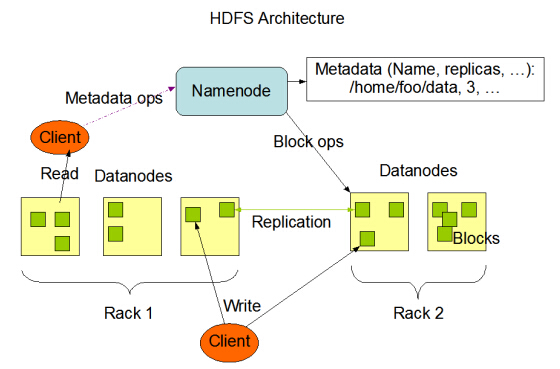
80、简述HDFS体系结构?
参考答案:
HDFS具有主/从架构。一个HDFS集群包含一个NameNode(一个主服务器),用于管理文件系统名称空间并管理客户端对文件的访问。此外,还有许多DataNode,通常是群集中的每个节点一个DataNode,用于数据存储。HDFS对外暴露文件系统名称空间并允许用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。NameNode执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。它还确定块到DataNode的映射。DataNode负责提供来自文件系统客户端的读取和写入请求。DataNode还在NameNode的指令下执行块创建,删除,复制。
















 3295
3295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











