







一、MMU
MMU:memory management unit,称为内存管理单元,或者是存储器管理单元,MMU是硬件设备,主要作用是负责从CPU内核发出的虚拟地址到物理地址的映射,并提供硬件机制的内存访问权限检查。
相关概念:
- 地址范围: 指处理器能够产生的地址集合,如一个32bit的处理器ARM9,其能产生的地址集合是0x0000 0000 ~ 0xffff ffff(4G),这个地址范围也称为虚拟地址空间,其中对应的地址为虚拟地址。
- 虚拟地址与物理地址: 与虚拟地址空间和虚拟地址相对应的是物理地址空间和物理地址;物理地址空间只是虚拟地址空间的一个子集。如一台内存为256MB的32bit X86主机,其虚拟地址空间是0 ~ 0xffffffff(4GB),物理地址空间范围是0 ~ 0x0fff ffff(256M)
- 分页机制:
-
如果处理器没有MMU,或者有MMU但没有启用,CPU执行单元发出的内存地址将直接传到芯片引脚上,被内存芯片(以下称为物理内存,以便与虚拟内存区分)接收,这称为物理地址(Physical Address,以下简称PA),如下图所示:
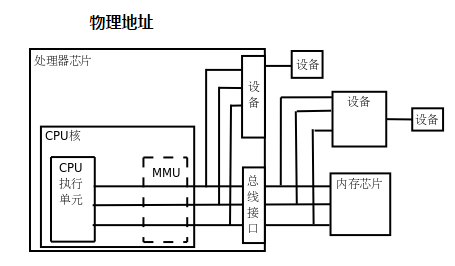
如果处理器启用了MMU,CPU执行单元发出的内存地址将被MMU截获,从CPU到MMU的地址称为虚拟地址(Virtual Address,以下简称VA),而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将VA映射成PA:
-
大多数使用MMU的机器都采用分页机制。虚拟地址空间以页为单位进行划分,而相应的物理地址空间也被划分,其使用的单位称为页帧,页帧和页必须保持相同,因为内存与外部存储器之间的传输是以页为单位进行传输的。例如,MMU可以通过一个映射项将VA的一页0xb7001000~0xb7001fff映射到PA的一页0x2000~0x2fff,如果CPU执行单元要访问虚拟地址0xb7001008,则实际访问到的物理地址是0x2008。
-
虚拟内存的哪个页面映射到物理内存的哪个页帧是通过页表(Page Table)来描述的,页表保存在物理内存中,MMU会查找页表来确定一个VA应该映射到什么PA。
通常操作系统和MMU是这样配合的:
-
操作系统在初始化或分配、释放内存时会执行一些指令在物理内存中填写页表,然后用指令设置MMU,告诉MMU页表在物理内存中的什么位置。
-
设置好之后,CPU每次执行访问内存的指令都会自动引发MMU做查表和地址转换操作,地址转换操作由硬件自动完成,不需要用指令控制MMU去做。
我们在程序中使用的变量和函数都有各自的地址,在程序被编译后,这些地址就成了指令中的地址,指令中的地址就成了CPU执行单元发出的内存地址,所以在启用MMU的情况下, 程序中使用的地址均是虚拟内存地址,都会引发MMU进行查表和地址转换操作。
程序执行过程中,用到的指令和数据的地址往往集中在一个很小的范围内,其中的地址、数据经常使用,这是程序访问的局部性。由此,通过使用一个高速、容量相对较小的存储器来存储近期用到的页表条目(段、大页、小页、极小页描述符),避免每次地址转换都到主存中查找,这样就大幅提高性能。这个存储器用来帮助快速地进行地址转换,这就是TLB,。
二、TLB
TLB 是Translation Lookaside Buffer的缩写,直译为旁路快表缓冲,也可以理解为页表缓冲,地址变换高速缓存。功能上跟cache类似,它所缓存的是最近使用的数据的页表项(虚拟地址到物理地址的映射)。他的出现是为了加快访问数据(内存)的速度,减少重复的页表查找。当然它不是必须要有的,但有它,速度就更快。
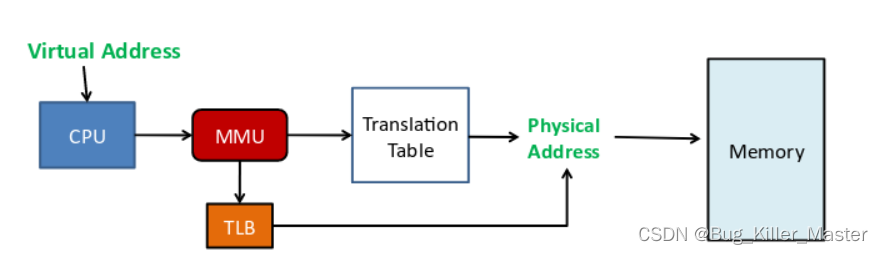
有了TLB之后,CPU访问某个虚拟内存地址的过程如下
- 1.CPU产生一个虚拟地址
- 2.MMU从TLB中获取页表,翻译成物理地址
