







CPU Cache
处理器通常会在芯片中包含硬件缓存以提高内存访问性能
L1: 通常分为指令缓存和数据缓存
L2: 同时缓存指令和数据
L3: 更大一级的缓存可选
一级缓存通常按虚拟内存地址空间寻址,二级及以上按物理内存地址寻址。具体取决于处理器。


页面和块(页框):分页存储管理是将作业的逻辑地址划分为一系列同等大小的部分,称为页。并为各页加以编号,每个作业的页的编号都是从0开始的。与之类似,把可用的物理内存也划分为同样大小的连续的部分,称为块或页框。
页表:如何在内存中找到页所对应的物理块是地址装换的关键。为此,系统为每个进程创建了一个页表。在进程逻辑地址空间中的每一页,依次在页表中有一个表项,记录了该页对应的物理块号。在配置了页表之后,通过查找页表就可以很容易地找到该页在内存中的位置。页表具有逻辑地址到物理地址映射的作用。
MMU:是一种硬件电路,它包含两个部件,一个是分段部件,一个是分页部件,在本书中,我们把它们分别叫做分段机制和分页机制,以利于从逻辑的角度来理解硬件的实现机制。分段机制把一个逻辑地址转换为线性地址;接着,分页机制把一个线性地址转换为物理地址。总之它把逻辑地址转换为物理地址。
TLB:MMU使用TLB作为第一级转换缓存,不需要经过页表就能把虚拟地址映射成物理地址的小的硬件设备,这样就不用为了找到物理地址而去查询主存中的页表。TLB寄存器的每个条目包含一个页面的信息:有效位,虚页面号,修改位,保护码,和页面所在的物理页面号。使用更大的页可以增加其缓存转换的内存范围,从而增加TLB命中率来提高系统性能
Cache的结构和工作原理如图2.3.1所示。
Cache 与主存地址映像
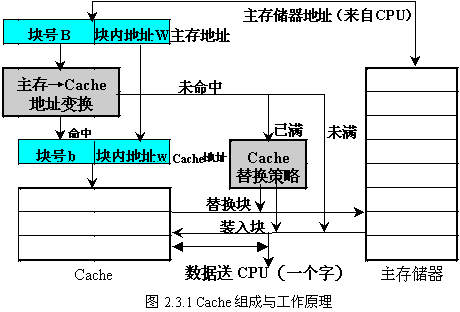
主要由三大部分组成:
Cache存储体:存放由主存调入的指令与数据块。
地址转换部件:建立目录表以实现主存地址到缓存地址的转换。
替换部件:在缓存已满时按一定策略进行数据块替换,并修改地址转换部件。
- 主存的任意一块可以映象到Cache中的任意一块
- 主存与缓存分成相同大小的数据块。
- 主存的某一数据块可以装入缓存的任意一块空间中。

优点:命中率比较高,Cache存储空间利用率高。
缺点:访问相关存储器时,每次都要与全部内容比较,速度低,成本高,因而应用少。
直接相联方式
- 主存与缓存分成相同大小的数据块。
- 主存容量应是缓存容量的整数倍,将主存空间按缓存的容量分成区,主存中每一区的块数与缓存的总块数相等。
- 主存中某区的一块存入缓存时只能存入缓存中块号相同的位置。

优点:地址映象方式简单,数据访问时,只需检查区号是否相等即可,因而可以得到比较快的访问速度,硬件设备简单。
缺点:替换操作频繁,命中率比较低。
组相联
- 主存和Cache按同样大小划分成块。
- 主存和Cache按同样大小划分成组。
- 主存容量是缓存容量的整数倍,将主存空间按缓冲区的大小分成区,主存中每一区的组数与缓存的组数相同。
- 当主存的数据调入缓存时,主存与缓存的组号应相等,也就是各区中的某一块只能存入缓存的同组号的空间内,但组内各块地址之间则可以任意存放, 即从主存的组到Cache的组之间采用直接映象方式;在两个对应的组内部采用全相联映象方式。
OS stack
1.进程的堆栈
内核在创建进程的时候,在创建task_struct的同时,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
2.进程用户栈和内核栈的切换(堆栈指针寄存器切换)
当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。
进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。(这里因为内核栈的栈顶地址是已经知道的)
3.内核栈的实现
每个进程在创建的时候都会得到一个内核栈空间,内核栈和进程的对应关系是通过2个结构体中的指针成员来完成的:
(1)struct task_struct
在学习Linux进程管理肯定要学的结构体,在内核中代表了一个进程,其中记录的进程的所有状态信息,定义在Sched.h (include\linux)。
其中有一个成员:void *stack;就是指向下面的内核栈结构体的“栈底”。
在系统运行的时候,宏current获得的就是当前进程的struct task_struct结构体。
(2)内核栈结构体union thread_union
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};其中struct thread_info是记录部分进程信息的结构体,其中包括了进程上下文信息:
/*
* low level task data that entry.S needs immediate access to.
* __switch_to() assumes cpu_context follows immediately after cpu_domain.
*/
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
struct cpu_context_save cpu_context; /* cpu context */
__u32 syscall; /* syscall number */
__u8 used_cp[16]; /* thread used copro */
unsigned long tp_value;
struct crunch_state crunchstate;
union fp_state fpstate __attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE Handler Base register */
#endif
struct restart_block restart_block;
};关键是其中的task成员,指向的是所创建的进程的struct task_struct结构体
而其中的stack成员就是内核栈。从这里可以看出内核栈空间和 thread_info是共用一块空间的。如果内核栈溢出, thread_info就会被摧毁,系统崩溃了~~~
内核栈—struct thread_info—-struct task_struct三者的关系入下图:
内核栈的产生
在进程被创建的时候,fork族的系统调用中会分别为内核栈和struct task_struct分配空间,调用过程是:
fork族的系统调用—>do_fork—>copy_process—>dup_task_struct
在dup_task_struct函数中:
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int err;
prepare_to_copy(orig);
tsk = alloc_task_struct();
if (!tsk)
return NULL;
ti = alloc_thread_info(tsk);
if (!ti) {
free_task_struct(tsk);
return NULL;
}
err = arch_dup_task_struct(tsk, orig);
if (err)
goto out;
tsk->stack = ti;
err = prop_local_init_single(&tsk->dirties);
if (err)
goto out;
setup_thread_stack(tsk, orig);
……
其中alloc_task_struct使用内核的slab分配器去为所要创建的进程分配struct task_struct的空间
而alloc_thread_info使用内核的伙伴系统去为所要创建的进程分配内核栈(union thread_union )空间
注意:
后面的tsk->stack = ti;语句,这就是关联了struct task_struct和内核栈
而在setup_thread_stack(tsk, orig);中,关联了内核栈和struct
task_struct:
static inline void setup_thread_stack(struct task_struct *p, struct task_struct *org)
{
*task_thread_info(p) = *task_thread_info(org);
task_thread_info(p)->task = p;
}内核栈的大小
由于是每一个进程都分配一个内核栈空间,所以不可能分配很大。这个大小是构架相关的,一般以页为单位。其实也就是上面我们看到的THREAD_SIZE,这个值一般为4K或者8K。对于ARM构架,这个定义在Thread_info.h (arch\arm\include\asm),
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE 8192
#define THREAD_START_SP (THREAD_SIZE - 8)所以ARM的内核栈是8KB
在(内核)驱动编程时需要注意的问题:
由于栈空间的限制,在编写的驱动(特别是被系统调用使用的底层函数)中要注意避免对栈空间消耗较大的代码,比如递归算法、局部自动变量定义的大小等等















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









