







 本文介绍了如何将HDFS的副本数设置为3,详细步骤包括修改hdfs-site.xml配置文件。接着,文章讲解了基于MapReduce框架开发wordcount程序的过程,包括项目创建、引入HDFS相关jar包、代码编写、本地环境搭建和打包。最后,文章演示了在SSH上运行MapReduce的wordcount示例,并展示了运行结果。
本文介绍了如何将HDFS的副本数设置为3,详细步骤包括修改hdfs-site.xml配置文件。接着,文章讲解了基于MapReduce框架开发wordcount程序的过程,包括项目创建、引入HDFS相关jar包、代码编写、本地环境搭建和打包。最后,文章演示了在SSH上运行MapReduce的wordcount示例,并展示了运行结果。
目录
四、在ssh运行MapReduce提供的wordcount例子
一、将HDFS副本数设置为3
1、什么是HDFS副本数?
HDFS 数据副本概念:HDFS数据副本存放策略,副本的存放是HDFS可靠性和高性能的关键。优化的副本存放策略是HDFS区分于其他大部分分布式文件系统的重要特性。这种特性需要做大量的调优,并需要经验的积累。
2.将副本数设置为3
将HDFS副本数设置为3,我们需要修改虚拟机主机上的Hadoop配置文件。
首先先把虚拟机路径切换到Hadoop文件的配置路径,使用命令:cd $HADOOP_HOME/etc/hadoop,修改hdfs-site.xml文件,把副本数量设置为3。
具体如下图:
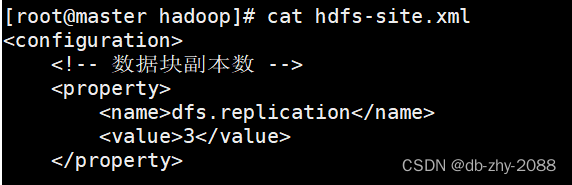
这里我已经修改过来,使用的是查看命令,修改命令为:vi hdfs-site.xml,接着输入i进入编式。到这里我们的副本数就设置完成了。
二、基于MapReduce框架开发wordcount程序
1、什么是MapReduce框架?
MapReduce是一种分布式计算模型,用于大规模数据集(如TB级)的并行运算。核心思想是分而治之,即先分后总。主要用来处理离线数据。
基于MapReduce框架开发的程序称之为MapReduce程序。MapReduce程序由两个阶段组成: map和reduce,用户(即程序员)只需实现map()和reduce()两个函数,即可开发出分布式计算程序。
2、 启动idea,新建一个maven项目
3、将HDFS相关的jar包引入到项目中
将HDFS相关的jar包引入到项目中,目的是调用HDFS提供的相关的类、方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