- 3.MMU把物理地址发送给L1/L2/L3/内存
- 4.L1/L2/L3/内存将地址对应数据返回给CPU
相关概念:
TLB原理
当cpu要访问一个虚拟地址/线性地址时,CPU会首先根据虚拟地址的高20位(20是x86特定的,不同架构有不同的值)在TLB中查找。如果是表中没有相应的表项,称为TLB miss,需要通过访问慢速RAM中的页表计算出相应的物理地址。同时,物理地址被存放在一个TLB表项中,以后对同一线性地址的访问,直接从TLB表项中获取物理地址即可,称为TLB hit。
TLB表项
TLB内部存放的基本单位是页表条目,对应着RAM中存放的页表条目。页表条目的大小固定不变的,所以TLB容量越大,所能存放的页表条目越多,TLB hit的几率也越大。但是TLB容量毕竟是有限的,因此RAM页表和TLB页表条目无法做到一一对应。因此CPU收到一个线性地址,那么必须快速做两个判断:
1 所需的也表示否已经缓存在TLB内部(TLB miss或者TLB hit)
2 所需的页表在TLB的哪个条目内
为了尽量减少CPU做出这些判断所需的时间,那么就必须在TLB页表条目和内存页表条目之间的对应方式做足功夫
全相连 - full associative
在这种组织方式下,TLB cache中的表项和线性地址之间没有任何关系,也就是说,一个TLB表项可以和任意线性地址的页表项关联。这种关联方式使得TLB表项空间的利用率最大。但是延迟也可能相当的大,因为每次CPU请求,TLB硬件都把线性地址和TLB的表项逐一比较,直到TLB hit或者所有TLB表项比较完成。特别是随着CPU缓存越来越大,需要比较大量的TLB表项,所以这种组织方式只适合小容量TLB
直接匹配
每一个线性地址块都可通过模运算对应到唯一的TLB表项,这样只需进行一次比较,降低了TLB内比较的延迟。但是这个方式产生冲突的几率非常高,导致TLB miss的发生,降低了命中率。
比如,我们假定TLB cache共包含16个表项,CPU顺序访问以下线性地址块:1, 17 , 1, 33。当CPU访问地址块1时,1 mod 16 = 1,TLB查看它的第一个页表项是否包含指定的线性地址块1,包含则命中,否则从RAM装入;然后CPU方位地址块17,17 mod 16 = 1,TLB发现它的第一个页表项对应的不是线性地址块17,TLB miss发生,TLB访问RAM把地址块17的页表项装入TLB;CPU接下来访问地址块1,此时又发生了miss,TLB只好访问RAM重新装入地址块1对应的页表项。因此在某些特定访问模式下,直接匹配的性能差到了极点
组相连 - set-associative
为了解决全相连内部比较效率低和直接匹配的冲突,引入了组相连。这种方式把所有的TLB表项分成多个组,每个线性地址块对应的不再是一个TLB表项,而是一个TLB表项组。CPU做地址转换时,首先计算线性地址块对应哪个TLB表项组,然后在这个TLB表项组顺序比对。按照组长度,我们可以称之为2路,4路,8路。
经过长期的工程实践,发现8路组相连是一个性能分界点。8路组相连的命中率几乎和全相连命中率几乎一样,超过8路,组内对比延迟带来的缺点就超过命中率提高带来的好处了。
这三种方式各有优缺点,组相连是个折衷的选择,适合大部分应用环境。当然针对不同的领域,也可以采用其他的cache组织形式。
TLB表项更新
TLB表项更新可以有TLB硬件自动发起,也可以有软件主动更新
1. TLB miss发生后,CPU从RAM获取页表项,会自动更新TLB表项
2. TLB中的表项在某些情况下是无效的,比如进程切换,更改内核页表等,此时CPU硬件不知道哪些TLB表项是无效的,只能由软件在这些场景下,刷新TLB。
参考文档:
MMU内存管理单元 - AlanTu - 博客园 (cnblogs.com)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









